 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving math word problems with process- and outcome-based feedback
Nov 25, 2022



Recent work has shown that asking language models to generate reasoning steps improves performance on many reasoning tasks. When moving beyond prompting, this raises the question of how we should supervise such models: outcome-based approaches which supervise the final result, or process-based approaches which supervise the reasoning process itself? Differences between these approaches might naturally be expected not just in final-answer errors but also in reasoning errors, which can be difficult to detect and are problematic in many real-world domains such as education. We run the first comprehensive comparison between process- and outcome-based approaches trained on a natural language task, GSM8K. We find that pure outcome-based supervision produces similar final-answer error rates with less label supervision. However, for correct reasoning steps we find it necessary to use process-based supervision or supervision from learned reward models that emulate process-based feedback. In total, we improve the previous best results from 16.8% $\to$ 12.7% final-answer error and 14.0% $\to$ 3.4% reasoning error among final-answer-correct solutions.
Selection-Inference: Exploiting Large Language Models for Interpretable Logical Reasoning
May 19, 2022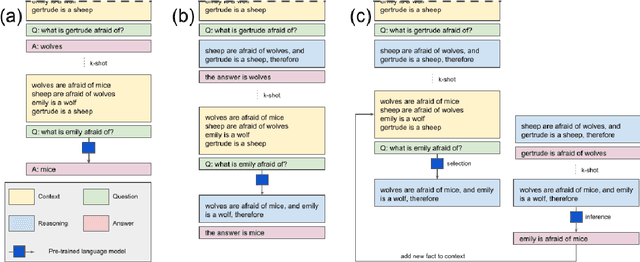

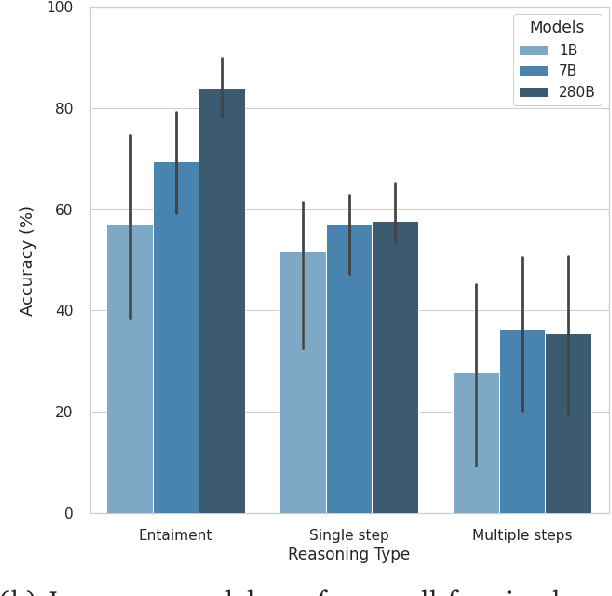
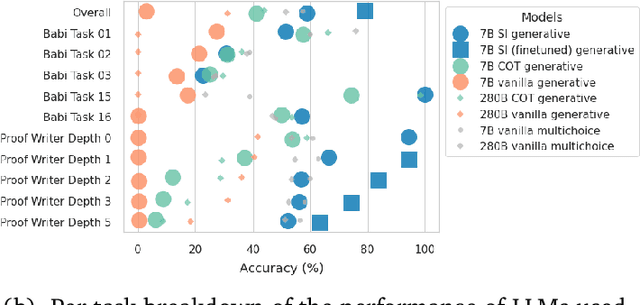
Large language models (LLMs) have been shown to be capable of impressive few-shot generalisation to new tasks. However, they still tend to perform poorly on multi-step logical reasoning problems. Here we carry out a comprehensive evaluation of LLMs on 50 tasks that probe different aspects of logical reasoning. We show that language models tend to perform fairly well at single step inference or entailment tasks, but struggle to chain together multiple reasoning steps to solve more complex problems. In light of this, we propose a Selection-Inference (SI) framework that exploits pre-trained LLMs as general processing modules, and alternates between selection and inference to generate a series of interpretable, casual reasoning steps leading to the final answer. We show that a 7B parameter LLM used within the SI framework in a 5-shot generalisation setting, with no fine-tuning, yields a performance improvement of over 100% compared to an equivalent vanilla baseline on a suite of 10 logical reasoning tasks. The same model in the same setting even outperforms a significantly larger 280B parameter baseline on the same suite of tasks. Moreover, answers produced by the SI framework are accompanied by a causal natural-language-based reasoning trace, which has important implications for the safety and trustworthiness of the system.
