 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan NLP Tackle Hate Speech in the Real World? Stakeholder-Informed Feedback and Survey on Counterspeech
Aug 06, 2025Counterspeech, i.e. the practice of responding to online hate speech, has gained traction in NLP as a promising intervention. While early work emphasised collaboration with non-governmental organisation stakeholders, recent research trends have shifted toward automated pipelines that reuse a small set of legacy datasets, often without input from affected communities. This paper presents a systematic review of 74 NLP studies on counterspeech, analysing the extent to which stakeholder participation influences dataset creation, model development, and evaluation. To complement this analysis, we conducted a participatory case study with five NGOs specialising in online Gender-Based Violence (oGBV), identifying stakeholder-informed practices for counterspeech generation. Our findings reveal a growing disconnect between current NLP research and the needs of communities most impacted by toxic online content. We conclude with concrete recommendations for re-centring stakeholder expertise in counterspeech research.
Re-examining Sexism and Misogyny Classification with Annotator Attitudes
Oct 04, 2024



Gender-Based Violence (GBV) is an increasing problem online, but existing datasets fail to capture the plurality of possible annotator perspectives or ensure the representation of affected groups. We revisit two important stages in the moderation pipeline for GBV: (1) manual data labelling; and (2) automated classification. For (1), we examine two datasets to investigate the relationship between annotator identities and attitudes and the responses they give to two GBV labelling tasks. To this end, we collect demographic and attitudinal information from crowd-sourced annotators using three validated surveys from Social Psychology. We find that higher Right Wing Authoritarianism scores are associated with a higher propensity to label text as sexist, while for Social Dominance Orientation and Neosexist Attitudes, higher scores are associated with a negative tendency to do so. For (2), we conduct classification experiments using Large Language Models and five prompting strategies, including infusing prompts with annotator information. We find: (i) annotator attitudes affect the ability of classifiers to predict their labels; (ii) including attitudinal information can boost performance when we use well-structured brief annotator descriptions; and (iii) models struggle to reflect the increased complexity and imbalanced classes of the new label sets.
Cross-lingual Offensive Language Detection: A Systematic Review of Datasets, Transfer Approaches and Challenges
Jan 17, 2024The growing prevalence and rapid evolution of offensive language in social media amplify the complexities of detection, particularly highlighting the challenges in identifying such content across diverse languages. This survey presents a systematic and comprehensive exploration of Cross-Lingual Transfer Learning (CLTL) techniques in offensive language detection in social media. Our study stands as the first holistic overview to focus exclusively on the cross-lingual scenario in this domain. We analyse 67 relevant papers and categorise these studies across various dimensions, including the characteristics of multilingual datasets used, the cross-lingual resources employed, and the specific CLTL strategies implemented. According to "what to transfer", we also summarise three main CLTL transfer approaches: instance, feature, and parameter transfer. Additionally, we shed light on the current challenges and future research opportunities in this field. Furthermore, we have made our survey resources available online, including two comprehensive tables that provide accessible references to the multilingual datasets and CLTL methods used in the reviewed literature.
