 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Only Way is Ethics: A Guide to Ethical Research with Large Language Models
Dec 20, 2024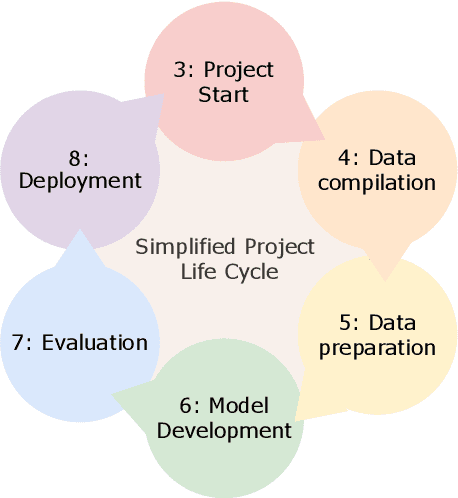
There is a significant body of work looking at the ethical considerations of large language models (LLMs): critiquing tools to measure performance and harms; proposing toolkits to aid in ideation; discussing the risks to workers; considering legislation around privacy and security etc. As yet there is no work that integrates these resources into a single practical guide that focuses on LLMs; we attempt this ambitious goal. We introduce 'LLM Ethics Whitepaper', which we provide as an open and living resource for NLP practitioners, and those tasked with evaluating the ethical implications of others' work. Our goal is to translate ethics literature into concrete recommendations and provocations for thinking with clear first steps, aimed at computer scientists. 'LLM Ethics Whitepaper' distils a thorough literature review into clear Do's and Don'ts, which we present also in this paper. We likewise identify useful toolkits to support ethical work. We refer the interested reader to the full LLM Ethics Whitepaper, which provides a succinct discussion of ethical considerations at each stage in a project lifecycle, as well as citations for the hundreds of papers from which we drew our recommendations. The present paper can be thought of as a pocket guide to conducting ethical research with LLMs.
CROPE: Evaluating In-Context Adaptation of Vision and Language Models to Culture-Specific Concepts
Oct 20, 2024As Vision and Language models (VLMs) become accessible across the globe, it is important that they demonstrate cultural knowledge. In this paper, we introduce CROPE, a visual question answering benchmark designed to probe the knowledge of culture-specific concepts and evaluate the capacity for cultural adaptation through contextual information. This allows us to distinguish between parametric knowledge acquired during training and contextual knowledge provided during inference via visual and textual descriptions. Our evaluation of several state-of-the-art open VLMs shows large performance disparities between culture-specific and common concepts in the parametric setting. Moreover, experiments with contextual knowledge indicate that models struggle to effectively utilize multimodal information and bind culture-specific concepts to their depictions. Our findings reveal limitations in the cultural understanding and adaptability of current VLMs that need to be addressed toward more culturally inclusive models.
Re-examining Sexism and Misogyny Classification with Annotator Attitudes
Oct 04, 2024



Gender-Based Violence (GBV) is an increasing problem online, but existing datasets fail to capture the plurality of possible annotator perspectives or ensure the representation of affected groups. We revisit two important stages in the moderation pipeline for GBV: (1) manual data labelling; and (2) automated classification. For (1), we examine two datasets to investigate the relationship between annotator identities and attitudes and the responses they give to two GBV labelling tasks. To this end, we collect demographic and attitudinal information from crowd-sourced annotators using three validated surveys from Social Psychology. We find that higher Right Wing Authoritarianism scores are associated with a higher propensity to label text as sexist, while for Social Dominance Orientation and Neosexist Attitudes, higher scores are associated with a negative tendency to do so. For (2), we conduct classification experiments using Large Language Models and five prompting strategies, including infusing prompts with annotator information. We find: (i) annotator attitudes affect the ability of classifiers to predict their labels; (ii) including attitudinal information can boost performance when we use well-structured brief annotator descriptions; and (iii) models struggle to reflect the increased complexity and imbalanced classes of the new label sets.