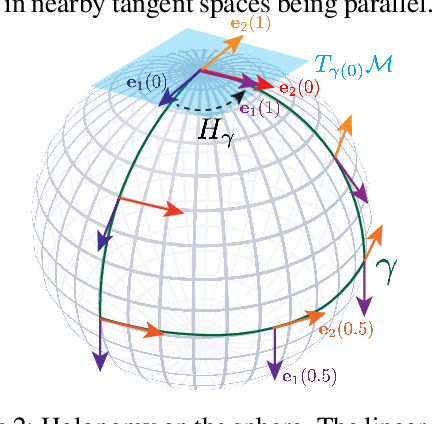
Symmetry-Based Representations for Artificial and Biological General Intelligence
Mar 17, 2022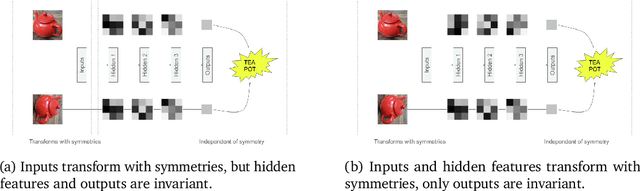
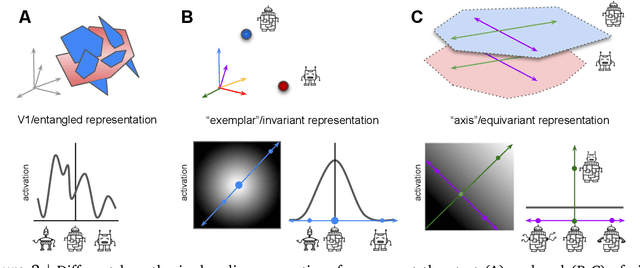
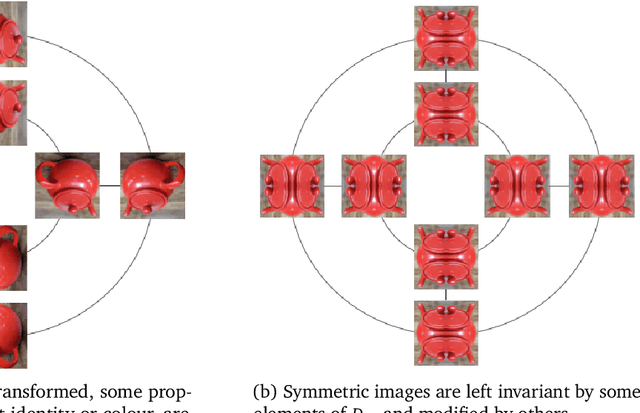
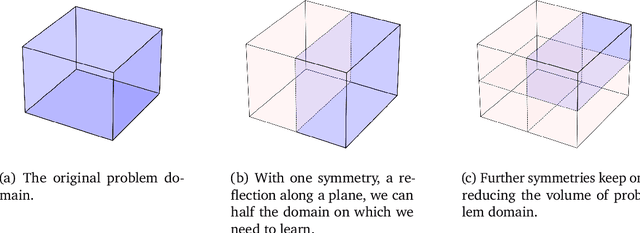
Biological intelligence is remarkable in its ability to produce complex behaviour in many diverse situations through data efficient, generalisable and transferable skill acquisition. It is believed that learning "good" sensory representations is important for enabling this, however there is little agreement as to what a good representation should look like. In this review article we are going to argue that symmetry transformations are a fundamental principle that can guide our search for what makes a good representation. The idea that there exist transformations (symmetries) that affect some aspects of the system but not others, and their relationship to conserved quantities has become central in modern physics, resulting in a more unified theoretical framework and even ability to predict the existence of new particles. Recently, symmetries have started to gain prominence in machine learning too, resulting in more data efficient and generalisable algorithms that can mimic some of the complex behaviours produced by biological intelligence. Finally, first demonstrations of the importance of symmetry transformations for representation learning in the brain are starting to arise in neuroscience. Taken together, the overwhelming positive effect that symmetries bring to these disciplines suggest that they may be an important general framework that determines the structure of the universe, constrains the nature of natural tasks and consequently shapes both biological and artificial intelligence.
