 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Let Your Graph Do the Talking: Encoding Structured Data for LLMs
Feb 08, 2024How can we best encode structured data into sequential form for use in large language models (LLMs)? In this work, we introduce a parameter-efficient method to explicitly represent structured data for LLMs. Our method, GraphToken, learns an encoding function to extend prompts with explicit structured information. Unlike other work which focuses on limited domains (e.g. knowledge graph representation), our work is the first effort focused on the general encoding of structured data to be used for various reasoning tasks. We show that explicitly representing the graph structure allows significant improvements to graph reasoning tasks. Specifically, we see across the board improvements - up to 73% points - on node, edge and, graph-level tasks from the GraphQA benchmark.
UGSL: A Unified Framework for Benchmarking Graph Structure Learning
Aug 21, 2023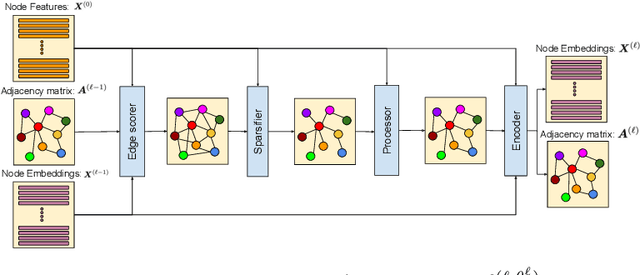

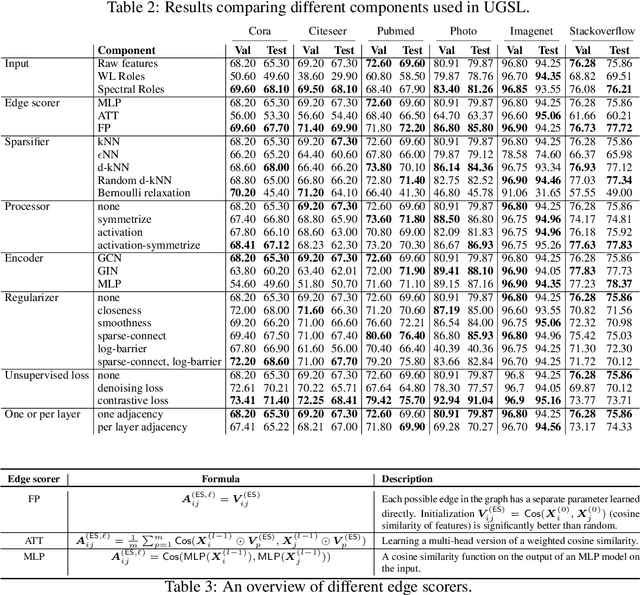
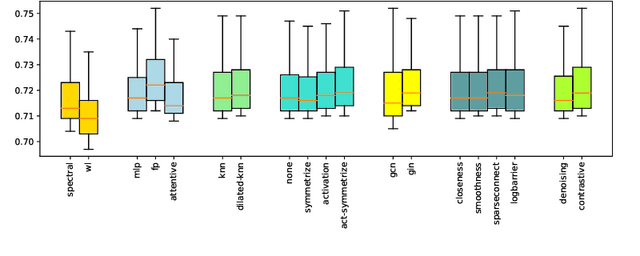
Graph neural networks (GNNs) demonstrate outstanding performance in a broad range of applications. While the majority of GNN applications assume that a graph structure is given, some recent methods substantially expanded the applicability of GNNs by showing that they may be effective even when no graph structure is explicitly provided. The GNN parameters and a graph structure are jointly learned. Previous studies adopt different experimentation setups, making it difficult to compare their merits. In this paper, we propose a benchmarking strategy for graph structure learning using a unified framework. Our framework, called Unified Graph Structure Learning (UGSL), reformulates existing models into a single model. We implement a wide range of existing models in our framework and conduct extensive analyses of the effectiveness of different components in the framework. Our results provide a clear and concise understanding of the different methods in this area as well as their strengths and weaknesses. The benchmark code is available at https://github.com/google-research/google-research/tree/master/ugsl.
