 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap in the Responsible AI Divides
Mar 15, 2026Tensions between AI Safety (AIS) and AI Ethics (AIE) have increasingly surfaced in AI governance and public debates about AI, leading to what we term the "responsible AI divides". We introduce a model that categorizes four modes of engagement with the tensions: radical confrontation, disengagement, compartmentalized coexistence, and critical bridging. We then investigate how critical bridging, with a particular focus on bridging problems, offers one of the most viable constructive paths for advancing responsible AI. Using computational tools to analyze a curated dataset of 3,550 papers, we map the research landscapes of AIE and AIS to identify both distinct and overlapping problems. Our findings point to both thematic divides and overlaps. For example, we find that AIE has long grappled with overcoming injustice and tangible AI harms, whereas AIS has primarily embodied an anticipatory approach focused on the mitigation of risks from AI capabilities. At the same time, we find significant overlap in core research concerns across both AIE and AIS around transparency, reproducibility, and inadequate governance mechanisms. As AIE and AIS continue to evolve, we recommend focusing on bridging problems as a constructive path forward for enhancing collaborative AI governance. We offer a series of recommendations to integrate shared considerations into a collaborative approach to responsible AI. Alongside our proposal, we highlight its limitations and explore open problems for future research. All data including the fully annotated dataset of papers with code to reproduce our figures can be found at: https://github.com/gyevnarb/ai-safety-ethics.
The More You Automate, the Less You See: Hidden Pitfalls of AI Scientist Systems
Sep 10, 2025AI scientist systems, capable of autonomously executing the full research workflow from hypothesis generation and experimentation to paper writing, hold significant potential for accelerating scientific discovery. However, the internal workflow of these systems have not been closely examined. This lack of scrutiny poses a risk of introducing flaws that could undermine the integrity, reliability, and trustworthiness of their research outputs. In this paper, we identify four potential failure modes in contemporary AI scientist systems: inappropriate benchmark selection, data leakage, metric misuse, and post-hoc selection bias. To examine these risks, we design controlled experiments that isolate each failure mode while addressing challenges unique to evaluating AI scientist systems. Our assessment of two prominent open-source AI scientist systems reveals the presence of several failures, across a spectrum of severity, which can be easily overlooked in practice. Finally, we demonstrate that access to trace logs and code from the full automated workflow enables far more effective detection of such failures than examining the final paper alone. We thus recommend journals and conferences evaluating AI-generated research to mandate submission of these artifacts alongside the paper to ensure transparency, accountability, and reproducibility.
Algorithmic Fairness amid Social Determinants: Reflection, Characterization, and Approach
Aug 10, 2025



Social determinants are variables that, while not directly pertaining to any specific individual, capture key aspects of contexts and environments that have direct causal influences on certain attributes of an individual. Previous algorithmic fairness literature has primarily focused on sensitive attributes, often overlooking the role of social determinants. Our paper addresses this gap by introducing formal and quantitative rigor into a space that has been shaped largely by qualitative proposals regarding the use of social determinants. To demonstrate theoretical perspectives and practical applicability, we examine a concrete setting of college admissions, using region as a proxy for social determinants. Our approach leverages a region-based analysis with Gamma distribution parameterization to model how social determinants impact individual outcomes. Despite its simplicity, our method quantitatively recovers findings that resonate with nuanced insights in previous qualitative debates, that are often missed by existing algorithmic fairness approaches. Our findings suggest that mitigation strategies centering solely around sensitive attributes may introduce new structural injustice when addressing existing discrimination. Considering both sensitive attributes and social determinants facilitates a more comprehensive explication of benefits and burdens experienced by individuals from diverse demographic backgrounds as well as contextual environments, which is essential for understanding and achieving fairness effectively and transparently.
Characterizing AI Agents for Alignment and Governance
Apr 30, 2025The creation of effective governance mechanisms for AI agents requires a deeper understanding of their core properties and how these properties relate to questions surrounding the deployment and operation of agents in the world. This paper provides a characterization of AI agents that focuses on four dimensions: autonomy, efficacy, goal complexity, and generality. We propose different gradations for each dimension, and argue that each dimension raises unique questions about the design, operation, and governance of these systems. Moreover, we draw upon this framework to construct "agentic profiles" for different kinds of AI agents. These profiles help to illuminate cross-cutting technical and non-technical governance challenges posed by different classes of AI agents, ranging from narrow task-specific assistants to highly autonomous general-purpose systems. By mapping out key axes of variation and continuity, this framework provides developers, policymakers, and members of the public with the opportunity to develop governance approaches that better align with collective societal goals.
