 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Gemini in an arena for learning
May 30, 2025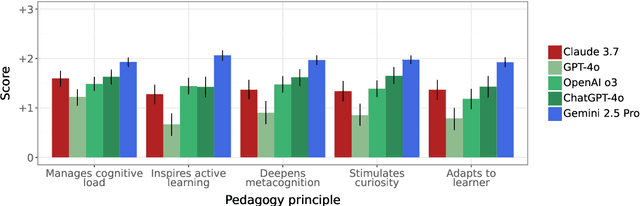

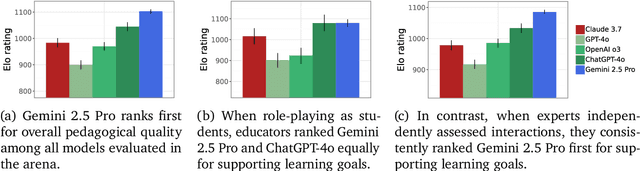
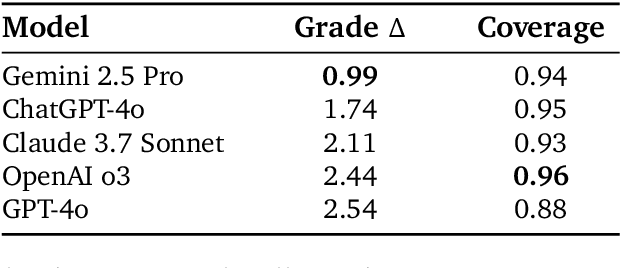
Artificial intelligence (AI) is poised to transform education, but the research community lacks a robust, general benchmark to evaluate AI models for learning. To assess state-of-the-art support for educational use cases, we ran an "arena for learning" where educators and pedagogy experts conduct blind, head-to-head, multi-turn comparisons of leading AI models. In particular, $N = 189$ educators drew from their experience to role-play realistic learning use cases, interacting with two models sequentially, after which $N = 206$ experts judged which model better supported the user's learning goals. The arena evaluated a slate of state-of-the-art models: Gemini 2.5 Pro, Claude 3.7 Sonnet, GPT-4o, and OpenAI o3. Excluding ties, experts preferred Gemini 2.5 Pro in 73.2% of these match-ups -- ranking it first overall in the arena. Gemini 2.5 Pro also demonstrated markedly higher performance across key principles of good pedagogy. Altogether, these results position Gemini 2.5 Pro as a leading model for learning.
LearnLM: Improving Gemini for Learning
Dec 21, 2024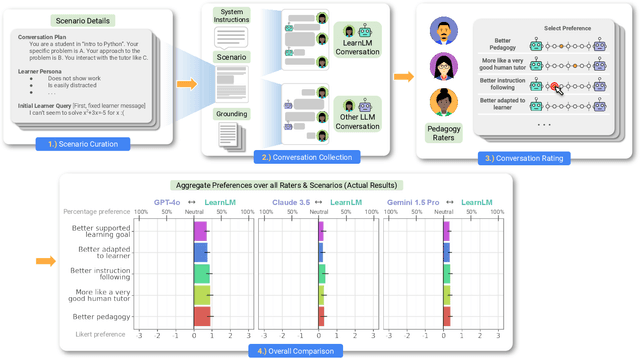
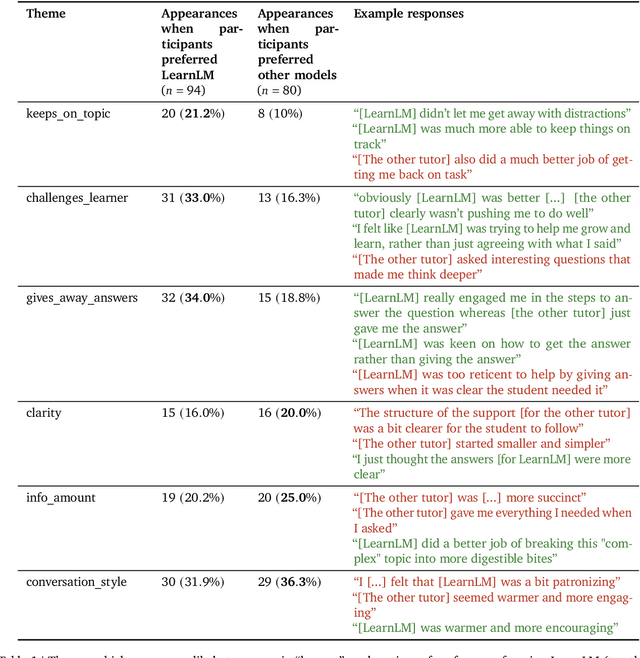
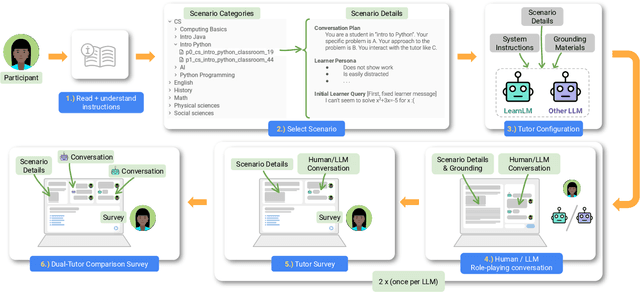
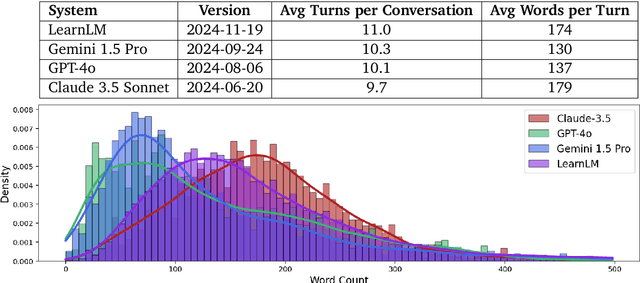
Today's generative AI systems are tuned to present information by default rather than engage users in service of learning as a human tutor would. To address the wide range of potential education use cases for these systems, we reframe the challenge of injecting pedagogical behavior as one of \textit{pedagogical instruction following}, where training and evaluation examples include system-level instructions describing the specific pedagogy attributes present or desired in subsequent model turns. This framing avoids committing our models to any particular definition of pedagogy, and instead allows teachers or developers to specify desired model behavior. It also clears a path to improving Gemini models for learning -- by enabling the addition of our pedagogical data to post-training mixtures -- alongside their rapidly expanding set of capabilities. Both represent important changes from our initial tech report. We show how training with pedagogical instruction following produces a LearnLM model (available on Google AI Studio) that is preferred substantially by expert raters across a diverse set of learning scenarios, with average preference strengths of 31\% over GPT-4o, 11\% over Claude 3.5, and 13\% over the Gemini 1.5 Pro model LearnLM was based on.