AnnoBERT: Effectively Representing Multiple Annotators' Label Choices to Improve Hate Speech Detection
Jan 10, 2023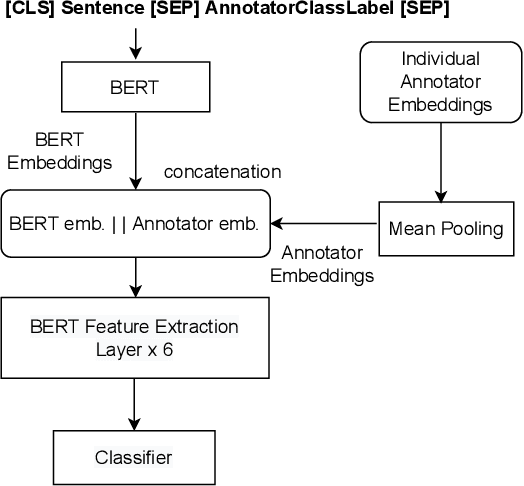

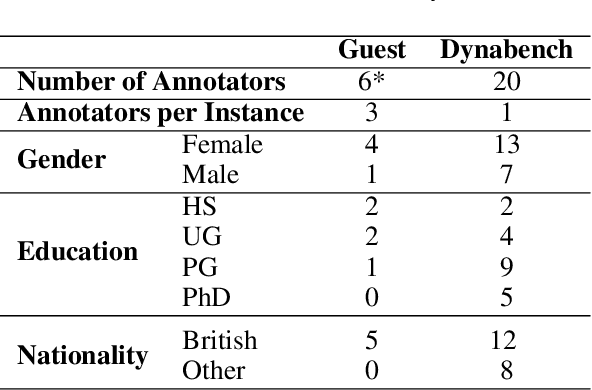
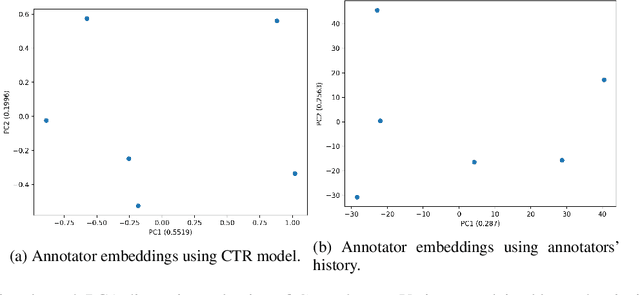
Supervised approaches generally rely on majority-based labels. However, it is hard to achieve high agreement among annotators in subjective tasks such as hate speech detection. Existing neural network models principally regard labels as categorical variables, while ignoring the semantic information in diverse label texts. In this paper, we propose AnnoBERT, a first-of-its-kind architecture integrating annotator characteristics and label text with a transformer-based model to detect hate speech, with unique representations based on each annotator's characteristics via Collaborative Topic Regression (CTR) and integrate label text to enrich textual representations. During training, the model associates annotators with their label choices given a piece of text; during evaluation, when label information is not available, the model predicts the aggregated label given by the participating annotators by utilising the learnt association. The proposed approach displayed an advantage in detecting hate speech, especially in the minority class and edge cases with annotator disagreement. Improvement in the overall performance is the largest when the dataset is more label-imbalanced, suggesting its practical value in identifying real-world hate speech, as the volume of hate speech in-the-wild is extremely small on social media, when compared with normal (non-hate) speech. Through ablation studies, we show the relative contributions of annotator embeddings and label text to the model performance, and tested a range of alternative annotator embeddings and label text combinations.
* accepted at ICWSM 2023
SexWEs: Domain-Aware Word Embeddings via Cross-lingual Semantic Specialisation for Chinese Sexism Detection in Social Media
Nov 17, 2022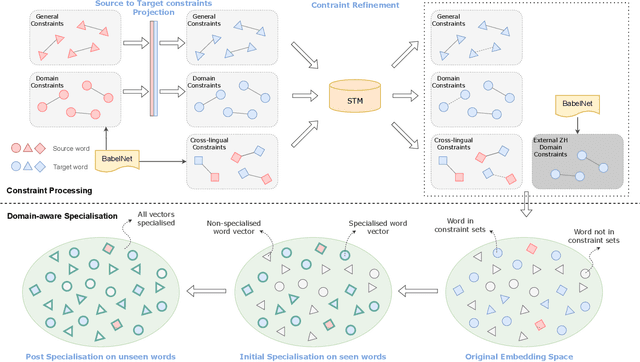



The goal of sexism detection is to mitigate negative online content targeting certain gender groups of people. However, the limited availability of labeled sexism-related datasets makes it problematic to identify online sexism for low-resource languages. In this paper, we address the task of automatic sexism detection in social media for one low-resource language -- Chinese. Rather than collecting new sexism data or building cross-lingual transfer learning models, we develop a cross-lingual domain-aware semantic specialisation system in order to make the most of existing data. Semantic specialisation is a technique for retrofitting pre-trained distributional word vectors by integrating external linguistic knowledge (such as lexico-semantic relations) into the specialised feature space. To do this, we leverage semantic resources for sexism from a high-resource language (English) to specialise pre-trained word vectors in the target language (Chinese) to inject domain knowledge. We demonstrate the benefit of our sexist word embeddings (SexWEs) specialised by our framework via intrinsic evaluation of word similarity and extrinsic evaluation of sexism detection. Compared with other specialisation approaches and Chinese baseline word vectors, our SexWEs shows an average score improvement of 0.033 and 0.064 in both intrinsic and extrinsic evaluations, respectively. The ablative results and visualisation of SexWEs also prove the effectiveness of our framework on retrofitting word vectors in low-resource languages. Our code and sexism-related word vectors will be publicly available.