Learning Large Graph Property Prediction via Graph Segment Training
May 21, 2023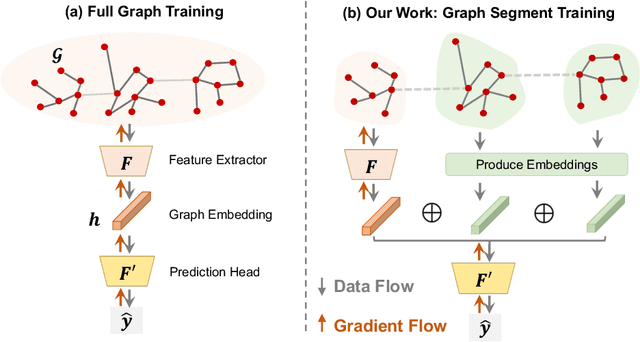
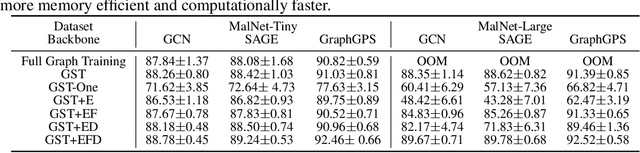

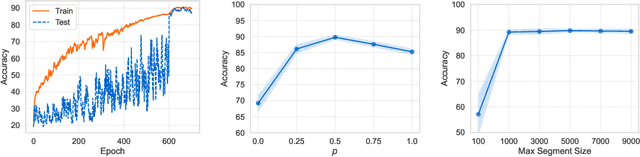
Learning to predict properties of large graphs is challenging because each prediction requires the knowledge of an entire graph, while the amount of memory available during training is bounded. Here we propose Graph Segment Training (GST), a general framework that utilizes a divide-and-conquer approach to allow learning large graph property prediction with a constant memory footprint. GST first divides a large graph into segments and then backpropagates through only a few segments sampled per training iteration. We refine the GST paradigm by introducing a historical embedding table to efficiently obtain embeddings for segments not sampled for backpropagation. To mitigate the staleness of historical embeddings, we design two novel techniques. First, we finetune the prediction head to fix the input distribution shift. Second, we introduce Stale Embedding Dropout to drop some stale embeddings during training to reduce bias. We evaluate our complete method GST-EFD (with all the techniques together) on two large graph property prediction benchmarks: MalNet and TpuGraphs. Our experiments show that GST-EFD is both memory-efficient and fast, while offering a slight boost on test accuracy over a typical full graph training regime.
TF-GNN: Graph Neural Networks in TensorFlow
Jul 07, 2022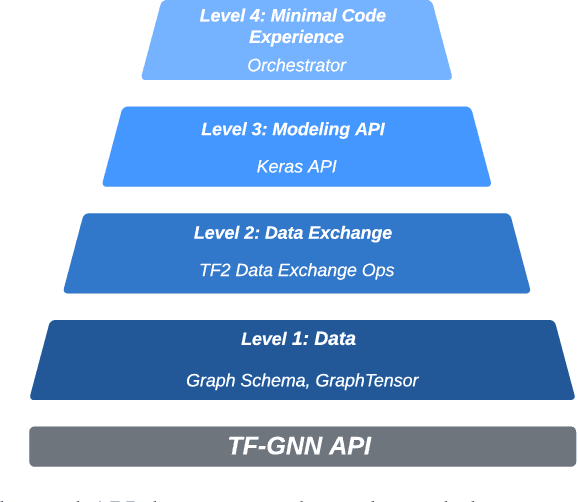
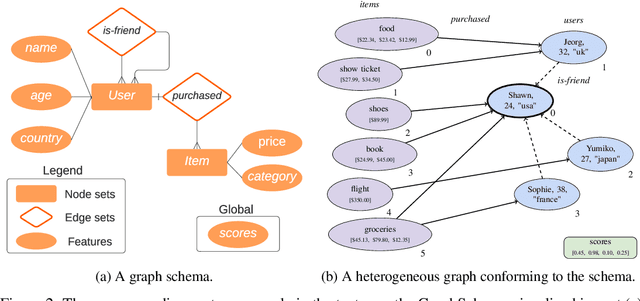
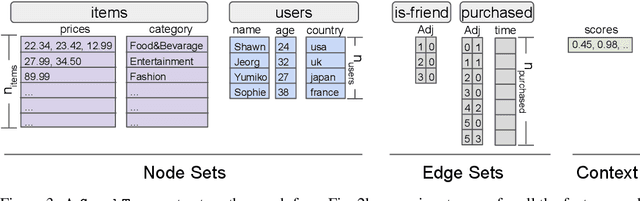
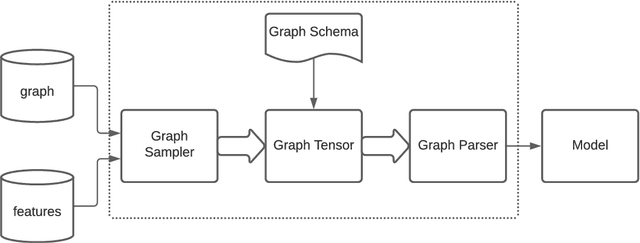