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Dec 08, 2021



Language modelling provides a step towards intelligent communication systems by harnessing large repositories of written human knowledge to better predict and understand the world. In this paper, we present an analysis of Transformer-based language model performance across a wide range of model scales -- from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models are evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority. Gains from scale are largest in areas such as reading comprehension, fact-checking, and the identification of toxic language, but logical and mathematical reasoning see less benefit. We provide a holistic analysis of the training dataset and model's behaviour, covering the intersection of model scale with bias and toxicity. Finally we discuss the application of language models to AI safety and the mitigation of downstream harms.
SyMetric: Measuring the Quality of Learnt Hamiltonian Dynamics Inferred from Vision
Nov 10, 2021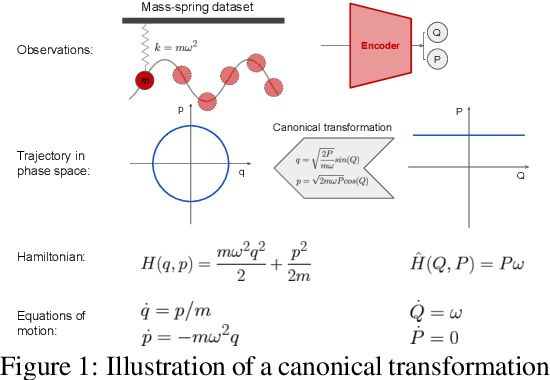
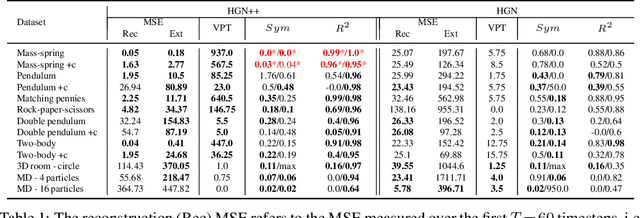
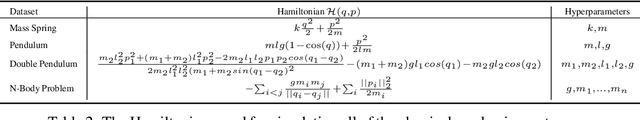
A recently proposed class of models attempts to learn latent dynamics from high-dimensional observations, like images, using priors informed by Hamiltonian mechanics. While these models have important potential applications in areas like robotics or autonomous driving, there is currently no good way to evaluate their performance: existing methods primarily rely on image reconstruction quality, which does not always reflect the quality of the learnt latent dynamics. In this work, we empirically highlight the problems with the existing measures and develop a set of new measures, including a binary indicator of whether the underlying Hamiltonian dynamics have been faithfully captured, which we call Symplecticity Metric or SyMetric. Our measures take advantage of the known properties of Hamiltonian dynamics and are more discriminative of the model's ability to capture the underlying dynamics than reconstruction error. Using SyMetric, we identify a set of architectural choices that significantly improve the performance of a previously proposed model for inferring latent dynamics from pixels, the Hamiltonian Generative Network (HGN). Unlike the original HGN, the new HGN++ is able to discover an interpretable phase space with physically meaningful latents on some datasets. Furthermore, it is stable for significantly longer rollouts on a diverse range of 13 datasets, producing rollouts of essentially infinite length both forward and backwards in time with no degradation in quality on a subset of the datasets.