Cross-lingual Capsule Network for Hate Speech Detection in Social Media
Aug 06, 2021



Most hate speech detection research focuses on a single language, generally English, which limits their generalisability to other languages. In this paper we investigate the cross-lingual hate speech detection task, tackling the problem by adapting the hate speech resources from one language to another. We propose a cross-lingual capsule network learning model coupled with extra domain-specific lexical semantics for hate speech (CCNL-Ex). Our model achieves state-of-the-art performance on benchmark datasets from AMI@Evalita2018 and AMI@Ibereval2018 involving three languages: English, Spanish and Italian, outperforming state-of-the-art baselines on all six language pairs.
SWSR: A Chinese Dataset and Lexicon for Online Sexism Detection
Aug 06, 2021
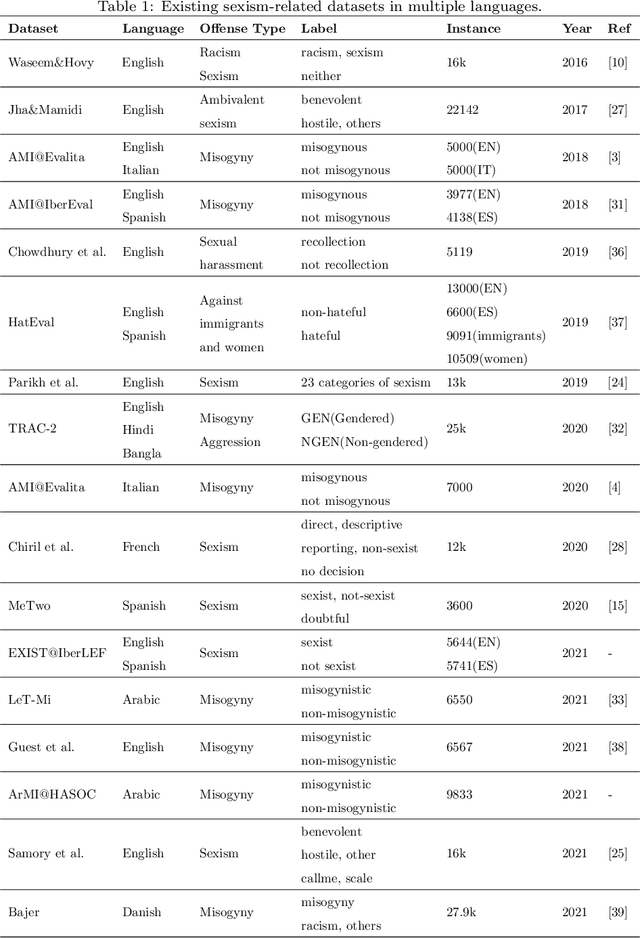
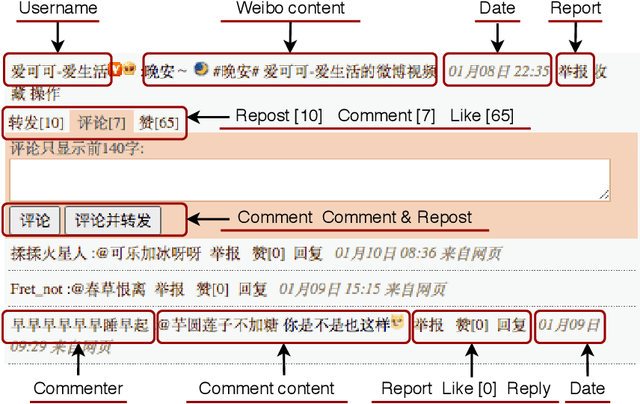
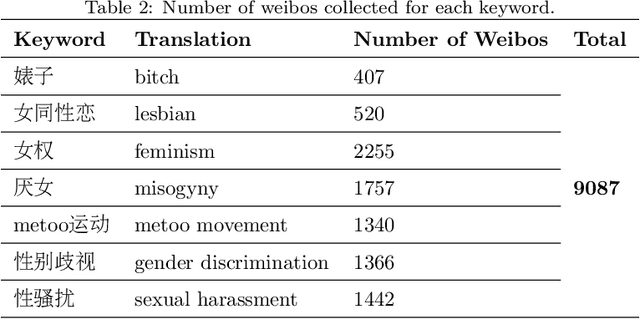
Online sexism has become an increasing concern in social media platforms as it has affected the healthy development of the Internet and can have negative effects in society. While research in the sexism detection domain is growing, most of this research focuses on English as the language and on Twitter as the platform. Our objective here is to broaden the scope of this research by considering the Chinese language on Sina Weibo. We propose the first Chinese sexism dataset -- Sina Weibo Sexism Review (SWSR) dataset --, as well as a large Chinese lexicon SexHateLex made of abusive and gender-related terms. We introduce our data collection and annotation process, and provide an exploratory analysis of the dataset characteristics to validate its quality and to show how sexism is manifested in Chinese. The SWSR dataset provides labels at different levels of granularity including (i) sexism or non-sexism, (ii) sexism category and (iii) target type, which can be exploited, among others, for building computational methods to identify and investigate finer-grained gender-related abusive language. We conduct experiments for the three sexism classification tasks making use of state-of-the-art machine learning models. Our results show competitive performance, providing a benchmark for sexism detection in the Chinese language, as well as an error analysis highlighting open challenges needing more research in Chinese NLP. The SWSR dataset and SexHateLex lexicon are publicly available.
