 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLED: Self Logits Evolution Decoding for Improving Factuality in Large Language Models
Nov 01, 2024



Large language models (LLMs) have demonstrated remarkable capabilities, but their outputs can sometimes be unreliable or factually incorrect. To address this, we introduce Self Logits Evolution Decoding (SLED), a novel decoding framework that enhances the truthfulness of LLMs without relying on external knowledge bases or requiring further fine-tuning. From an optimization perspective, our SLED framework leverages the latent knowledge embedded within the LLM by contrasting the output logits from the final layer with those from early layers. It then utilizes an approximate gradient approach to enable latent knowledge to guide the self-refinement of outputs, thereby effectively improving factual accuracy. Extensive experiments have been conducted on established benchmarks across a diverse range of model families (LLaMA 2, LLaMA 3, Gemma) and scales (from 2B to 70B), including more advanced architectural configurations such as the mixture of experts (MoE). Our evaluation spans a wide variety of tasks, including multi-choice, open-generation, and adaptations to chain-of-thought reasoning tasks. The results demonstrate that SLED consistently improves factual accuracy by up to 20\% compared to existing decoding methods while maintaining natural language fluency and negligible latency overhead. Furthermore, it can be flexibly combined with other decoding methods to further enhance their performance.
SpacTor-T5: Pre-training T5 Models with Span Corruption and Replaced Token Detection
