 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection and Localization of Subdural Hematoma Using Deep Learning on Computed Tomography
Dec 10, 2025Background. Subdural hematoma (SDH) is a common neurosurgical emergency, with increasing incidence in aging populations. Rapid and accurate identification is essential to guide timely intervention, yet existing automated tools focus primarily on detection and provide limited interpretability or spatial localization. There remains a need for transparent, high-performing systems that integrate multimodal clinical and imaging information to support real-time decision-making. Methods. We developed a multimodal deep-learning framework that integrates structured clinical variables, a 3D convolutional neural network trained on CT volumes, and a transformer-enhanced 2D segmentation model for SDH detection and localization. Using 25,315 head CT studies from Hartford HealthCare (2015--2024), of which 3,774 (14.9\%) contained clinician-confirmed SDH, tabular models were trained on demographics, comorbidities, medications, and laboratory results. Imaging models were trained to detect SDH and generate voxel-level probability maps. A greedy ensemble strategy combined complementary predictors. Findings. Clinical variables alone provided modest discriminatory power (AUC 0.75). Convolutional models trained on CT volumes and segmentation-derived maps achieved substantially higher accuracy (AUCs 0.922 and 0.926). The multimodal ensemble integrating all components achieved the best overall performance (AUC 0.9407; 95\% CI, 0.930--0.951) and produced anatomically meaningful localization maps consistent with known SDH patterns. Interpretation. This multimodal, interpretable framework provides rapid and accurate SDH detection and localization, achieving high detection performance and offering transparent, anatomically grounded outputs. Integration into radiology workflows could streamline triage, reduce time to intervention, and improve consistency in SDH management.
TexTAR : Textual Attribute Recognition in Multi-domain and Multi-lingual Document Images
Sep 16, 2025Recognizing textual attributes such as bold, italic, underline and strikeout is essential for understanding text semantics, structure, and visual presentation. These attributes highlight key information, making them crucial for document analysis. Existing methods struggle with computational efficiency or adaptability in noisy, multilingual settings. To address this, we introduce TexTAR, a multi-task, context-aware Transformer for Textual Attribute Recognition (TAR). Our novel data selection pipeline enhances context awareness, and our architecture employs a 2D RoPE (Rotary Positional Embedding)-style mechanism to incorporate input context for more accurate attribute predictions. We also introduce MMTAD, a diverse, multilingual, multi-domain dataset annotated with text attributes across real-world documents such as legal records, notices, and textbooks. Extensive evaluations show TexTAR outperforms existing methods, demonstrating that contextual awareness contributes to state-of-the-art TAR performance.
IIT Bombay Racing Driverless: Autonomous Driving Stack for Formula Student AI
Aug 12, 2024This work presents the design and development of IIT Bombay Racing's Formula Student style autonomous racecar algorithm capable of running at the racing events of Formula Student-AI, held in the UK. The car employs a cutting-edge sensor suite of the compute unit NVIDIA Jetson Orin AGX, 2 ZED2i stereo cameras, 1 Velodyne Puck VLP16 LiDAR and SBG Systems Ellipse N GNSS/INS IMU. It features deep learning algorithms and control systems to navigate complex tracks and execute maneuvers without any human intervention. The design process involved extensive simulations and testing to optimize the vehicle's performance and ensure its safety. The algorithms have been tested on a small scale, in-house manufactured 4-wheeled robot and on simulation software. The results obtained for testing various algorithms in perception, simultaneous localization and mapping, path planning and controls have been detailed.
