 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Only Way is Ethics: A Guide to Ethical Research with Large Language Models
Dec 20, 2024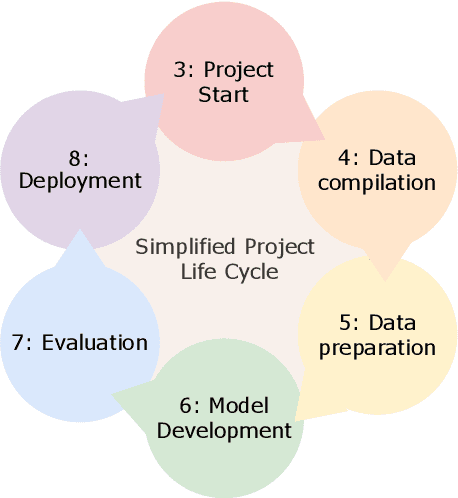
There is a significant body of work looking at the ethical considerations of large language models (LLMs): critiquing tools to measure performance and harms; proposing toolkits to aid in ideation; discussing the risks to workers; considering legislation around privacy and security etc. As yet there is no work that integrates these resources into a single practical guide that focuses on LLMs; we attempt this ambitious goal. We introduce 'LLM Ethics Whitepaper', which we provide as an open and living resource for NLP practitioners, and those tasked with evaluating the ethical implications of others' work. Our goal is to translate ethics literature into concrete recommendations and provocations for thinking with clear first steps, aimed at computer scientists. 'LLM Ethics Whitepaper' distils a thorough literature review into clear Do's and Don'ts, which we present also in this paper. We likewise identify useful toolkits to support ethical work. We refer the interested reader to the full LLM Ethics Whitepaper, which provides a succinct discussion of ethical considerations at each stage in a project lifecycle, as well as citations for the hundreds of papers from which we drew our recommendations. The present paper can be thought of as a pocket guide to conducting ethical research with LLMs.
Just Because We Camp, Doesn't Mean We Should: The Ethics of Modelling Queer Voices
Jun 11, 2024Modern voice cloning models claim to be able to capture a diverse range of voices. We test the ability of a typical pipeline to capture the style known colloquially as "gay voice" and notice a homogenisation effect: synthesised speech is rated as sounding significantly "less gay" (by LGBTQ+ participants) than its corresponding ground-truth for speakers with "gay voice", but ratings actually increase for control speakers. Loss of "gay voice" has implications for accessibility. We also find that for speakers with "gay voice", loss of "gay voice" corresponds to lower similarity ratings. However, we caution that improving the ability of such models to synthesise ``gay voice'' comes with a great number of risks. We use this pipeline as a starting point for a discussion on the ethics of modelling queer voices more broadly. Collecting "clean" queer data has safety and fairness ramifications, and the resulting technology may cause harms from mockery to death.
Stereotypes and Smut: The (Mis)representation of Non-cisgender Identities by Text-to-Image Models
May 26, 2023



Cutting-edge image generation has been praised for producing high-quality images, suggesting a ubiquitous future in a variety of applications. However, initial studies have pointed to the potential for harm due to predictive bias, reflecting and potentially reinforcing cultural stereotypes. In this work, we are the first to investigate how multimodal models handle diverse gender identities. Concretely, we conduct a thorough analysis in which we compare the output of three image generation models for prompts containing cisgender vs. non-cisgender identity terms. Our findings demonstrate that certain non-cisgender identities are consistently (mis)represented as less human, more stereotyped and more sexualised. We complement our experimental analysis with (a)~a survey among non-cisgender individuals and (b) a series of interviews, to establish which harms affected individuals anticipate, and how they would like to be represented. We find respondents are particularly concerned about misrepresentation, and the potential to drive harmful behaviours and beliefs. Simple heuristics to limit offensive content are widely rejected, and instead respondents call for community involvement, curated training data and the ability to customise. These improvements could pave the way for a future where change is led by the affected community, and technology is used to positively ``[portray] queerness in ways that we haven't even thought of'' rather than reproducing stale, offensive stereotypes.
A Robust Bias Mitigation Procedure Based on the Stereotype Content Model
Oct 26, 2022


The Stereotype Content model (SCM) states that we tend to perceive minority groups as cold, incompetent or both. In this paper we adapt existing work to demonstrate that the Stereotype Content model holds for contextualised word embeddings, then use these results to evaluate a fine-tuning process designed to drive a language model away from stereotyped portrayals of minority groups. We find the SCM terms are better able to capture bias than demographic agnostic terms related to pleasantness. Further, we were able to reduce the presence of stereotypes in the model through a simple fine-tuning procedure that required minimal human and computer resources, without harming downstream performance. We present this work as a prototype of a debiasing procedure that aims to remove the need for a priori knowledge of the specifics of bias in the model.