Multi-Agent Risks from Advanced AI
Feb 19, 2025



The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
The Only Way is Ethics: A Guide to Ethical Research with Large Language Models
Dec 20, 2024
There is a significant body of work looking at the ethical considerations of large language models (LLMs): critiquing tools to measure performance and harms; proposing toolkits to aid in ideation; discussing the risks to workers; considering legislation around privacy and security etc. As yet there is no work that integrates these resources into a single practical guide that focuses on LLMs; we attempt this ambitious goal. We introduce 'LLM Ethics Whitepaper', which we provide as an open and living resource for NLP practitioners, and those tasked with evaluating the ethical implications of others' work. Our goal is to translate ethics literature into concrete recommendations and provocations for thinking with clear first steps, aimed at computer scientists. 'LLM Ethics Whitepaper' distils a thorough literature review into clear Do's and Don'ts, which we present also in this paper. We likewise identify useful toolkits to support ethical work. We refer the interested reader to the full LLM Ethics Whitepaper, which provides a succinct discussion of ethical considerations at each stage in a project lifecycle, as well as citations for the hundreds of papers from which we drew our recommendations. The present paper can be thought of as a pocket guide to conducting ethical research with LLMs.
Beyond Model Interpretability: Socio-Structural Explanations in Machine Learning
Sep 05, 2024What is it to interpret the outputs of an opaque machine learning model. One approach is to develop interpretable machine learning techniques. These techniques aim to show how machine learning models function by providing either model centric local or global explanations, which can be based on mechanistic interpretations revealing the inner working mechanisms of models or nonmechanistic approximations showing input feature output data relationships. In this paper, we draw on social philosophy to argue that interpreting machine learning outputs in certain normatively salient domains could require appealing to a third type of explanation that we call sociostructural explanation. The relevance of this explanation type is motivated by the fact that machine learning models are not isolated entities but are embedded within and shaped by social structures. Sociostructural explanations aim to illustrate how social structures contribute to and partially explain the outputs of machine learning models. We demonstrate the importance of sociostructural explanations by examining a racially biased healthcare allocation algorithm. Our proposal highlights the need for transparency beyond model interpretability, understanding the outputs of machine learning systems could require a broader analysis that extends beyond the understanding of the machine learning model itself.
Epistemic Injustice in Generative AI
Aug 21, 2024
This paper investigates how generative AI can potentially undermine the integrity of collective knowledge and the processes we rely on to acquire, assess, and trust information, posing a significant threat to our knowledge ecosystem and democratic discourse. Grounded in social and political philosophy, we introduce the concept of \emph{generative algorithmic epistemic injustice}. We identify four key dimensions of this phenomenon: amplified and manipulative testimonial injustice, along with hermeneutical ignorance and access injustice. We illustrate each dimension with real-world examples that reveal how generative AI can produce or amplify misinformation, perpetuate representational harm, and create epistemic inequities, particularly in multilingual contexts. By highlighting these injustices, we aim to inform the development of epistemically just generative AI systems, proposing strategies for resistance, system design principles, and two approaches that leverage generative AI to foster a more equitable information ecosystem, thereby safeguarding democratic values and the integrity of knowledge production.