Automatic Question-Answer Generation for Long-Tail Knowledge
Mar 03, 2024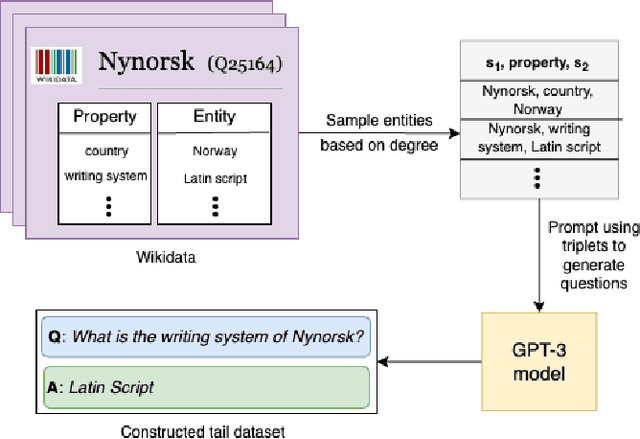

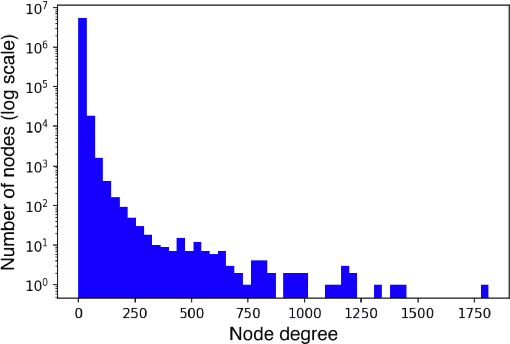
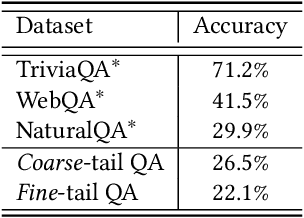
Pretrained Large Language Models (LLMs) have gained significant attention for addressing open-domain Question Answering (QA). While they exhibit high accuracy in answering questions related to common knowledge, LLMs encounter difficulties in learning about uncommon long-tail knowledge (tail entities). Since manually constructing QA datasets demands substantial human resources, the types of existing QA datasets are limited, leaving us with a scarcity of datasets to study the performance of LLMs on tail entities. In this paper, we propose an automatic approach to generate specialized QA datasets for tail entities and present the associated research challenges. We conduct extensive experiments by employing pretrained LLMs on our newly generated long-tail QA datasets, comparing their performance with and without external resources including Wikipedia and Wikidata knowledge graphs.
Logic Constrained Pointer Networks for Interpretable Textual Similarity
Jul 15, 2020

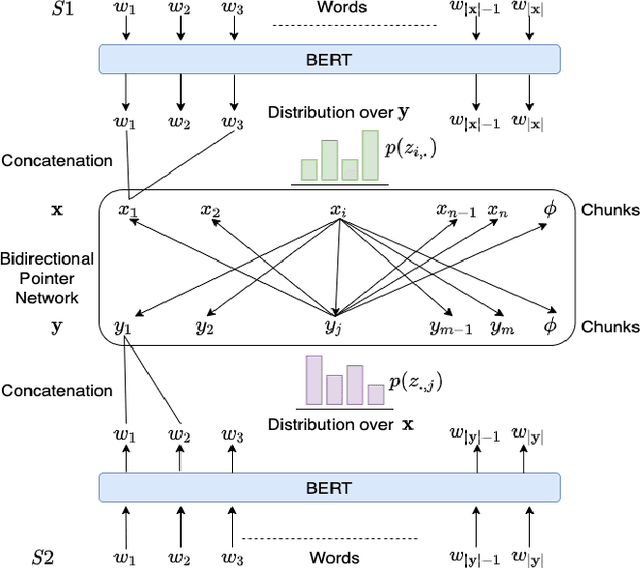
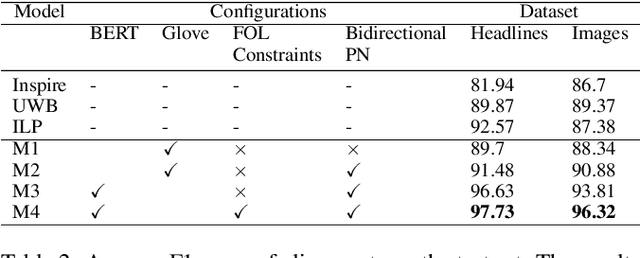
Systematically discovering semantic relationships in text is an important and extensively studied area in Natural Language Processing, with various tasks such as entailment, semantic similarity, etc. Decomposability of sentence-level scores via subsequence alignments has been proposed as a way to make models more interpretable. We study the problem of aligning components of sentences leading to an interpretable model for semantic textual similarity. In this paper, we introduce a novel pointer network based model with a sentinel gating function to align constituent chunks, which are represented using BERT. We improve this base model with a loss function to equally penalize misalignments in both sentences, ensuring the alignments are bidirectional. Finally, to guide the network with structured external knowledge, we introduce first-order logic constraints based on ConceptNet and syntactic knowledge. The model achieves an F1 score of 97.73 and 96.32 on the benchmark SemEval datasets for the chunk alignment task, showing large improvements over the existing solutions. Source code is available at https://github.com/manishb89/interpretable_sentence_similarity
* Accepted at IJCAI 2020 Main Track. Sole copyright holder is IJCAI, all rights reserved. Available at https://www.ijcai.org/Proceedings/2020/333