Which priors matter? Benchmarking models for learning latent dynamics
Nov 09, 2021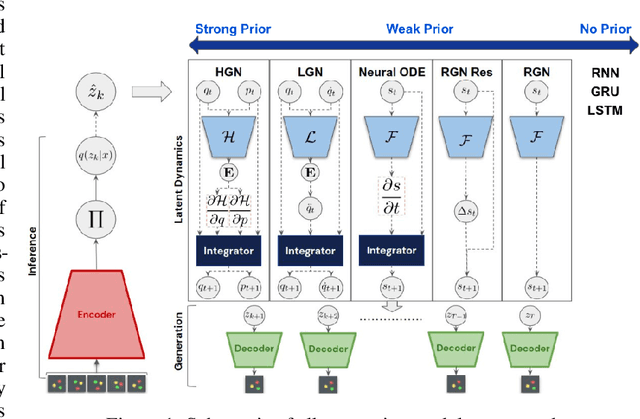
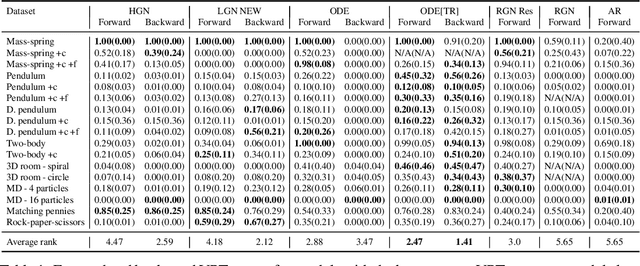
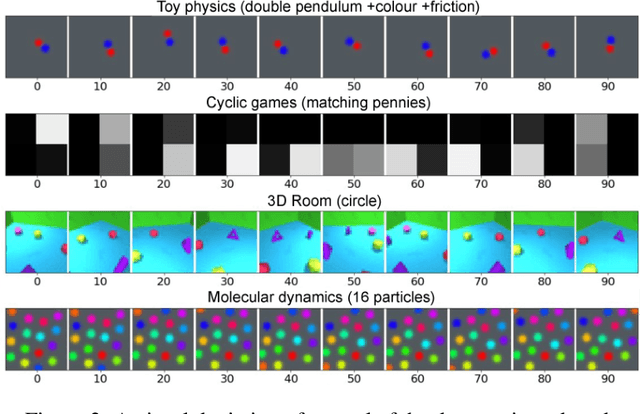
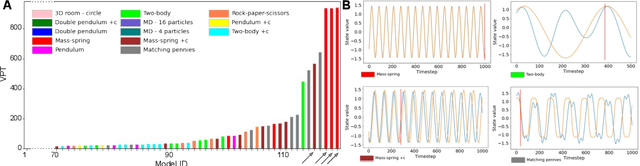
Learning dynamics is at the heart of many important applications of machine learning (ML), such as robotics and autonomous driving. In these settings, ML algorithms typically need to reason about a physical system using high dimensional observations, such as images, without access to the underlying state. Recently, several methods have proposed to integrate priors from classical mechanics into ML models to address the challenge of physical reasoning from images. In this work, we take a sober look at the current capabilities of these models. To this end, we introduce a suite consisting of 17 datasets with visual observations based on physical systems exhibiting a wide range of dynamics. We conduct a thorough and detailed comparison of the major classes of physically inspired methods alongside several strong baselines. While models that incorporate physical priors can often learn latent spaces with desirable properties, our results demonstrate that these methods fail to significantly improve upon standard techniques. Nonetheless, we find that the use of continuous and time-reversible dynamics benefits models of all classes.
Representation Matters: Improving Perception and Exploration for Robotics
Nov 03, 2020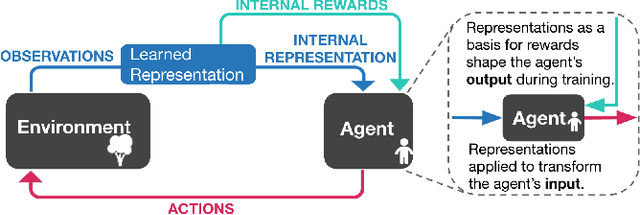
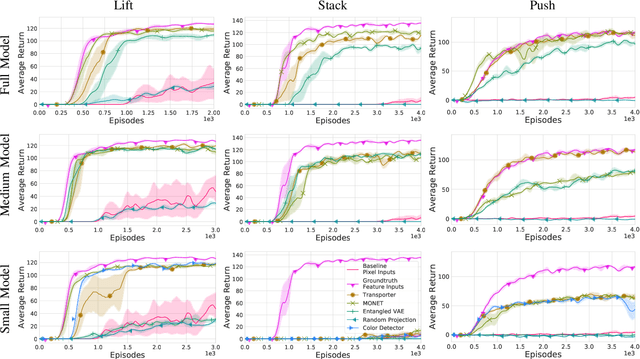

Projecting high-dimensional environment observations into lower-dimensional structured representations can considerably improve data-efficiency for reinforcement learning in domains with limited data such as robotics. Can a single generally useful representation be found? In order to answer this question, it is important to understand how the representation will be used by the agent and what properties such a 'good' representation should have. In this paper we systematically evaluate a number of common learnt and hand-engineered representations in the context of three robotics tasks: lifting, stacking and pushing of 3D blocks. The representations are evaluated in two use-cases: as input to the agent, or as a source of auxiliary tasks. Furthermore, the value of each representation is evaluated in terms of three properties: dimensionality, observability and disentanglement. We can significantly improve performance in both use-cases and demonstrate that some representations can perform commensurate to simulator states as agent inputs. Finally, our results challenge common intuitions by demonstrating that: 1) dimensionality strongly matters for task generation, but is negligible for inputs, 2) observability of task-relevant aspects mostly affects the input representation use-case, and 3) disentanglement leads to better auxiliary tasks, but has only limited benefits for input representations. This work serves as a step towards a more systematic understanding of what makes a 'good' representation for control in robotics, enabling practitioners to make more informed choices for developing new learned or hand-engineered representations.