Jan 24, 2024Pre-training large language models is known to be extremely resource intensive and often times inefficient, under-utilizing the information encapsulated in the training text sequences. In this paper, we present SpacTor, a new training procedure consisting of (1) a hybrid objective combining span corruption (SC) and token replacement detection (RTD), and (2) a two-stage curriculum that optimizes the hybrid objective over the initial $\tau$ iterations, then transitions to standard SC loss. We show empirically that the effectiveness of the hybrid objective is tied to the two-stage pre-training schedule, and provide extensive analysis on why this is the case. In our experiments with encoder-decoder architectures (T5) on a variety of NLP tasks, SpacTor-T5 yields the same downstream performance as standard SC pre-training, while enabling a 50% reduction in pre-training iterations and 40% reduction in total FLOPs. Alternatively, given the same amount of computing budget, we find that SpacTor results in significantly improved downstream benchmark performance.
Is margin all you need? An extensive empirical study of active learning on tabular data
Oct 07, 2022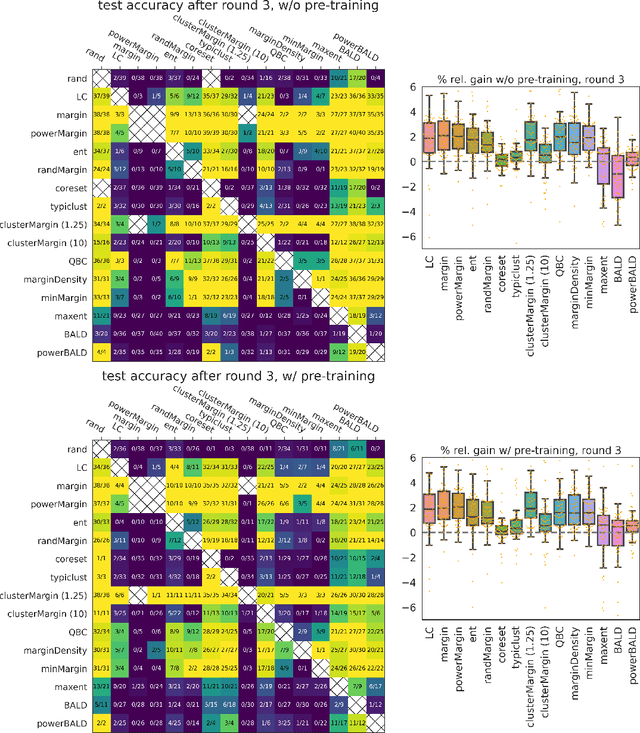
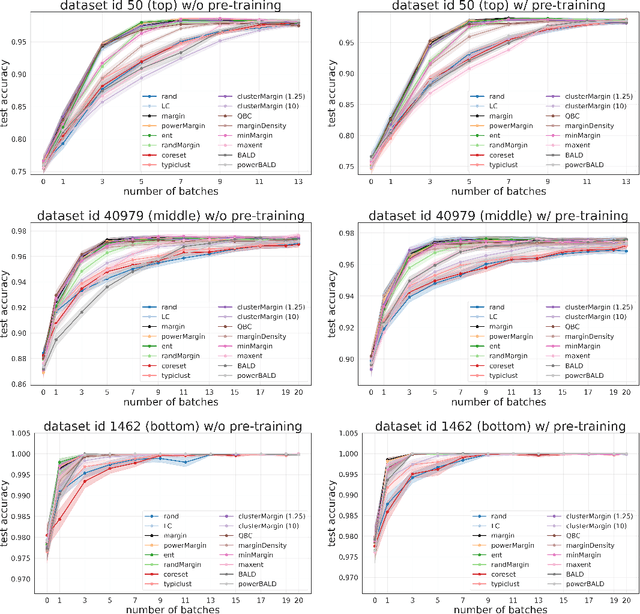
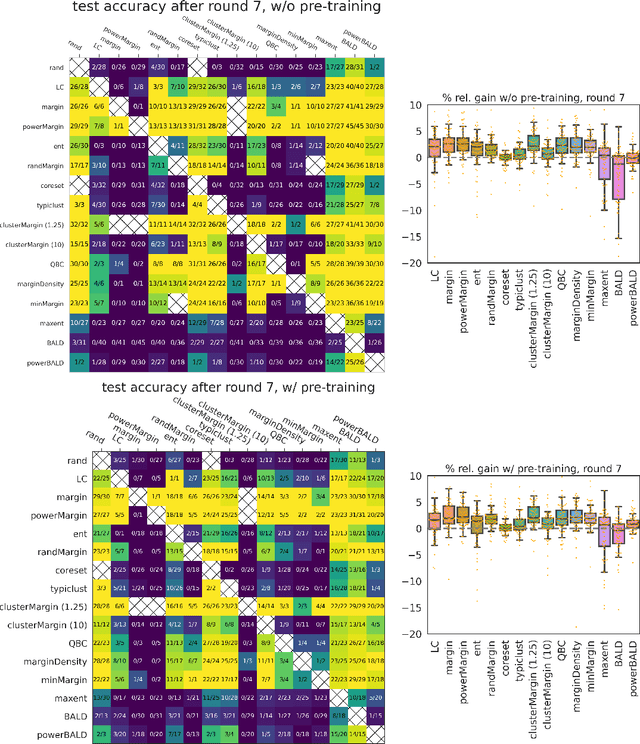
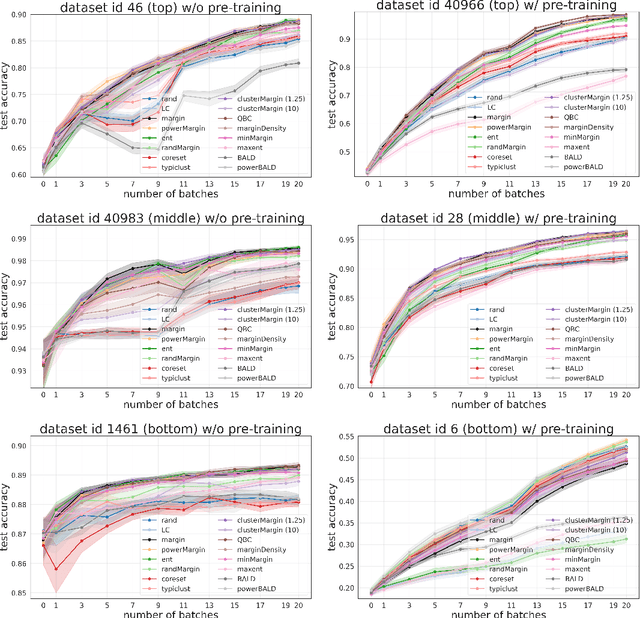
Given a labeled training set and a collection of unlabeled data, the goal of active learning (AL) is to identify the best unlabeled points to label. In this comprehensive study, we analyze the performance of a variety of AL algorithms on deep neural networks trained on 69 real-world tabular classification datasets from the OpenML-CC18 benchmark. We consider different data regimes and the effect of self-supervised model pre-training. Surprisingly, we find that the classical margin sampling technique matches or outperforms all others, including current state-of-art, in a wide range of experimental settings. To researchers, we hope to encourage rigorous benchmarking against margin, and to practitioners facing tabular data labeling constraints that hyper-parameter-free margin may often be all they need.