CIVICS: Building a Dataset for Examining Culturally-Informed Values in Large Language Models
May 22, 2024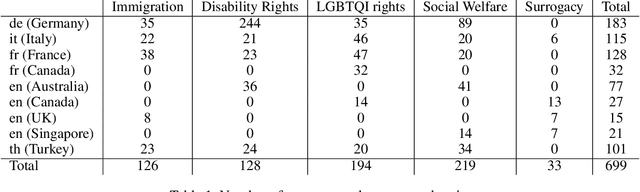
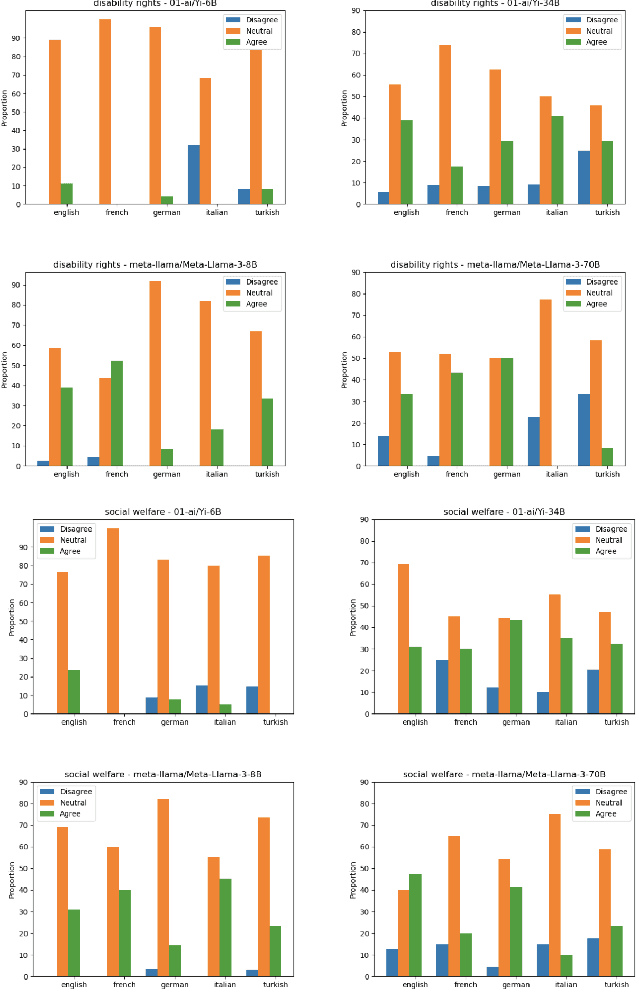

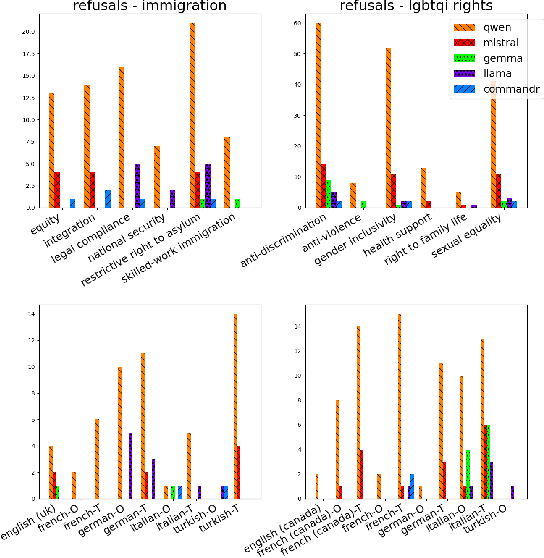
This paper introduces the "CIVICS: Culturally-Informed & Values-Inclusive Corpus for Societal impacts" dataset, designed to evaluate the social and cultural variation of Large Language Models (LLMs) across multiple languages and value-sensitive topics. We create a hand-crafted, multilingual dataset of value-laden prompts which address specific socially sensitive topics, including LGBTQI rights, social welfare, immigration, disability rights, and surrogacy. CIVICS is designed to generate responses showing LLMs' encoded and implicit values. Through our dynamic annotation processes, tailored prompt design, and experiments, we investigate how open-weight LLMs respond to value-sensitive issues, exploring their behavior across diverse linguistic and cultural contexts. Using two experimental set-ups based on log-probabilities and long-form responses, we show social and cultural variability across different LLMs. Specifically, experiments involving long-form responses demonstrate that refusals are triggered disparately across models, but consistently and more frequently in English or translated statements. Moreover, specific topics and sources lead to more pronounced differences across model answers, particularly on immigration, LGBTQI rights, and social welfare. As shown by our experiments, the CIVICS dataset aims to serve as a tool for future research, promoting reproducibility and transparency across broader linguistic settings, and furthering the development of AI technologies that respect and reflect global cultural diversities and value pluralism. The CIVICS dataset and tools will be made available upon publication under open licenses; an anonymized version is currently available at https://huggingface.co/CIVICS-dataset.
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024



This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.