Representation learning for improved interpretability and classification accuracy of clinical factors from EEG
Oct 30, 2020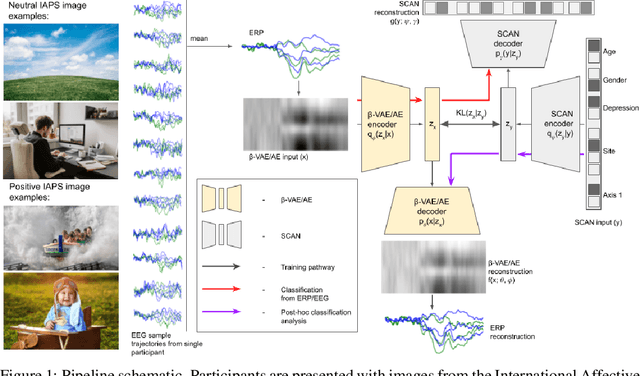
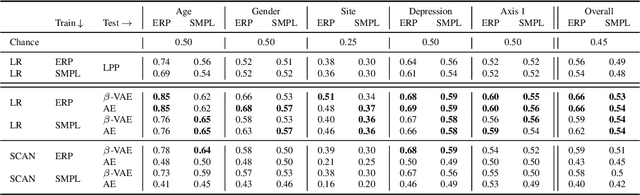
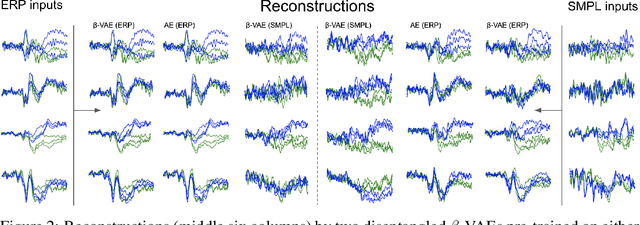

Despite extensive standardization, diagnostic interviews for mental health disorders encompass substantial subjective judgment. Previous studies have demonstrated that EEG-based neural measures can function as reliable objective correlates of depression, or even predictors of depression and its course. However, their clinical utility has not been fully realized because of 1) the lack of automated ways to deal with the inherent noise associated with EEG data at scale, and 2) the lack of knowledge of which aspects of the EEG signal may be markers of a clinical disorder. Here we adapt an unsupervised pipeline from the recent deep representation learning literature to address these problems by 1) learning a disentangled representation using $\beta$-VAE to denoise the signal, and 2) extracting interpretable features associated with a sparse set of clinical labels using a Symbol-Concept Association Network (SCAN). We demonstrate that our method is able to outperform the canonical hand-engineered baseline classification method on a number of factors, including participant age and depression diagnosis. Furthermore, our method recovers a representation that can be used to automatically extract denoised Event Related Potentials (ERPs) from novel, single EEG trajectories, and supports fast supervised re-mapping to various clinical labels, allowing clinicians to re-use a single EEG representation regardless of updates to the standardized diagnostic system. Finally, single factors of the learned disentangled representations often correspond to meaningful markers of clinical factors, as automatically detected by SCAN, allowing for human interpretability and post-hoc expert analysis of the recommendations made by the model.