Voices in a Crowd: Searching for Clusters of Unique Perspectives
Jul 19, 2024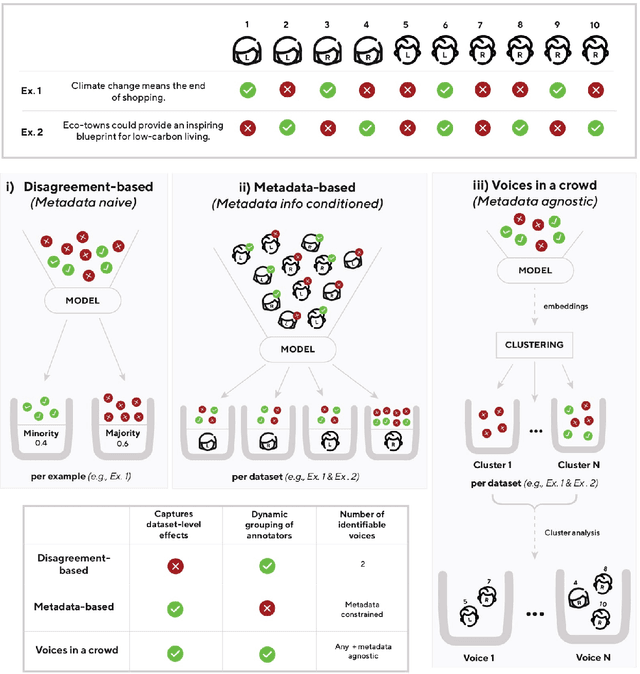
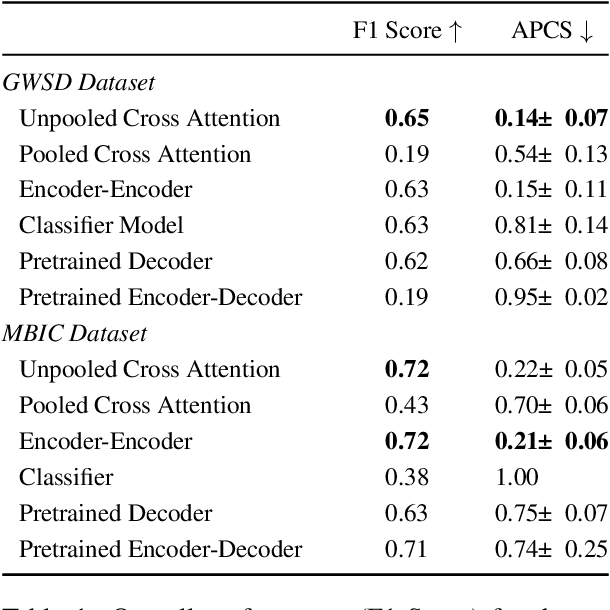
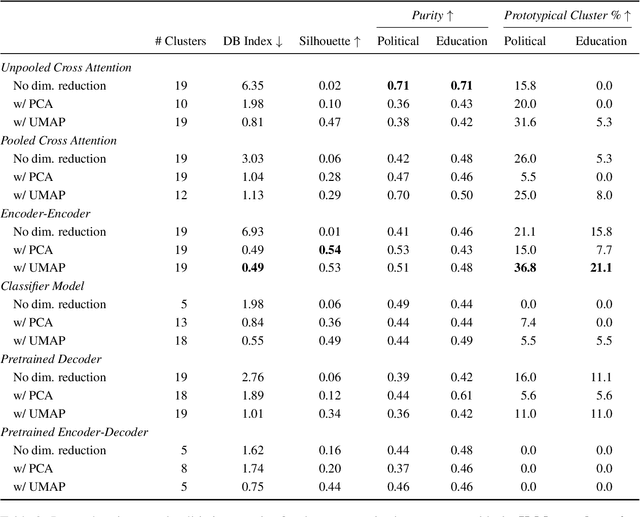
Language models have been shown to reproduce underlying biases existing in their training data, which is the majority perspective by default. Proposed solutions aim to capture minority perspectives by either modelling annotator disagreements or grouping annotators based on shared metadata, both of which face significant challenges. We propose a framework that trains models without encoding annotator metadata, extracts latent embeddings informed by annotator behaviour, and creates clusters of similar opinions, that we refer to as voices. Resulting clusters are validated post-hoc via internal and external quantitative metrics, as well a qualitative analysis to identify the type of voice that each cluster represents. Our results demonstrate the strong generalisation capability of our framework, indicated by resulting clusters being adequately robust, while also capturing minority perspectives based on different demographic factors throughout two distinct datasets.