Predicting on the Edge: Identifying Where a Larger Model Does Better
Feb 15, 2022



Much effort has been devoted to making large and more accurate models, but relatively little has been put into understanding which examples are benefiting from the added complexity. In this paper, we demonstrate and analyze the surprisingly tight link between a model's predictive uncertainty on individual examples and the likelihood that larger models will improve prediction on them. Through extensive numerical studies on the T5 encoder-decoder architecture, we show that large models have the largest improvement on examples where the small model is most uncertain. On more certain examples, even those where the small model is not particularly accurate, large models are often unable to improve at all, and can even perform worse than the smaller model. Based on these findings, we show that a switcher model which defers examples to a larger model when a small model is uncertain can achieve striking improvements in performance and resource usage. We also explore committee-based uncertainty metrics that can be more effective but less practical.
SCARF: Self-Supervised Contrastive Learning using Random Feature Corruption
Jun 29, 2021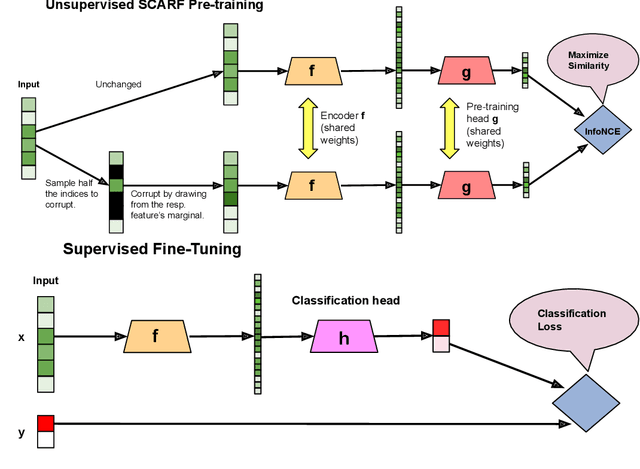
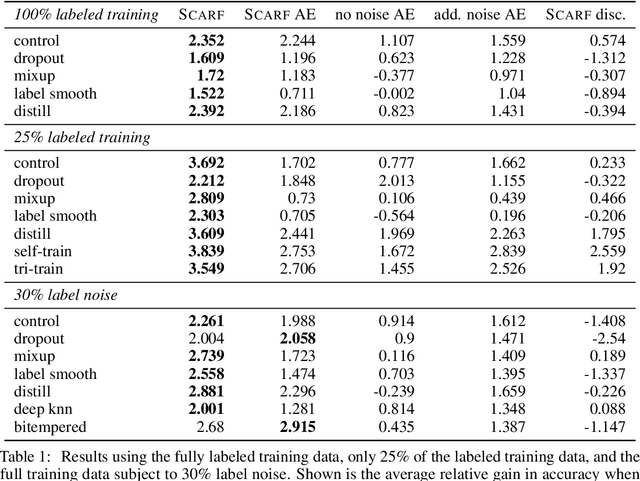
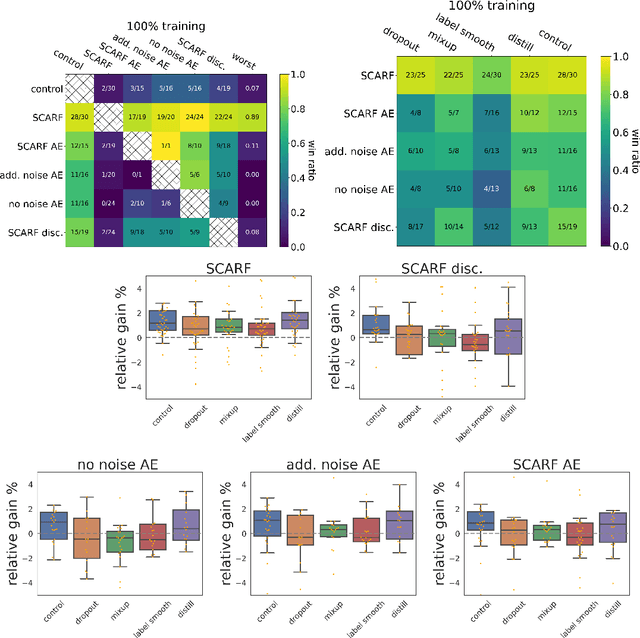
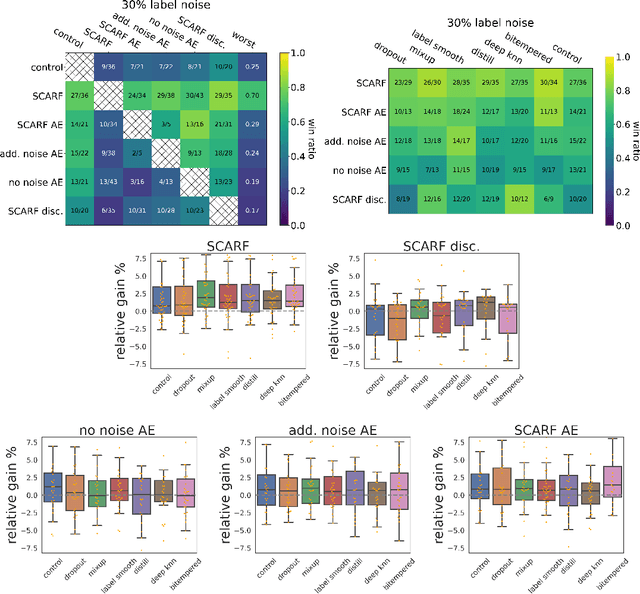
Self-supervised contrastive representation learning has proved incredibly successful in the vision and natural language domains, enabling state-of-the-art performance with orders of magnitude less labeled data. However, such methods are domain-specific and little has been done to leverage this technique on real-world tabular