Disentangling by Subspace Diffusion
Jun 23, 2020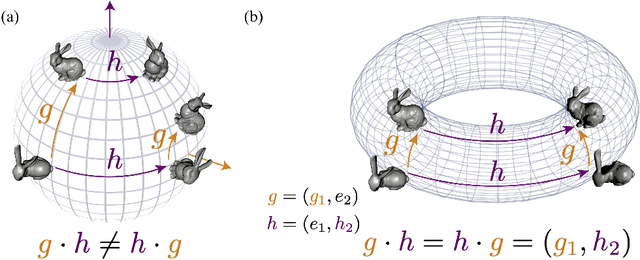

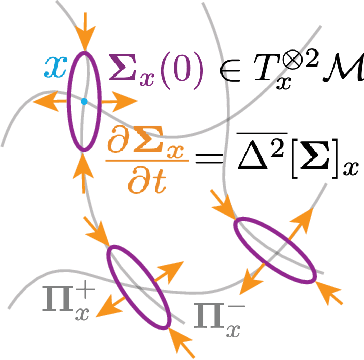
We present a novel nonparametric algorithm for symmetry-based disentangling of data manifolds, the Geometric Manifold Component Estimator (GEOMANCER). GEOMANCER provides a partial answer to the question posed by Higgins et al. (2018): is it possible to learn how to factorize a Lie group solely from observations of the orbit of an object it acts on? We show that fully unsupervised factorization of a data manifold is possible *if* the true metric of the manifold is known and each factor manifold has nontrivial holonomy -- for example, rotation in 3D. Our algorithm works by estimating the subspaces that are invariant under random walk diffusion, giving an approximation to the de Rham decomposition from differential geometry. We demonstrate the efficacy of GEOMANCER on several complex synthetic manifolds. Our work reduces the question of whether unsupervised disentangling is possible to the question of whether unsupervised metric learning is possible, providing a unifying insight into the geometric nature of representation learning.
Disentangled Cumulants Help Successor Representations Transfer to New Tasks
Nov 25, 2019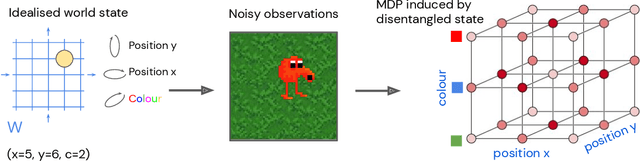
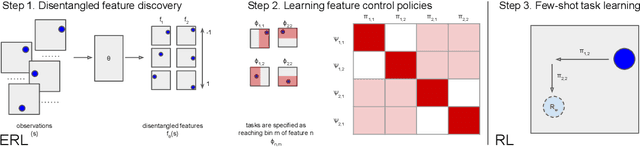
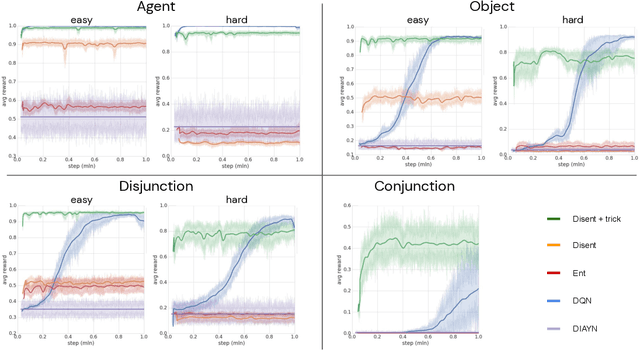
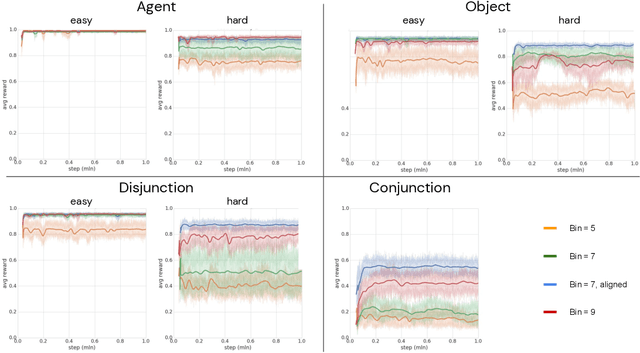
Biological intelligence can learn to solve many diverse tasks in a data efficient manner by re-using basic knowledge and skills from one task to another. Furthermore, many of such skills are acquired without explicit supervision in an intrinsically driven fashion. This is in contrast to the state-of-the-art reinforcement learning agents, which typically start learning each new task from scratch and struggle with knowledge transfer. In this paper we propose a principled way to learn a basis set of policies, which, when recombined through generalised policy improvement, come with guarantees on the coverage of the final task space. In particular, we concentrate on solving goal-based downstream tasks where the execution order of actions is not important. We demonstrate both theoretically and empirically that learning a small number of policies that reach intrinsically specified goal regions in a disentangled latent space can be re-used to quickly achieve a high level of performance on an exponentially larger number of externally specified, often significantly more complex downstream tasks. Our learning pipeline consists of two stages. First, the agent learns to perform intrinsically generated, goal-based tasks in the total absence of environmental rewards. Second, the agent leverages this experience to quickly achieve a high level of performance on numerous diverse externally specified tasks.