 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSSC: Shared Supervised-Contrastive Federated Learning
Jan 14, 2023Federated learning is widely used to perform decentralized training of a global model on multiple devices while preserving the data privacy of each device. However, it suffers from heterogeneous local data on each training device which increases the difficulty to reach the same level of accuracy as the centralized training. Supervised Contrastive Learning which outperform cross-entropy tries to minimizes the difference between feature space of points belongs to the same class and pushes away points from different classes. We propose Supervised Contrastive Federated Learning in which devices can share the learned class-wise feature spaces with each other and add the supervised-contrastive learning loss as a regularization term to foster the feature space learning. The loss tries to minimize the cosine similarity distance between the feature map and the averaged feature map from another device in the same class and maximizes the distance between the feature map and that in a different class. This new regularization term when added on top of the moon regularization term is found to outperform the other state-of-the-art regularization terms in solving the heterogeneous data distribution problem.
What GPT Knows About Who is Who
May 16, 2022



Coreference resolution -- which is a crucial task for understanding discourse and language at large -- has yet to witness widespread benefits from large language models (LLMs). Moreover, coreference resolution systems largely rely on supervised labels, which are highly expensive and difficult to annotate, thus making it ripe for prompt engineering. In this paper, we introduce a QA-based prompt-engineering method and discern \textit{generative}, pre-trained LLMs' abilities and limitations toward the task of coreference resolution. Our experiments show that GPT-2 and GPT-Neo can return valid answers, but that their capabilities to identify coreferent mentions are limited and prompt-sensitive, leading to inconsistent results.
SWSR: A Chinese Dataset and Lexicon for Online Sexism Detection
Aug 06, 2021
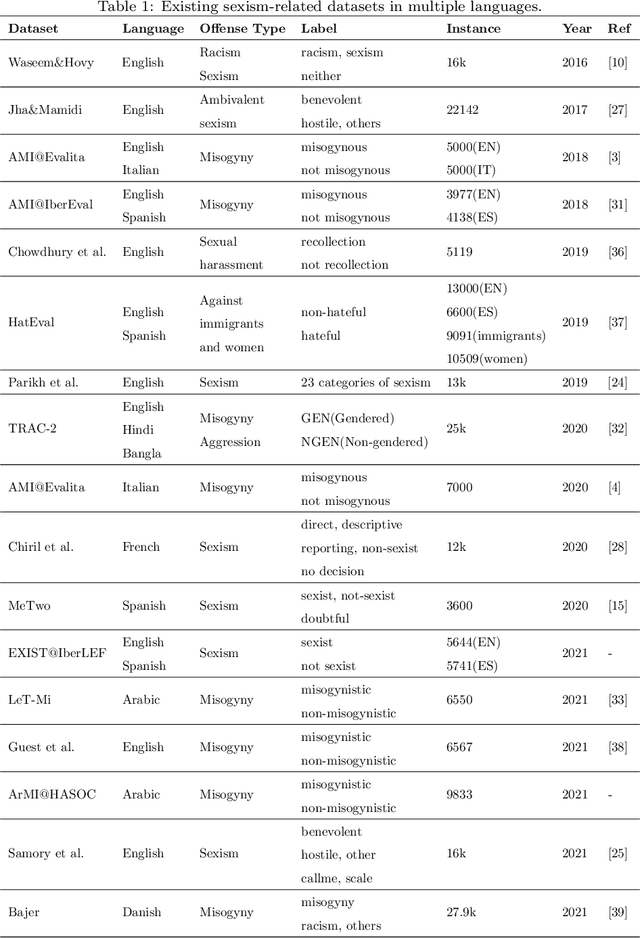
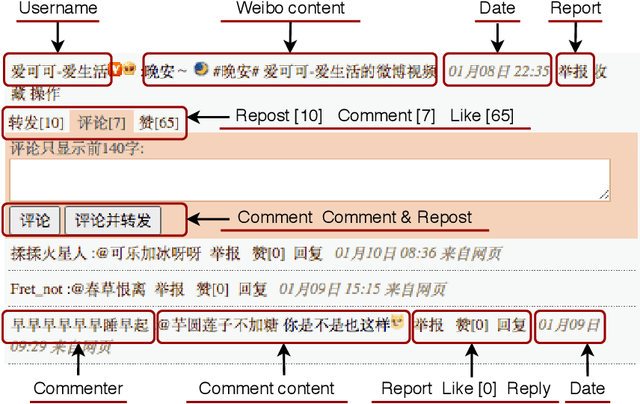
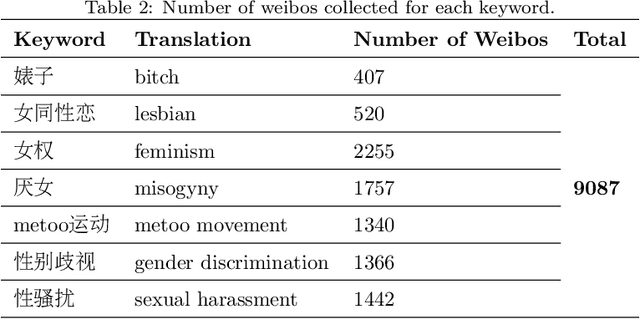
Online sexism has become an increasing concern in social media platforms as it has affected the healthy development of the Internet and can have negative effects in society. While research in the sexism detection domain is growing, most of this research focuses on English as the language and on Twitter as the platform. Our objective here is to broaden the scope of this research by considering the Chinese language on Sina Weibo. We propose the first Chinese sexism dataset -- Sina Weibo Sexism Review (SWSR) dataset --, as well as a large Chinese lexicon SexHateLex made of abusive and gender-related terms. We introduce our data collection and annotation process, and provide an exploratory analysis of the dataset characteristics to validate its quality and to show how sexism is manifested in Chinese. The SWSR dataset provides labels at different levels of granularity including (i) sexism or non-sexism, (ii) sexism category and (iii) target type, which can be exploited, among others, for building computational methods to identify and investigate finer-grained gender-related abusive language. We conduct experiments for the three sexism classification tasks making use of state-of-the-art machine learning models. Our results show competitive performance, providing a benchmark for sexism detection in the Chinese language, as well as an error analysis highlighting open challenges needing more research in Chinese NLP. The SWSR dataset and SexHateLex lexicon are publicly available.
Cuid: A new study of perceived image quality and its subjective assessment
Sep 28, 2020