Investigating the Role of Instruction Variety and Task Difficulty in Robotic Manipulation Tasks
Jul 04, 2024

Evaluating the generalisation capabilities of multimodal models based solely on their performance on out-of-distribution data fails to capture their true robustness. This work introduces a comprehensive evaluation framework that systematically examines the role of instructions and inputs in the generalisation abilities of such models, considering architectural design, input perturbations across language and vision modalities, and increased task complexity. The proposed framework uncovers the resilience of multimodal models to extreme instruction perturbations and their vulnerability to observational changes, raising concerns about overfitting to spurious correlations. By employing this evaluation framework on current Transformer-based multimodal models for robotic manipulation tasks, we uncover limitations and suggest future advancements should focus on architectural and training innovations that better integrate multimodal inputs, enhancing a model's generalisation prowess by prioritising sensitivity to input content over incidental correlations.
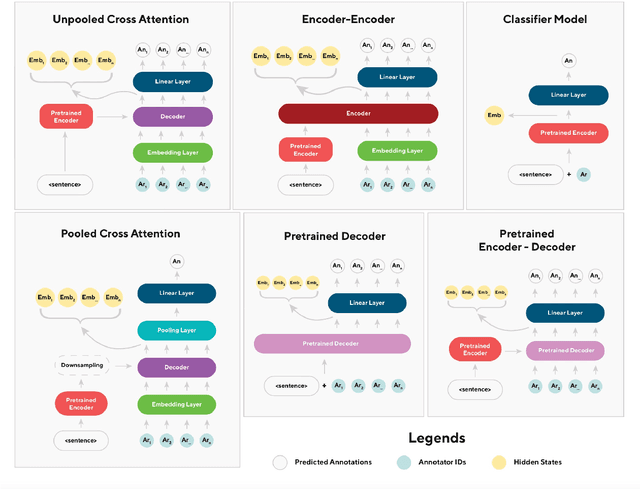
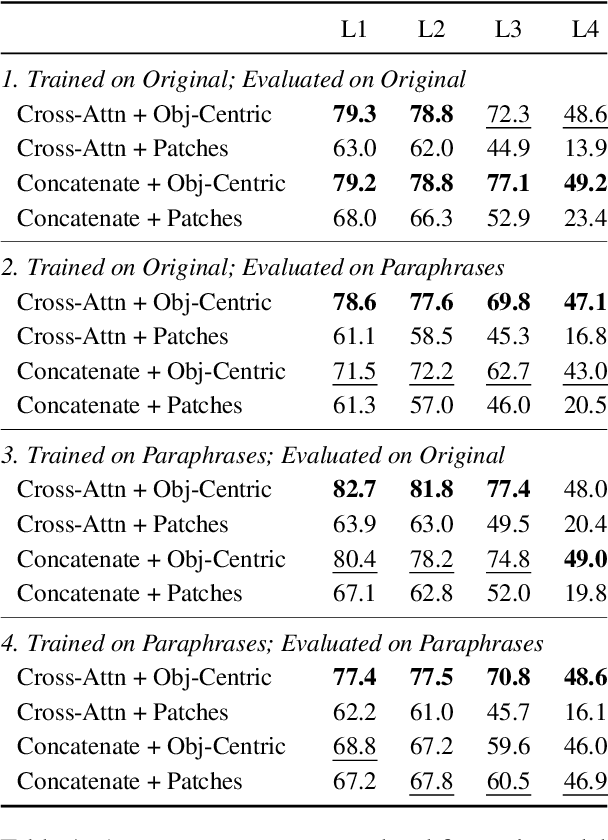
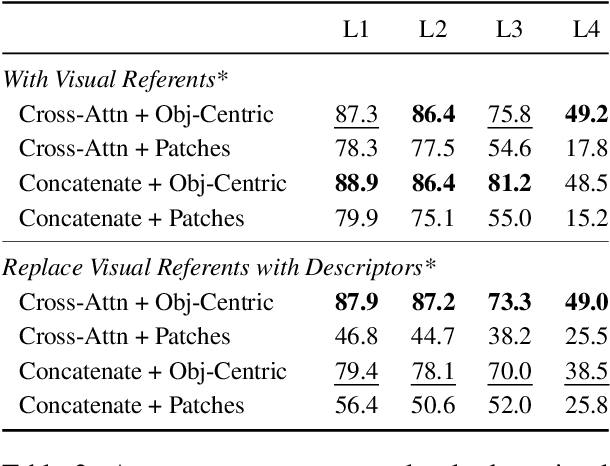
iLab at SemEval-2023 Task 11 Le-Wi-Di: Modelling Disagreement or Modelling Perspectives?