Leveraging Aspect Phrase Embeddings for Cross-Domain Review Rating Prediction
Nov 14, 2018



Online review platforms are a popular way for users to post reviews by expressing their opinions towards a product or service, as well as they are valuable for other users and companies to find out the overall opinions of customers. These reviews tend to be accompanied by a rating, where the star rating has become the most common approach for users to give their feedback in a quantitative way, generally as a likert scale of 1-5 stars. In other social media platforms like Facebook or Twitter, an automated review rating prediction system can be useful to determine the rating that a user would have given to the product or service. Existing work on review rating prediction focuses on specific domains, such as restaurants or hotels. This, however, ignores the fact that some review domains which are less frequently rated, such as dentists, lack sufficient data to build a reliable prediction model. In this paper, we experiment on 12 datasets pertaining to 12 different review domains of varying level of popularity to assess the performance of predictions across different domains. We introduce a model that leverages aspect phrase embeddings extracted from the reviews, which enables the development of both in-domain and cross-domain review rating prediction systems. Our experiments show that both of our review rating prediction systems outperform all other baselines. The cross-domain review rating prediction system is particularly significant for the least popular review domains, where leveraging training data from other domains leads to remarkable improvements in performance. The in-domain review rating prediction system is instead more suitable for popular review domains, provided that a model built from training data pertaining to the target domain is more suitable when this data is abundant.