 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Question-Answer Generation for Long-Tail Knowledge
Mar 03, 2024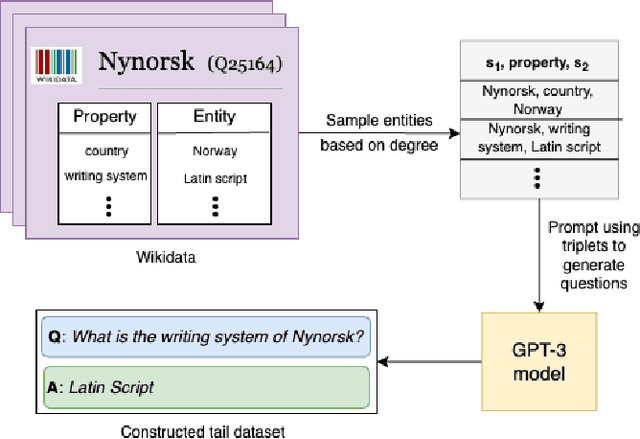

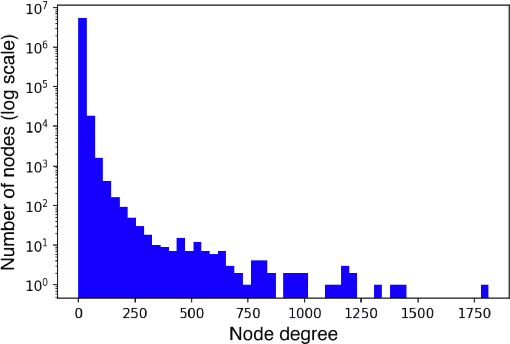
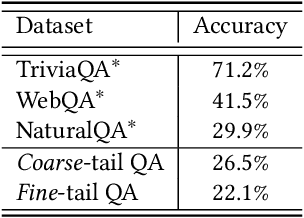
Pretrained Large Language Models (LLMs) have gained significant attention for addressing open-domain Question Answering (QA). While they exhibit high accuracy in answering questions related to common knowledge, LLMs encounter difficulties in learning about uncommon long-tail knowledge (tail entities). Since manually constructing QA datasets demands substantial human resources, the types of existing QA datasets are limited, leaving us with a scarcity of datasets to study the performance of LLMs on tail entities. In this paper, we propose an automatic approach to generate specialized QA datasets for tail entities and present the associated research challenges. We conduct extensive experiments by employing pretrained LLMs on our newly generated long-tail QA datasets, comparing their performance with and without external resources including Wikipedia and Wikidata knowledge graphs.
Multimodal Graph Learning for Generative Tasks
Oct 12, 2023



Multimodal learning combines multiple data modalities, broadening the types and complexity of data our models can utilize: for example, from plain text to image-caption pairs. Most multimodal learning algorithms focus on modeling simple one-to-one pairs of data from two modalities, such as image-caption pairs, or audio-text pairs. However, in most real-world settings, entities of different modalities interact with each other in more complex and multifaceted ways, going beyond one-to-one mappings. We propose to represent these complex relationships as graphs, allowing us to capture data with any number of modalities, and with complex relationships between modalities that can flexibly vary from one sample to another. Toward this goal, we propose Multimodal Graph Learning (MMGL), a general and systematic framework for capturing information from multiple multimodal neighbors with relational structures among them. In particular, we focus on MMGL for generative tasks, building upon pretrained Language Models (LMs), aiming to augment their text generation with multimodal neighbor contexts. We study three research questions raised by MMGL: (1) how can we infuse multiple neighbor information into the pretrained LMs, while avoiding scalability issues? (2) how can we infuse the graph structure information among multimodal neighbors into the LMs? and (3) how can we finetune the pretrained LMs to learn from the neighbor context in a parameter-efficient manner? We conduct extensive experiments to answer these three questions on MMGL and analyze the empirical results to pave the way for future MMGL research.