datasets. We propose SCARF, a simple, widely-applicable technique for contrastive learning, where views are formed by corrupting a random subset of features. When applied to pre-train deep neural networks on the 69 real-world, tabular classification datasets from the OpenML-CC18 benchmark, SCARF not only improves classification accuracy in the fully-supervised setting but does so also in the presence of label noise and in the semi-supervised setting where only a fraction of the available training data is labeled. We show that SCARF complements existing strategies and outperforms alternatives like autoencoders. We conduct comprehensive ablations, detailing the importance of a range of factors.
Churn Reduction via Distillation
Jun 04, 2021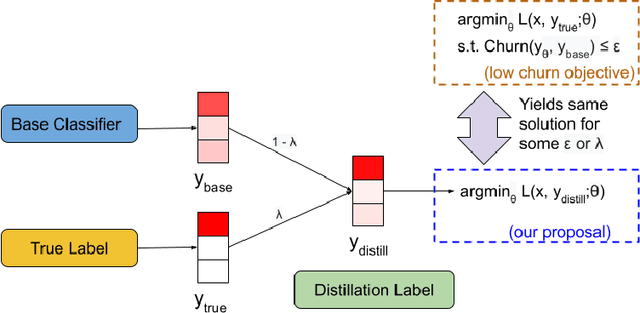

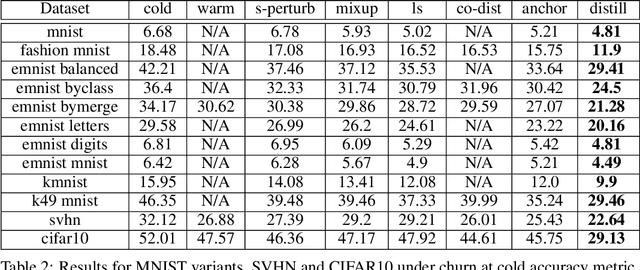
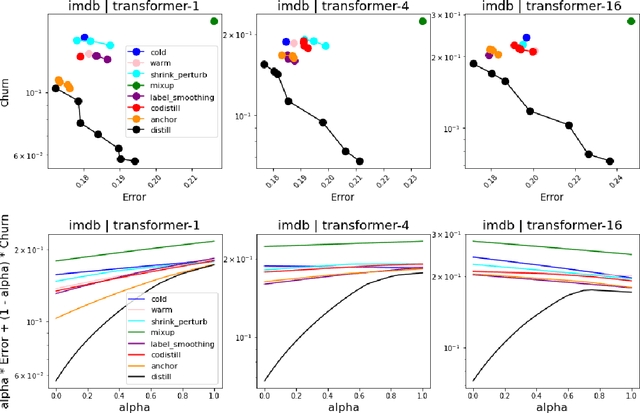
In real-world systems, models are frequently updated as more data becomes available, and in addition to achieving high accuracy, the goal is to also maintain a low difference in predictions compared to the base model (i.e. predictive ``churn''). If model retraining results in vastly different behavior, then it could cause negative effects in downstream systems, especially if this churn can be avoided with limited impact on model accuracy. In this paper, we show an equivalence between training with distillation using the base model as the teacher and training with an explicit constraint on the predictive churn. We then show that distillation performs strongly for low churn training against a number of recent baselines on a wide range of datasets and model architectures, including fully-connected networks, convolutional networks, and transformers.