Separating the Wheat from the Chaff with BREAD: An open-source benchmark and metrics to detect redundancy in text
Nov 11, 2023Data quality is a problem that perpetually resurfaces throughout the field of NLP, regardless of task, domain, or architecture, and remains especially severe for lower-resource languages. A typical and insidious issue, affecting both training data and model output, is data that is repetitive and dominated by linguistically uninteresting boilerplate, such as price catalogs or computer-generated log files. Though this problem permeates many web-scraped corpora, there has yet to be a benchmark to test against, or a systematic study to find simple metrics that generalize across languages and agree with human judgements of data quality. In the present work, we create and release BREAD, a human-labeled benchmark on repetitive boilerplate vs. plausible linguistic content, spanning 360 languages. We release several baseline CRED (Character REDundancy) scores along with it, and evaluate their effectiveness on BREAD. We hope that the community will use this resource to develop better filtering methods, and that our reference implementations of CRED scores can become standard corpus evaluation tools, driving the development of cleaner language modeling corpora, especially in low-resource languages.
Solving math word problems with process- and outcome-based feedback
Nov 25, 2022



Recent work has shown that asking language models to generate reasoning steps improves performance on many reasoning tasks. When moving beyond prompting, this raises the question of how we should supervise such models: outcome-based approaches which supervise the final result, or process-based approaches which supervise the reasoning process itself? Differences between these approaches might naturally be expected not just in final-answer errors but also in reasoning errors, which can be difficult to detect and are problematic in many real-world domains such as education. We run the first comprehensive comparison between process- and outcome-based approaches trained on a natural language task, GSM8K. We find that pure outcome-based supervision produces similar final-answer error rates with less label supervision. However, for correct reasoning steps we find it necessary to use process-based supervision or supervision from learned reward models that emulate process-based feedback. In total, we improve the previous best results from 16.8% $\to$ 12.7% final-answer error and 14.0% $\to$ 3.4% reasoning error among final-answer-correct solutions.