Scalable Privacy-enhanced Benchmark Graph Generative Model for Graph Convolutional Networks
Jul 10, 2022
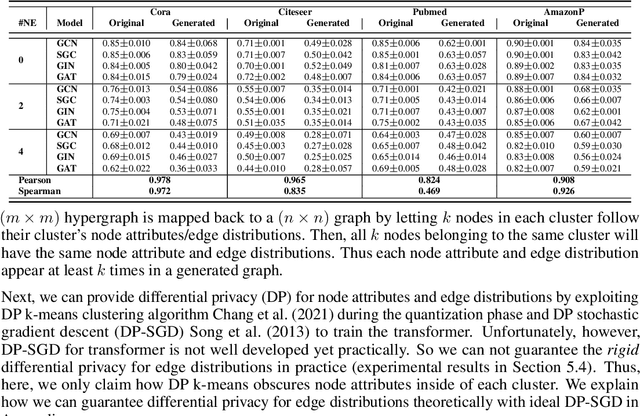
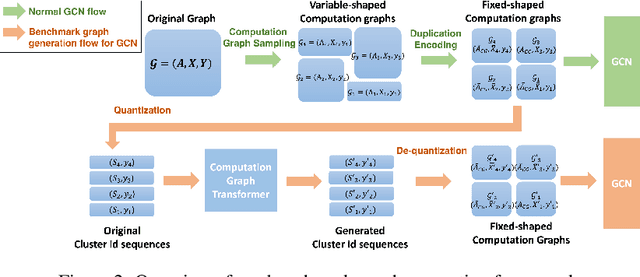
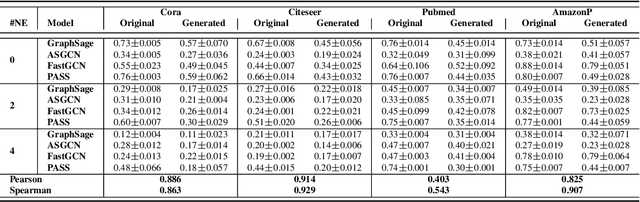
A surge of interest in Graph Convolutional Networks (GCN) has produced thousands of GCN variants, with hundreds introduced every year. In contrast, many GCN models re-use only a handful of benchmark datasets as many graphs of interest, such as social or commercial networks, are proprietary. We propose a new graph generation problem to enable generating a diverse set of benchmark graphs for GCNs following the distribution of a source graph -- possibly proprietary -- with three requirements: 1) benchmark effectiveness as a substitute for the source graph for GCN research, 2) scalability to process large-scale real-world graphs, and 3) a privacy guarantee for end-users. With a novel graph encoding scheme, we reframe large-scale graph generation problem into medium-length sequence generation problem and apply the strong generation power of the Transformer architecture to the graph domain. Extensive experiments across a vast body of graph generative models show that our model can successfully generate benchmark graphs with the realistic graph structure, node attributes, and node labels required to benchmark GCNs on node classification tasks.
