 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObserving the unobserved confounding through its effects: toward randomized trial-like estimates from real-world survival data
Apr 13, 2026Background: Randomized controlled trials (RCTs) are costly, time-consuming, and often infeasible, while treatment-effect estimation from observational data is limited by unobserved confounding. Methods: We developed a three-step framework to address unobserved confounding in observational survival data. First, we infer a latent prognostic factor (U) from restricted mean survival time (RMST) discrepancies between patients with similar observed factors, the same treatment, and divergent outcomes, leveraging the idea that the aggregate effect of unmeasured factors can be inferred even if individual factors cannot. Second, we balance U with observed baseline covariates using prognostic matching, entropy balancing, or inverse probability of treatment weighting. Third, we apply multivariable survival analysis to estimate hazard ratios (HRs). We evaluated the framework in three observational cohorts with RCT benchmarks, two RCT cohorts, and six multicenter observational cohorts. Results: In three observational cohorts (nine comparisons), balancing U improved agreement with trial HRs in all cases; in the strongest settings, it reduced absolute log-HR error by approximately ten-fold versus using observed covariates alone (mean reduction 0.344; p=0.001). In two RCT cohorts, U was balanced across arms (most SMDs <0.1) and adjustment had minimal impact on log-HRs (mean absolute change 0.08). Across six multicenter cohorts, balancing U within centers reduced cross-center dispersion in chemotherapy log-HR estimates (mean reduction 0.147; p=0.016); when populations were directly balanced across centers to account for case-mix differences, cross-center survival differences were narrowed in 75%-100% of comparisons. Conclusions: Inferring and balancing a latent prognostic signal may reduce unobserved confounding and improve treatment-effect estimation from real-world data.
An Interpretable AI Tool for SAVR vs TAVR in Low to Intermediate Risk Patients with Severe Aortic Stenosis
Dec 11, 2025Background. Treatment selection for low to intermediate risk patients with severe aortic stenosis between surgical (SAVR) and transcatheter (TAVR) aortic valve replacement remains variable in clinical practice, driven by patient heterogeneity and institutional preferences. While existing models predict postprocedural risk, there is a lack of interpretable, individualized treatment recommendations that directly optimize long-term outcomes. Methods. We introduce an interpretable prescriptive framework that integrates prognostic matching, counterfactual outcome modeling, and an Optimal Policy Tree (OPT) to recommend the treatment minimizing expected 5-year mortality. Using data from Hartford Hospital and St. Vincent's Hospital, we emulate randomization via prognostic matching and sample weighting and estimate counterfactual mortality under both SAVR and TAVR. The policy model, trained on these counterfactual predictions, partitions patients into clinically coherent subgroups and prescribes the treatment associated with lower estimated risk. Findings. If the OPT prescriptions are applied, counterfactual evaluation showed an estimated reduction in 5-year mortality of 20.3\% in Hartford and 13.8\% in St. Vincent's relative to real-life prescriptions, showing promising generalizability to unseen data from a different institution. The learned decision boundaries aligned with real-world outcomes and clinical observations. Interpretation. Our interpretable prescriptive framework is, to the best of our knowledge, the first to provide transparent, data-driven recommendations for TAVR versus SAVR that improve estimated long-term outcomes both in an internal and external cohort, while remaining clinically grounded and contributing toward a more systematic and evidence-based approach to precision medicine in structural heart disease.
Detection and Localization of Subdural Hematoma Using Deep Learning on Computed Tomography
Dec 10, 2025Background. Subdural hematoma (SDH) is a common neurosurgical emergency, with increasing incidence in aging populations. Rapid and accurate identification is essential to guide timely intervention, yet existing automated tools focus primarily on detection and provide limited interpretability or spatial localization. There remains a need for transparent, high-performing systems that integrate multimodal clinical and imaging information to support real-time decision-making. Methods. We developed a multimodal deep-learning framework that integrates structured clinical variables, a 3D convolutional neural network trained on CT volumes, and a transformer-enhanced 2D segmentation model for SDH detection and localization. Using 25,315 head CT studies from Hartford HealthCare (2015--2024), of which 3,774 (14.9\%) contained clinician-confirmed SDH, tabular models were trained on demographics, comorbidities, medications, and laboratory results. Imaging models were trained to detect SDH and generate voxel-level probability maps. A greedy ensemble strategy combined complementary predictors. Findings. Clinical variables alone provided modest discriminatory power (AUC 0.75). Convolutional models trained on CT volumes and segmentation-derived maps achieved substantially higher accuracy (AUCs 0.922 and 0.926). The multimodal ensemble integrating all components achieved the best overall performance (AUC 0.9407; 95\% CI, 0.930--0.951) and produced anatomically meaningful localization maps consistent with known SDH patterns. Interpretation. This multimodal, interpretable framework provides rapid and accurate SDH detection and localization, achieving high detection performance and offering transparent, anatomically grounded outputs. Integration into radiology workflows could streamline triage, reduce time to intervention, and improve consistency in SDH management.