TensorFlow GNN (TF-GNN) is a scalable library for Graph Neural Networks in TensorFlow. It is designed from the bottom up to support the kinds of rich heterogeneous graph data that occurs in today's information ecosystems. Many production models at Google use TF-GNN and it has been recently released as an open source project. In this paper, we describe the TF-GNN data model, its Keras modeling API, and relevant capabilities such as graph sampling, distributed training, and accelerator support.
Zero-shot Domain Adaptation of Heterogeneous Graphs via Knowledge Transfer Networks
Mar 03, 2022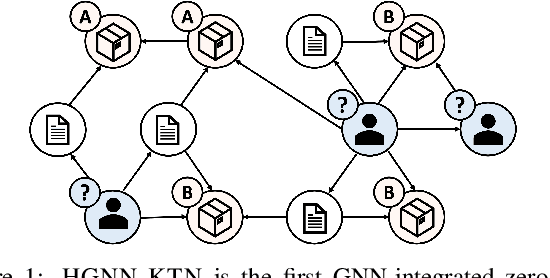
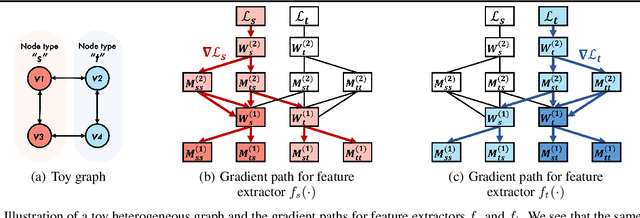
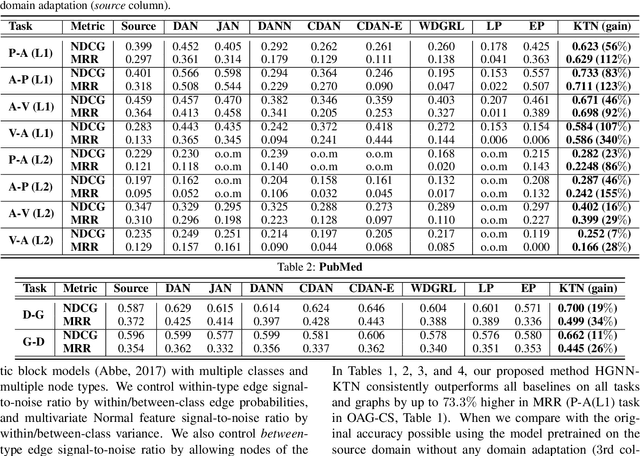
How can we make predictions for nodes in a heterogeneous graph when an entire type of node (e.g. user) has no labels (perhaps due to privacy issues) at all? Although heterogeneous graph neural networks (HGNNs) have shown superior performance as powerful representation learning techniques, there is no direct way to learn using labels rooted at different node types. Domain adaptation (DA) targets this setting, however, existing DA can not be applied directly to HGNNs. In heterogeneous graphs, the source and target domains have different modalities, thus HGNNs provide different feature extractors to them, while most of DA assumes source and target domains share a common feature extractor. In this work, we address the issue of zero-shot domain adaptation in HGNNs. We first theoretically induce a relationship between source and target domain features extracted from HGNNs, then propose a novel domain adaptation method, Knowledge Transfer Networks for HGNNs (HGNN-KTN). HGNN-KTN learns the relationship between source and target features, then maps the target distributions into the source domain. HGNN-KTN outperforms state-of-the-art baselines, showing up to 73.3% higher in MRR on 18 different domain adaptation tasks running on real-world benchmark graphs.