A Dataset on Malicious Paper Bidding in Peer Review
Jun 24, 2022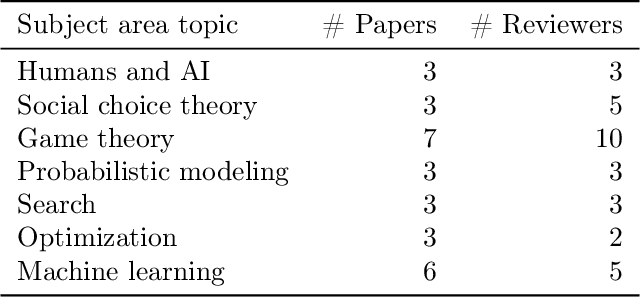

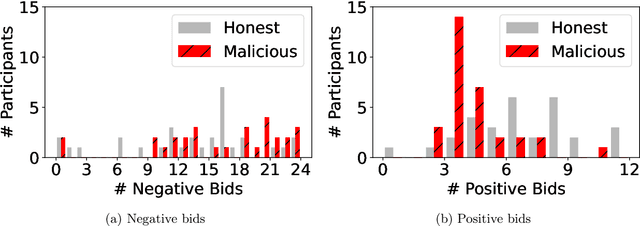
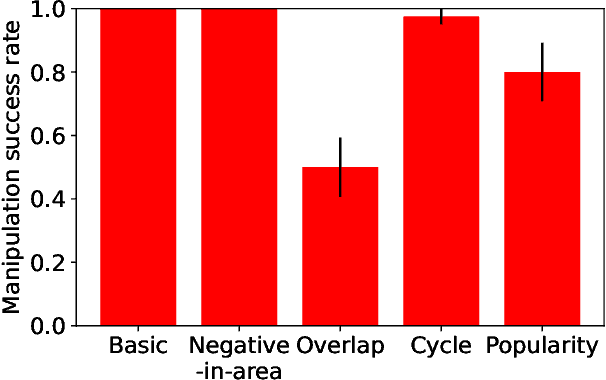
In conference peer review, reviewers are often asked to provide "bids" on each submitted paper that express their interest in reviewing that paper. A paper assignment algorithm then uses these bids (along with other data) to compute a high-quality assignment of reviewers to papers. However, this process has been exploited by malicious reviewers who strategically bid in order to unethically manipulate the paper assignment, crucially undermining the peer review process. For example, these reviewers may aim to get assigned to a friend's paper as part of a quid-pro-quo deal. A critical impediment towards creating and evaluating methods to mitigate this issue is the lack of any publicly-available data on malicious paper bidding. In this work, we collect and publicly release a novel dataset to fill this gap, collected from a mock conference activity where participants were instructed to bid either honestly or maliciously. We further provide a descriptive analysis of the bidding behavior, including our categorization of different strategies employed by participants. Finally, we evaluate the ability of each strategy to manipulate the assignment, and also evaluate the performance of some simple algorithms meant to detect malicious bidding. The performance of these detection algorithms can be taken as a baseline for future research on detecting malicious bidding.
Zero-shot Domain Adaptation of Heterogeneous Graphs via Knowledge Transfer Networks
Mar 03, 2022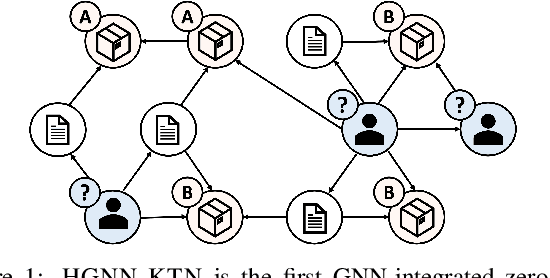