Towards Optimal Valve Prescription for Transcatheter Aortic Valve Replacement (TAVR) Surgery: A Machine Learning Approach
Dec 09, 2025Transcatheter Aortic Valve Replacement (TAVR) has emerged as a minimally invasive treatment option for patients with severe aortic stenosis, a life-threatening cardiovascular condition. Multiple transcatheter heart valves (THV) have been approved for use in TAVR, but current guidelines regarding valve type prescription remain an active topic of debate. We propose a data-driven clinical support tool to identify the optimal valve type with the objective of minimizing the risk of permanent pacemaker implantation (PPI), a predominant postoperative complication. We synthesize a novel dataset that combines U.S. and Greek patient populations and integrates three distinct data sources (patient demographics, computed tomography scans, echocardiograms) while harmonizing differences in each country's record system. We introduce a leaf-level analysis to leverage population heterogeneity and avoid benchmarking against uncertain counterfactual risk estimates. The final prescriptive model shows a reduction in PPI rates of 26% and 16% compared with the current standard of care in our internal U.S. population and external Greek validation cohort, respectively. To the best of our knowledge, this work represents the first unified, personalized prescription strategy for THV selection in TAVR.
Multimodal Prescriptive Deep Learning
Jan 24, 2025



We introduce a multimodal deep learning framework, Prescriptive Neural Networks (PNNs), that combines ideas from optimization and machine learning, and is, to the best of our knowledge, the first prescriptive method to handle multimodal data. The PNN is a feedforward neural network trained on embeddings to output an outcome-optimizing prescription. In two real-world multimodal datasets, we demonstrate that PNNs prescribe treatments that are able to significantly improve estimated outcomes in transcatheter aortic valve replacement (TAVR) procedures by reducing estimated postoperative complication rates by 32% and in liver trauma injuries by reducing estimated mortality rates by over 40%. In four real-world, unimodal tabular datasets, we demonstrate that PNNs outperform or perform comparably to other well-known, state-of-the-art prescriptive models; importantly, on tabular datasets, we also recover interpretability through knowledge distillation, fitting interpretable Optimal Classification Tree models onto the PNN prescriptions as classification targets, which is critical for many real-world applications. Finally, we demonstrate that our multimodal PNN models achieve stability across randomized data splits comparable to other prescriptive methods and produce realistic prescriptions across the different datasets.
Deep Trees for (Un)structured Data: Tractability, Performance, and Interpretability
Oct 28, 2024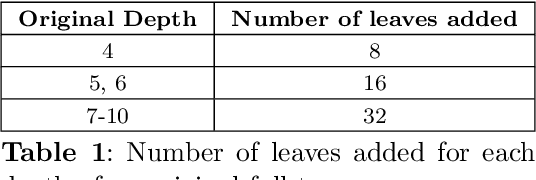
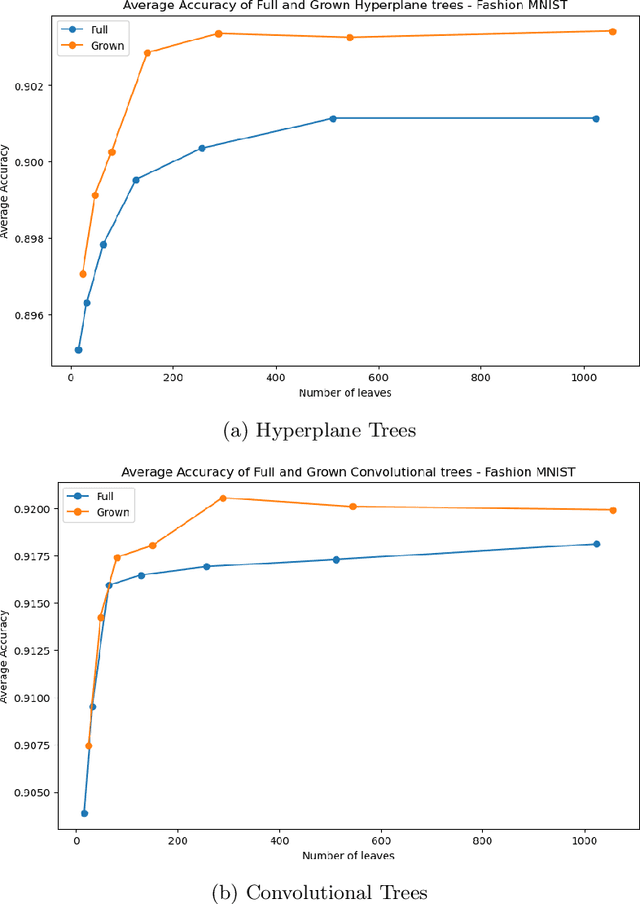
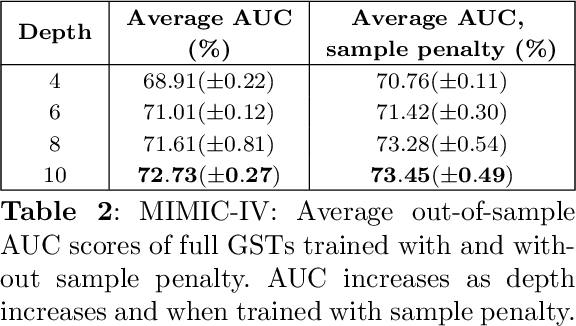
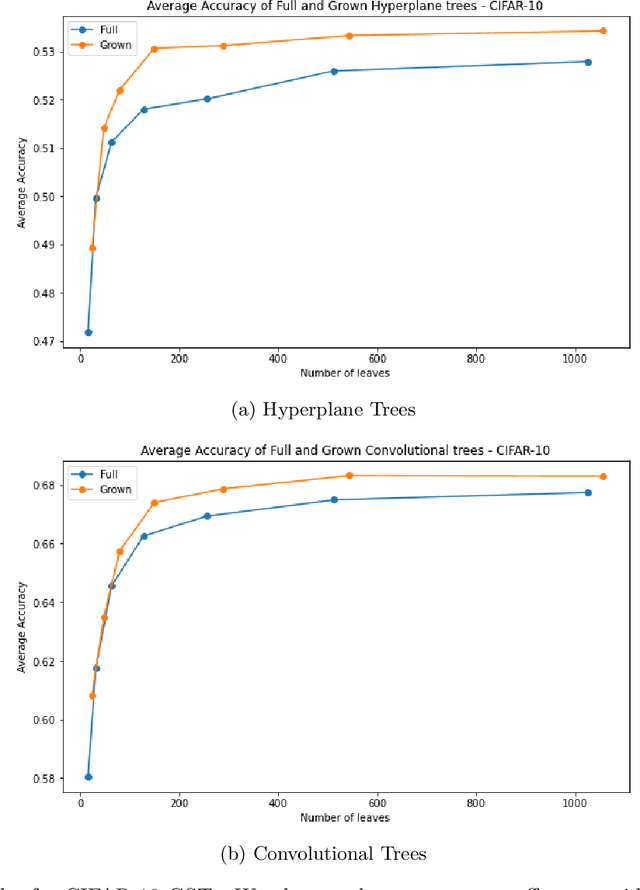