May 10, 2023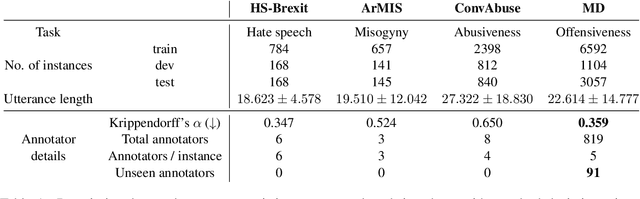
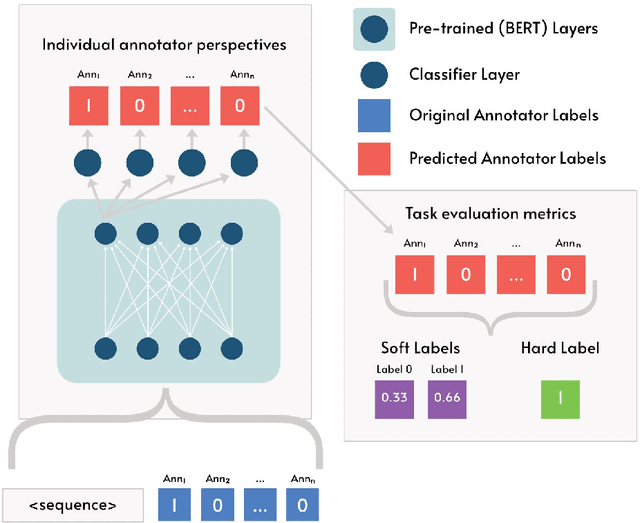
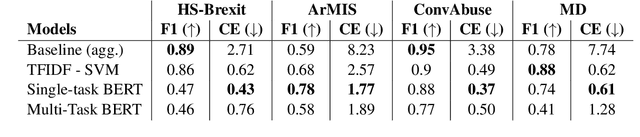
There are two competing approaches for modelling annotator disagreement: distributional soft-labelling approaches (which aim to capture the level of disagreement) or modelling perspectives of individual annotators or groups thereof. We adapt a multi-task architecture -- which has previously shown success in modelling perspectives -- to evaluate its performance on the SEMEVAL Task 11. We do so by combining both approaches, i.e. predicting individual annotator perspectives as an interim step towards predicting annotator disagreement. Despite its previous success, we found that a multi-task approach performed poorly on datasets which contained distinct annotator opinions, suggesting that this approach may not always be suitable when modelling perspectives. Furthermore, our results explain that while strongly perspectivist approaches might not achieve state-of-the-art performance according to evaluation metrics used by distributional approaches, our approach allows for a more nuanced understanding of individual perspectives present in the data. We argue that perspectivist approaches are preferable because they enable decision makers to amplify minority views, and that it is important to re-evaluate metrics to reflect this goal.