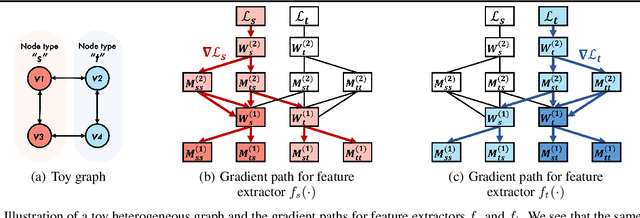
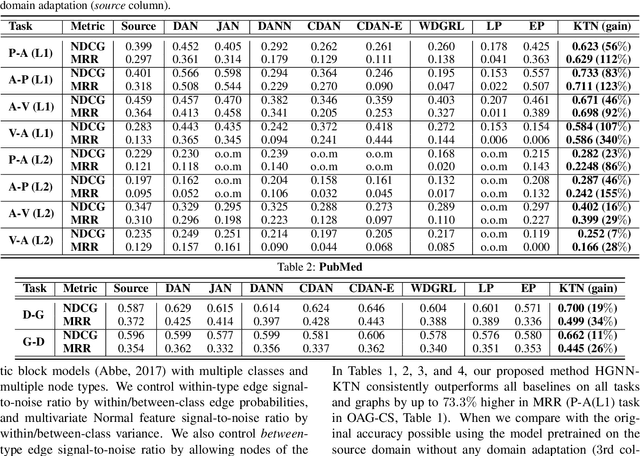
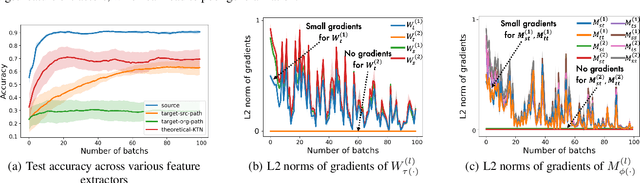
How can we make predictions for nodes in a heterogeneous graph when an entire type of node (e.g. user) has no labels (perhaps due to privacy issues) at all? Although heterogeneous graph neural networks (HGNNs) have shown superior performance as powerful representation learning techniques, there is no direct way to learn using labels rooted at different node types. Domain adaptation (DA) targets this setting, however, existing DA can not be applied directly to HGNNs. In heterogeneous graphs, the source and target domains have different modalities, thus HGNNs provide different feature extractors to them, while most of DA assumes source and target domains share a common feature extractor. In this work, we address the issue of zero-shot domain adaptation in HGNNs. We first theoretically induce a relationship between source and target domain features extracted from HGNNs, then propose a novel domain adaptation method, Knowledge Transfer Networks for HGNNs (HGNN-KTN). HGNN-KTN learns the relationship between source and target features, then maps the target distributions into the source domain. HGNN-KTN outperforms state-of-the-art baselines, showing up to 73.3% higher in MRR on 18 different domain adaptation tasks running on real-world benchmark graphs.
Autonomous Graph Mining Algorithm Search with Best Speed/Accuracy Trade-off
Nov 26, 2020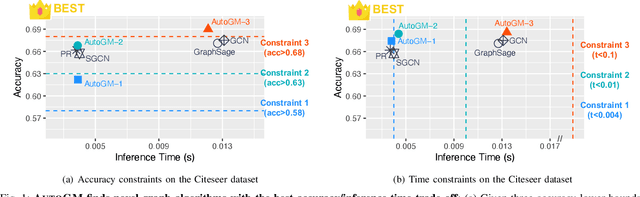
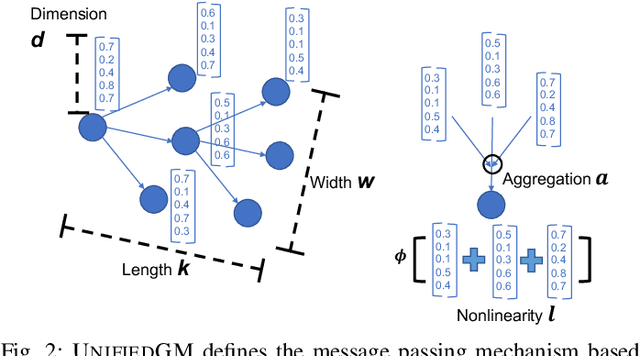
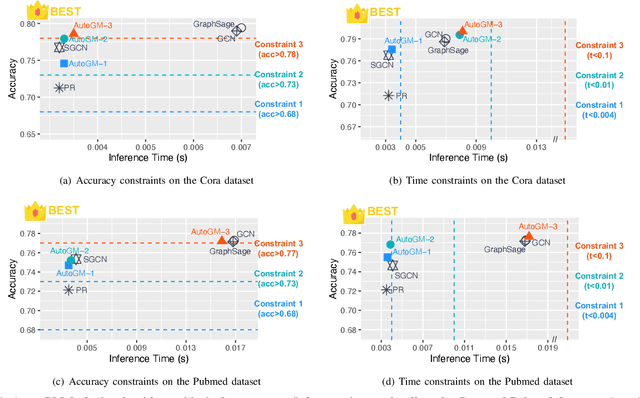
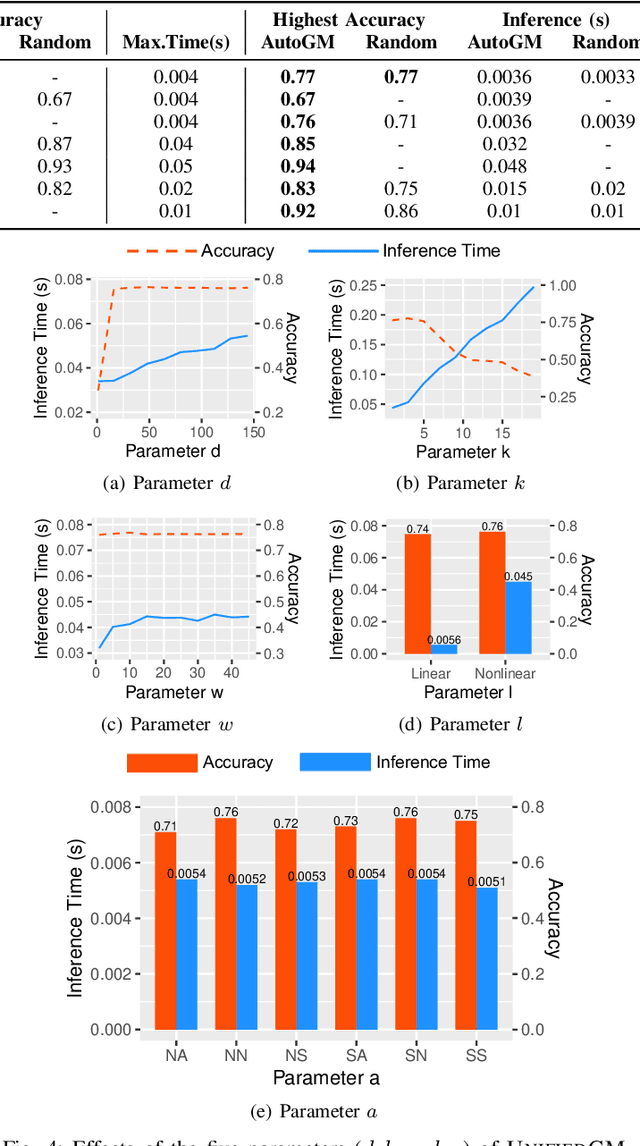