Active Covering
Jun 04, 2021
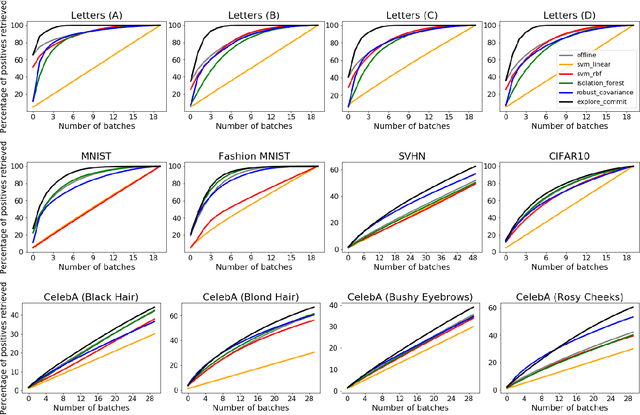

We analyze the problem of active covering, where the learner is given an unlabeled dataset and can sequentially label query examples. The objective is to label query all of the positive examples in the fewest number of total label queries. We show under standard non-parametric assumptions that a classical support estimator can be repurposed as an offline algorithm attaining an excess query cost of $\widetilde{\Theta}(n^{D/(D+1)})$ compared to the optimal learner, where $n$ is the number of datapoints and $D$ is the dimension. We then provide a simple active learning method that attains an improved excess query cost of $\widetilde{O}(n^{(D-1)/D})$. Furthermore, the proposed algorithms only require access to the positive labeled examples, which in certain settings provides additional computational and privacy benefits. Finally, we show that the active learning method consistently outperforms offline methods as well as a variety of baselines on a wide range of benchmark image-based datasets.
MeanShift++: Extremely Fast Mode-Seeking With Applications to Segmentation and Object Tracking
Apr 01, 2021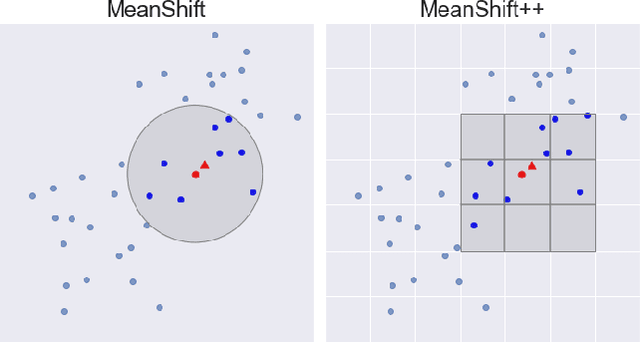