TF-GNN: Graph Neural Networks in TensorFlow
Jul 07, 2022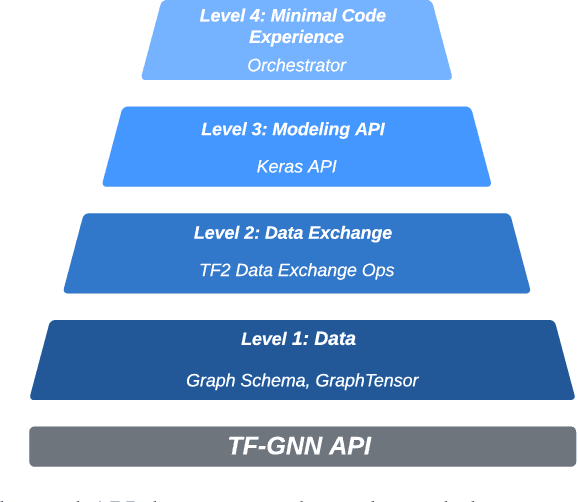
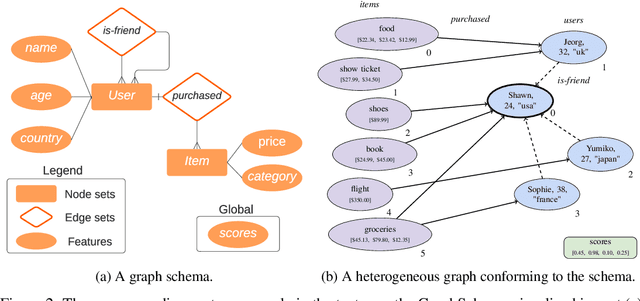
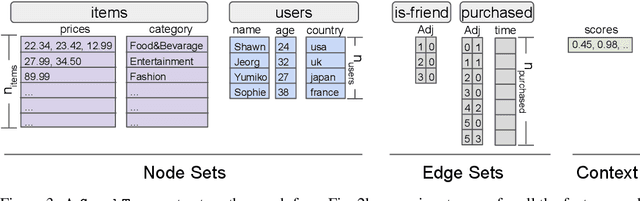
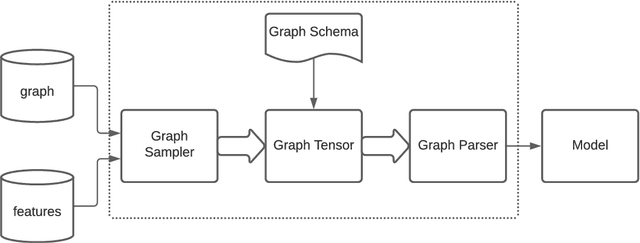
TensorFlow GNN (TF-GNN) is a scalable library for Graph Neural Networks in TensorFlow. It is designed from the bottom up to support the kinds of rich heterogeneous graph data that occurs in today's information ecosystems. Many production models at Google use TF-GNN and it has been recently released as an open source project. In this paper, we describe the TF-GNN data model, its Keras modeling API, and relevant capabilities such as graph sampling, distributed training, and accelerator support.