Graph data is ubiquitous in academia and industry, from social networks to bioinformatics. The pervasiveness of graphs today has raised the demand for algorithms that can answer various questions: Which products would a user like to purchase given her order list? Which users are buying fake followers to increase their public reputation? Myriads of new graph mining algorithms are proposed every year to answer such questions - each with a distinct problem formulation, computational time, and memory footprint. This lack of unity makes it difficult for a practitioner to compare different algorithms and pick the most suitable one for a specific application. These challenges - even more severe for non-experts - create a gap in which state-of-the-art techniques developed in academic settings fail to be optimally deployed in real-world applications. To bridge this gap, we propose AUTOGM, an automated system for graph mining algorithm development. We first define a unified framework UNIFIEDGM that integrates various message-passing based graph algorithms, ranging from conventional algorithms like PageRank to graph neural networks. Then UNIFIEDGM defines a search space in which five parameters are required to determine a graph algorithm. Under this search space, AUTOGM explicitly optimizes for the optimal parameter set of UNIFIEDGM using Bayesian Optimization. AUTOGM defines a novel budget-aware objective function for the optimization to incorporate a practical issue - finding the best speed-accuracy trade-off under a computation budget - into the graph algorithm generation problem. Experiments on real-world benchmark datasets demonstrate that AUTOGM generates novel graph mining algorithms with the best speed/accuracy trade-off compared to existing models with heuristic parameters.