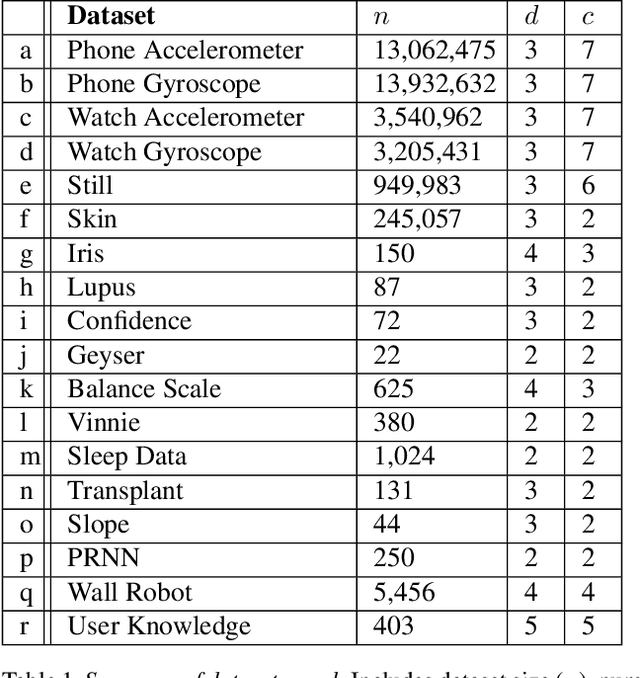
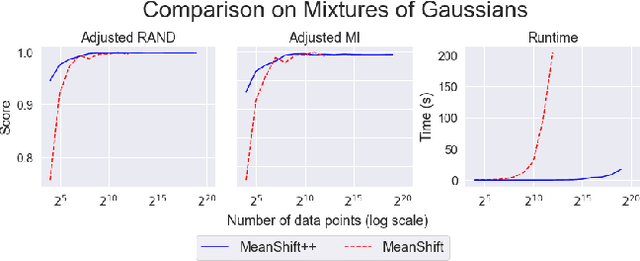
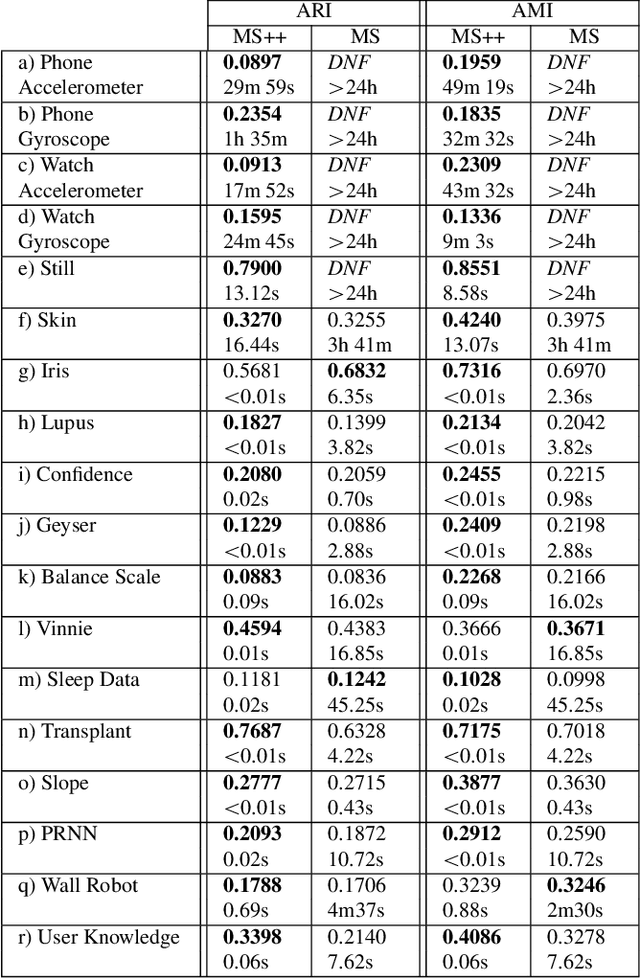
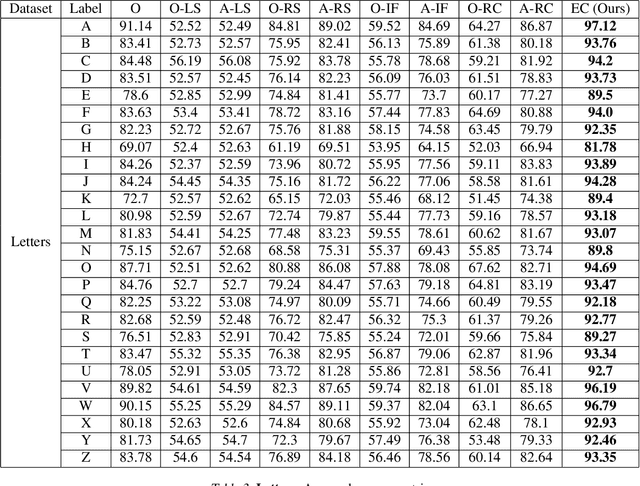
MeanShift is a popular mode-seeking clustering algorithm used in a wide range of applications in machine learning. However, it is known to be prohibitively slow, with quadratic runtime per iteration. We propose MeanShift++, an extremely fast mode-seeking algorithm based on MeanShift that uses a grid-based approach to speed up the mean shift step, replacing the computationally expensive neighbors search with a density-weighted mean of adjacent grid cells. In addition, we show that this grid-based technique for density estimation comes with theoretical guarantees. The runtime is linear in the number of points and exponential in dimension, which makes MeanShift++ ideal on low-dimensional applications such as image segmentation and object tracking. We provide extensive experimental analysis showing that MeanShift++ can be more than 10,000x faster than MeanShift with competitive clustering results on benchmark datasets and nearly identical image segmentations as MeanShift. Finally, we show promising results for object tracking.