Pareto-Optimal Quantized ResNet Is Mostly 4-bit
May 07, 2021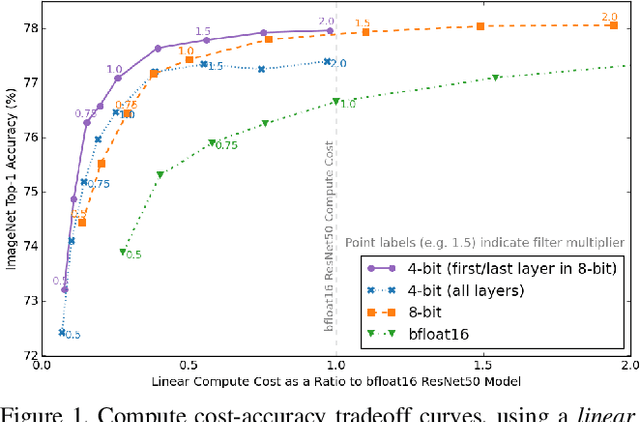


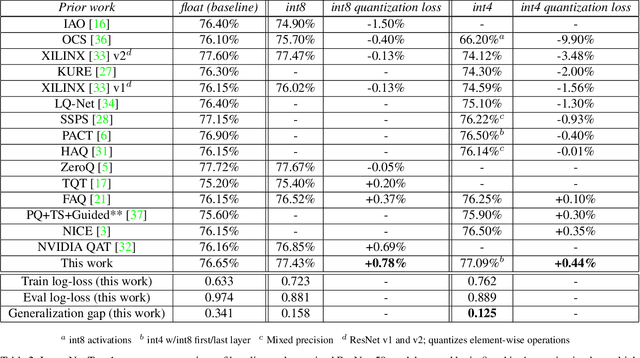
Quantization has become a popular technique to compress neural networks and reduce compute cost, but most prior work focuses on studying quantization without changing the network size. Many real-world applications of neural networks have compute cost and memory budgets, which can be traded off with model quality by changing the number of parameters. In this work, we use ResNet as a case study to systematically investigate the effects of quantization on inference compute cost-quality tradeoff curves. Our results suggest that for each bfloat16 ResNet model, there are quantized models with lower cost and higher accuracy; in other words, the bfloat16 compute cost-quality tradeoff curve is Pareto-dominated by the 4-bit and 8-bit curves, with models primarily quantized to 4-bit yielding the best Pareto curve. Furthermore, we achieve state-of-the-art results on ImageNet for 4-bit ResNet-50 with quantization-aware training, obtaining a top-1 eval accuracy of 77.09%. We demonstrate the regularizing effect of quantization by measuring the generalization gap. The quantization method we used is optimized for practicality: It requires little tuning and is designed with hardware capabilities in mind. Our work motivates further research into optimal numeric formats for quantization, as well as the development of machine learning accelerators supporting these formats. As part of this work, we contribute a quantization library written in JAX, which is open-sourced at https://github.com/google-research/google-research/tree/master/aqt.
Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets
Mar 22, 2021
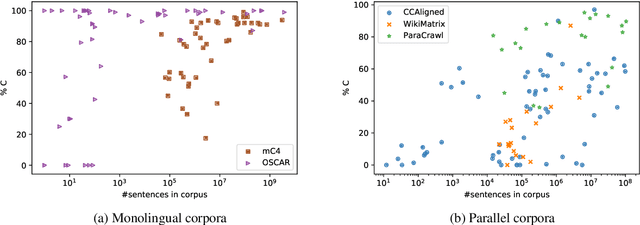

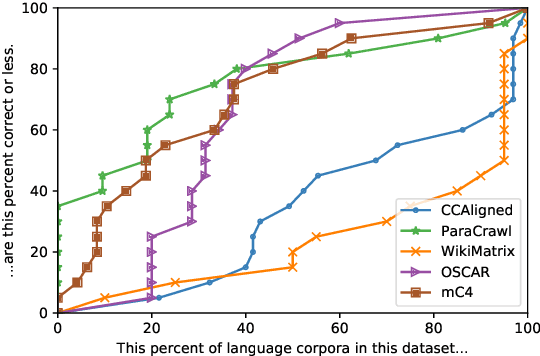
With the success of large-scale pre-training and multilingual modeling in Natural Language Processing (NLP), recent years have seen a proliferation of large, web-mined text datasets covering hundreds of languages. However, to date there has been no systematic analysis of the quality of these publicly available datasets, or whether the datasets actually contain content in the languages they claim to represent. In this work, we manually audit the quality of 205 language-specific corpora released with five major public datasets (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4), and audit the correctness of language codes in a sixth (JW300). We find that lower-resource corpora have systematic issues: at least 15 corpora are completely erroneous, and a significant fraction contains less than 50% sentences of acceptable quality. Similarly, we find 82 corpora that are mislabeled or use nonstandard/ambiguous language codes. We demonstrate that these issues are easy to detect even for non-speakers of the languages in question, and supplement the human judgements with automatic analyses. Inspired by our analysis, we recommend techniques to evaluate and improve multilingual corpora and discuss the risks that come with low-quality data releases.