DDGK: Learning Graph Representations for Deep Divergence Graph Kernels
Apr 21, 2019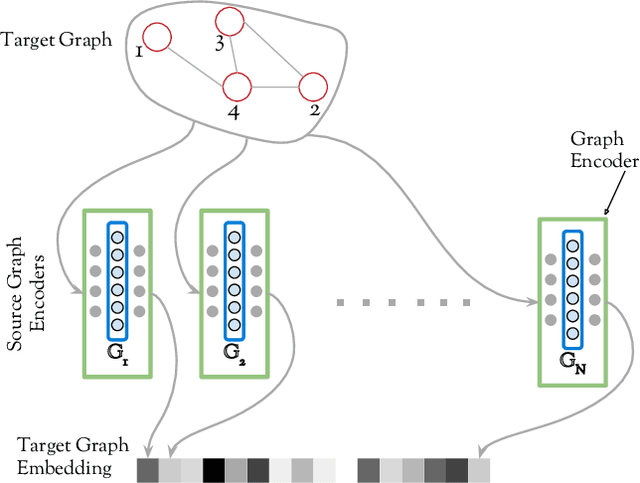

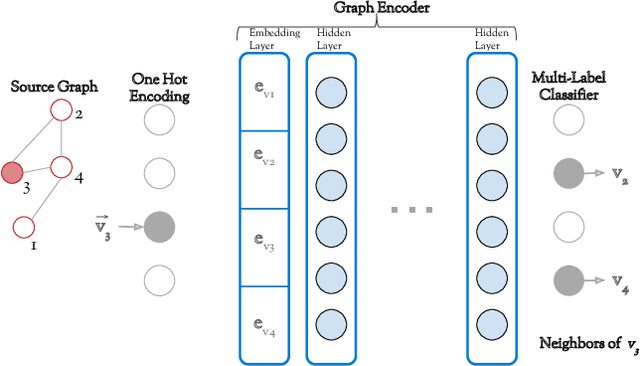
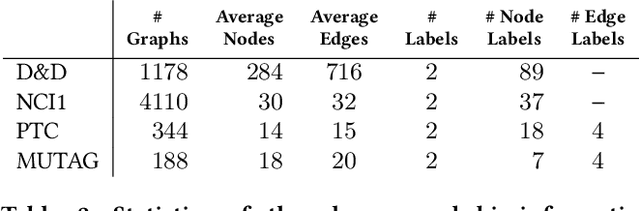
Can neural networks learn to compare graphs without feature engineering? In this paper, we show that it is possible to learn representations for graph similarity with neither domain knowledge nor supervision (i.e.\ feature engineering or labeled graphs). We propose Deep Divergence Graph Kernels, an unsupervised method for learning representations over graphs that encodes a relaxed notion of graph isomorphism. Our method consists of three parts. First, we learn an encoder for each anchor graph to capture its structure. Second, for each pair of graphs, we train a cross-graph attention network which uses the node representations of an anchor graph to reconstruct another graph. This approach, which we call isomorphism attention, captures how well the representations of one graph can encode another. We use the attention-augmented encoder's predictions to define a divergence score for each pair of graphs. Finally, we construct an embedding space for all graphs using these pair-wise divergence scores. Unlike previous work, much of which relies on 1) supervision, 2) domain specific knowledge (e.g. a reliance on Weisfeiler-Lehman kernels), and 3) known node alignment, our unsupervised method jointly learns node representations, graph representations, and an attention-based alignment between graphs. Our experimental results show that Deep Divergence Graph Kernels can learn an unsupervised alignment between graphs, and that the learned representations achieve competitive results when used as features on a number of challenging graph classification tasks. Furthermore, we illustrate how the learned attention allows insight into the the alignment of sub-structures across graphs.
* www '19