Fast and Accurate Anomaly Detection in Dynamic Graphs with a Two-Pronged Approach
Nov 26, 2020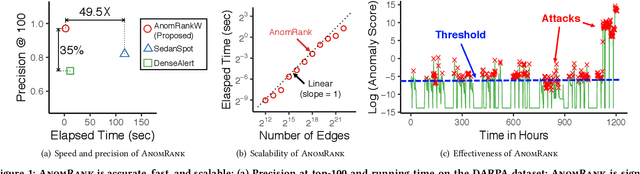

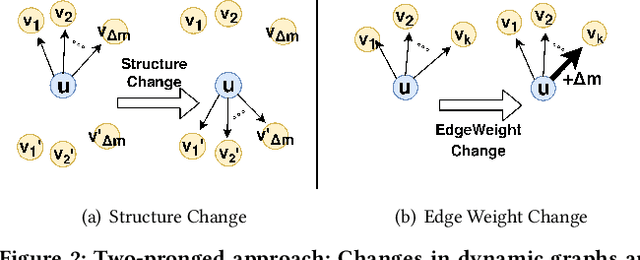

Given a dynamic graph stream, how can we detect the sudden appearance of anomalous patterns, such as link spam, follower boosting, or denial of service attacks? Additionally, can we categorize the types of anomalies that occur in practice, and theoretically analyze the anomalous signs arising from each type? In this work, we propose AnomRank, an online algorithm for anomaly detection in dynamic graphs. AnomRank uses a two-pronged approach defining two novel metrics for anomalousness. Each metric tracks the derivatives of its own version of a 'node score' (or node importance) function. This allows us to detect sudden changes in the importance of any node. We show theoretically and experimentally that the two-pronged approach successfully detects two common types of anomalies: sudden weight changes along an edge, and sudden structural changes to the graph. AnomRank is (a) Fast and Accurate: up to 49.5x faster or 35% more accurate than state-of-the-art methods, (b) Scalable: linear in the number of edges in the input graph, processing millions of edges within 2 seconds on a stock laptop/desktop, and (c) Theoretically Sound: providing theoretical guarantees of the two-pronged approach.
Real-Time Streaming Anomaly Detection in Dynamic Graphs
Sep 17, 2020
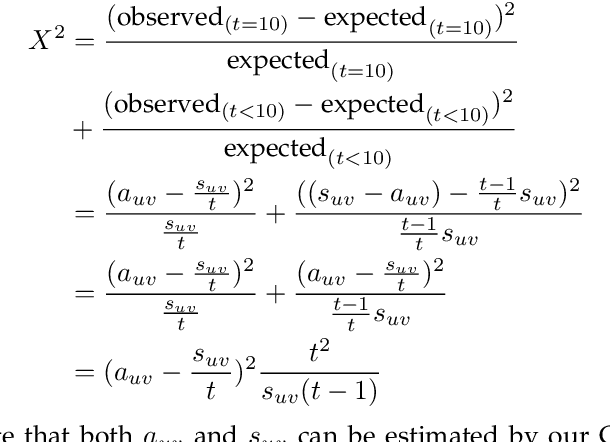
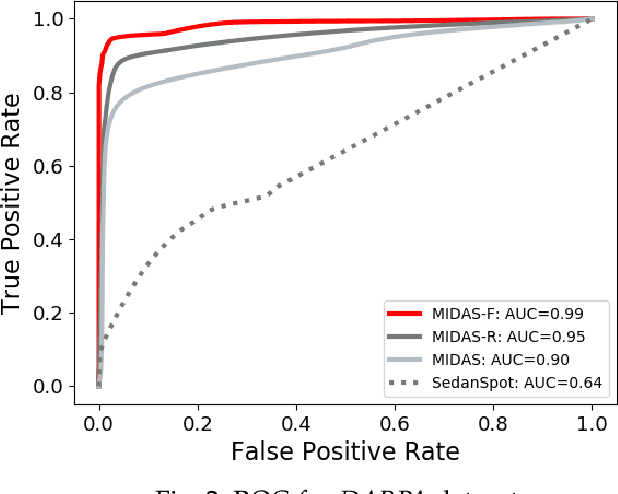
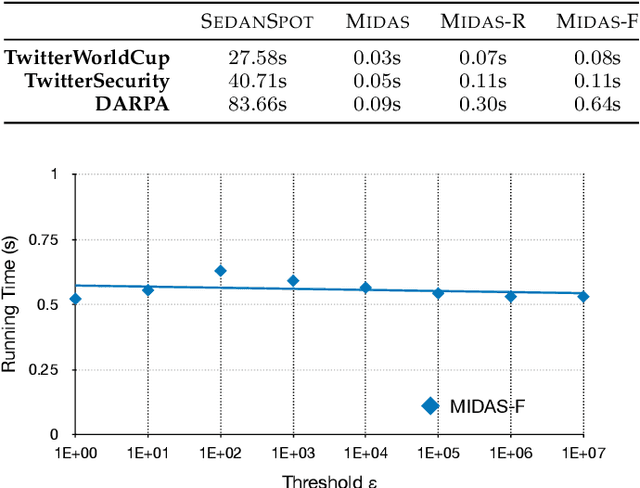
Given a stream of graph edges from a dynamic graph, how can we assign anomaly scores to edges in an online manner, for the purpose of detecting unusual behavior, using constant time and memory? Existing approaches aim to detect individually surprising edges. In this work, we propose MIDAS, which focuses on detecting microcluster anomalies, or suddenly arriving groups of suspiciously similar edges, such as lockstep behavior, including denial of service attacks in network traffic data. We further