Decision Trees have remained a popular machine learning method for tabular datasets, mainly due to their interpretability. However, they lack the expressiveness needed to handle highly nonlinear or unstructured datasets. Motivated by recent advances in tree-based machine learning (ML) techniques and first-order optimization methods, we introduce Generalized Soft Trees (GSTs), which extend soft decision trees (STs) and are capable of processing images directly. We demonstrate their advantages with respect to tractability, performance, and interpretability. We develop a tractable approach to growing GSTs, given by the DeepTree algorithm, which, in addition to new regularization terms, produces high-quality models with far fewer nodes and greater interpretability than traditional soft trees. We test the performance of our GSTs on benchmark tabular and image datasets, including MIMIC-IV, MNIST, Fashion MNIST, CIFAR-10 and Celeb-A. We show that our approach outperforms other popular tree methods (CART, Random Forests, XGBoost) in almost all of the datasets, with Convolutional Trees having a significant edge in the hardest CIFAR-10 and Fashion MNIST datasets. Finally, we explore the interpretability of our GSTs and find that even the most complex GSTs are considerably more interpretable than deep neural networks. Overall, our approach of Generalized Soft Trees provides a tractable method that is high-performing on (un)structured datasets and preserves interpretability more than traditional deep learning methods.
Binary Classification: Is Boosting stronger than Bagging?
Oct 24, 2024



Random Forests have been one of the most popular bagging methods in the past few decades, especially due to their success at handling tabular datasets. They have been extensively studied and compared to boosting models, like XGBoost, which are generally considered more performant. Random Forests adopt several simplistic assumptions, such that all samples and all trees that form the forest are equally important for building the final model. We introduce Enhanced Random Forests, an extension of vanilla Random Forests with extra functionalities and adaptive sample and model weighting. We develop an iterative algorithm for adapting the training sample weights, by favoring the hardest examples, and an approach for finding personalized tree weighting schemes for each new sample. Our method significantly improves upon regular Random Forests across 15 different binary classification datasets and considerably outperforms other tree methods, including XGBoost, when run with default hyperparameters, which indicates the robustness of our approach across datasets, without the need for extensive hyperparameter tuning. Our tree-weighting methodology results in enhanced or comparable performance to the uniformly weighted ensemble, and is, more importantly, leveraged to define importance scores for trees based on their contributions to classifying each new sample. This enables us to only focus on a small number of trees as the main models that define the outcome of a new sample and, thus, to partially recover interpretability, which is critically missing from both bagging and boosting methods. In binary classification problems, the proposed extensions and the corresponding results suggest the equivalence of bagging and boosting methods in performance, and the edge of bagging in interpretability by leveraging a few learners of the ensemble, which is not an option in the less explainable boosting methods.