Locally Adaptive Label Smoothing for Predictive Churn
Feb 09, 2021
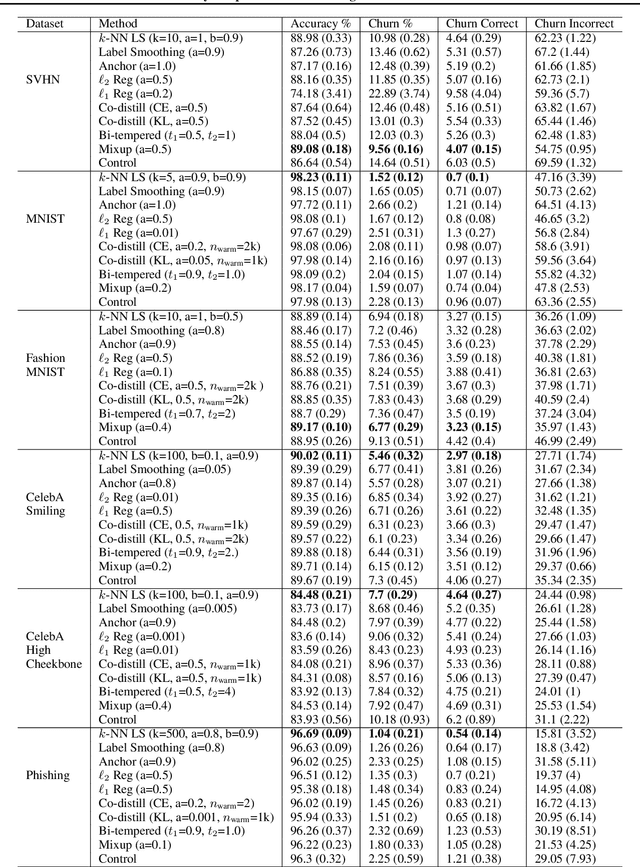
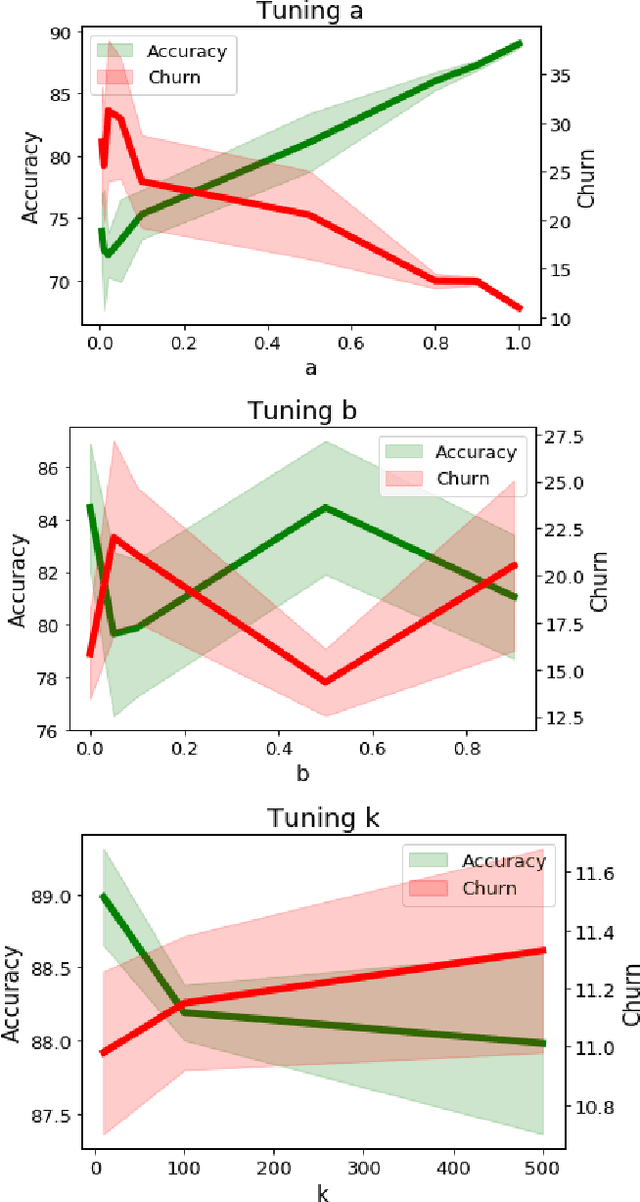
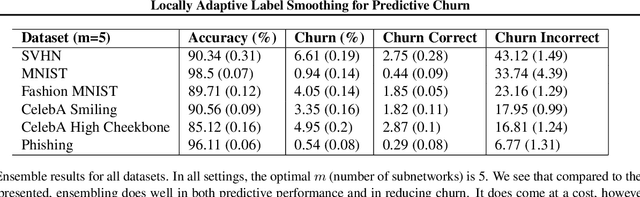
Training modern neural networks is an inherently noisy process that can lead to high \emph{prediction churn} -- disagreements between re-trainings of the same model due to factors such as randomization in the parameter initialization and mini-batches -- even when the trained models all attain similar accuracies. Such prediction churn can be very undesirable in practice. In this paper, we present several baselines for reducing churn and show that training on soft labels obtained by adaptively smoothing each example's label based on the example's neighboring labels often outperforms the baselines on churn while improving accuracy on a variety of benchmark classification tasks and model architectures.