propose MIDAS-F, to solve the problem by which anomalies are incorporated into the algorithm's internal states, creating a 'poisoning' effect which can allow future anomalies to slip through undetected. MIDAS-F introduces two modifications: 1) We modify the anomaly scoring function, aiming to reduce the 'poisoning' effect of newly arriving edges; 2) We introduce a conditional merge step, which updates the algorithm's data structures after each time tick, but only if the anomaly score is below a threshold value, also to reduce the `poisoning' effect. Experiments show that MIDAS-F has significantly higher accuracy than MIDAS. MIDAS has the following properties: (a) it detects microcluster anomalies while providing theoretical guarantees about its false positive probability; (b) it is online, thus processing each edge in constant time and constant memory, and also processes the data 130 to 929 times faster than state-of-the-art approaches; (c) it provides 41% to 55% higher accuracy (in terms of ROC-AUC) than state-of-the-art approaches.
MIDAS: Microcluster-Based Detector of Anomalies in Edge Streams
Nov 13, 2019

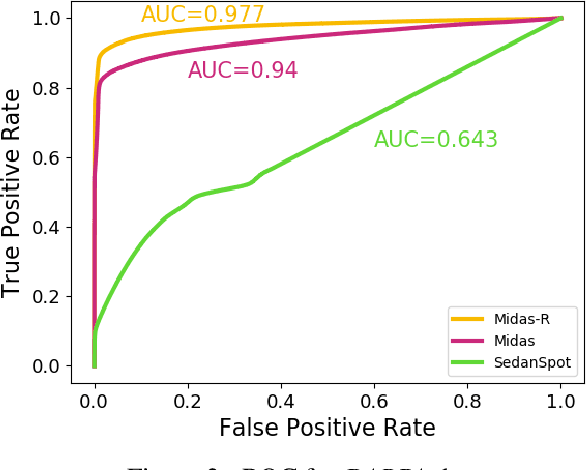

Given a stream of graph edges from a dynamic graph, how can we assign anomaly scores to edges in an online manner, for the purpose of detecting unusual behavior, using constant time and memory? Existing approaches aim to detect individually surprising edges. In this work, we propose MIDAS, which focuses on detecting microcluster anomalies, or suddenly arriving groups of suspiciously similar edges, such as lockstep behavior, including denial of service attacks in network traffic data. MIDAS has the following properties: (a) it detects microcluster anomalies while providing theoretical guarantees about its false positive probability; (b) it is online, thus processing each edge in constant time and constant memory, and also processes the data 108-505 times faster than state-of-the-art approaches; (c) it provides 46%-52% higher accuracy (in terms of AUC) than state-of-the-art approaches.