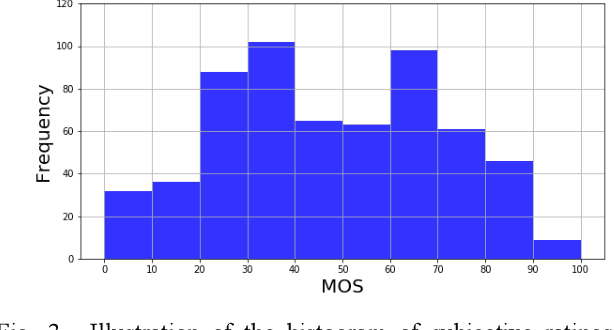
Research on image quality assessment (IQA) remains limited mainly due to our incomplete knowledge about human visual perception. Existing IQA algorithms have been designed or trained with insufficient subjective data with a small degree of stimulus variability. This has led to challenges for those algorithms to handle complexity and diversity of real-world digital content. Perceptual evidence from human subjects serves as a grounding for the development of advanced IQA algorithms. It is thus critical to acquire reliable subjective data with controlled perception experiments that faithfully reflect human behavioural responses to distortions in visual signals. In this paper, we present a new study of image quality perception where subjective ratings were collected in a controlled lab environment. We investigate how quality perception is affected by a combination of different categories of images and different types and levels of distortions. The database will be made publicly available to facilitate calibration and validation of IQA algorithms.
A Concert-planning Tool for Independent Musicians by Machine Learning Models
Aug 29, 2019

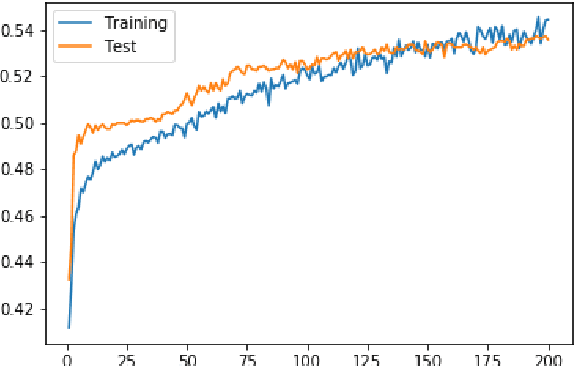
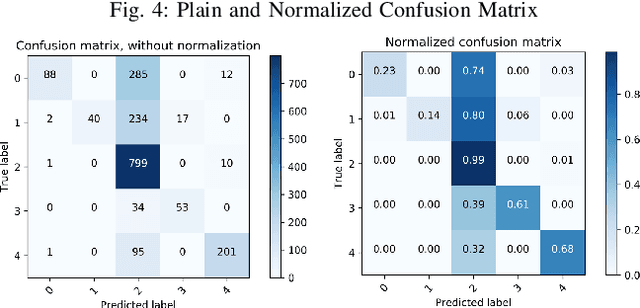
Our project aims at helping independent musicians to plan their concerts based on the economies of agglomeration in the music industry. Initially, we planned to design an advisory tool for both concert pricing and location selection. Nonetheless, after implementing SGD linear regression and support vector regression models, we realized that concert price does not vary significantly according to different music types, concert time, concert location and ticket venues. Therefore, to offer more useful suggestions, we focus on the location choice problem by turning it to a classification task. The overall performance of our classification model is pretty good. After tuning hyperparameters, we discovered the Random Forest gives the best performance, improving the classification result by 316%. This result reveals that we could help independent musicians better locate their concerts to where similar musicians would go, namely a place with higher network effects.