Label Smoothed Embedding Hypothesis for Out-of-Distribution Detection
Feb 09, 2021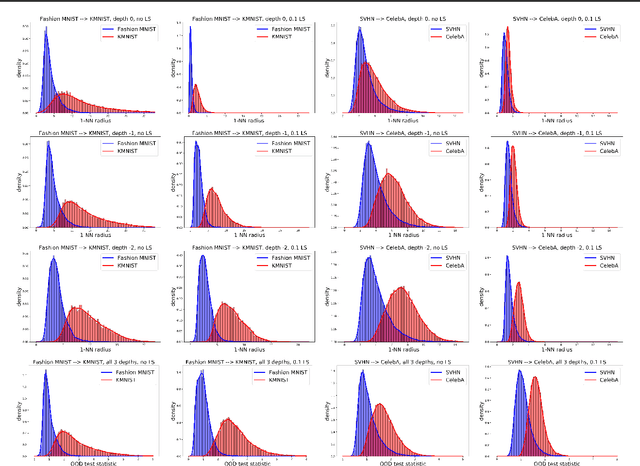
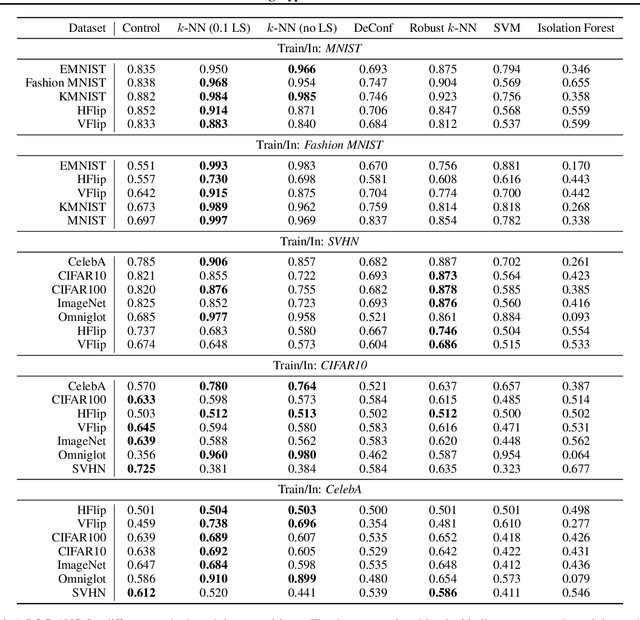
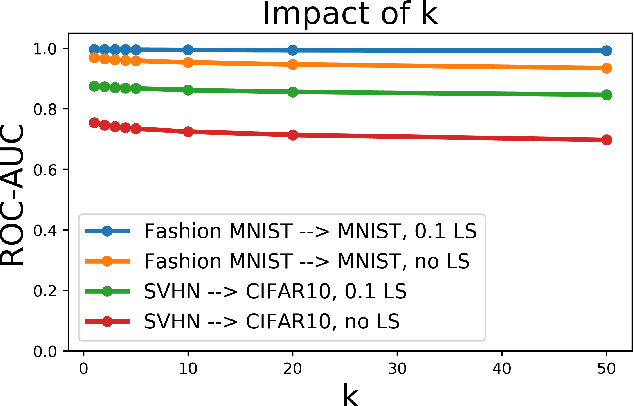
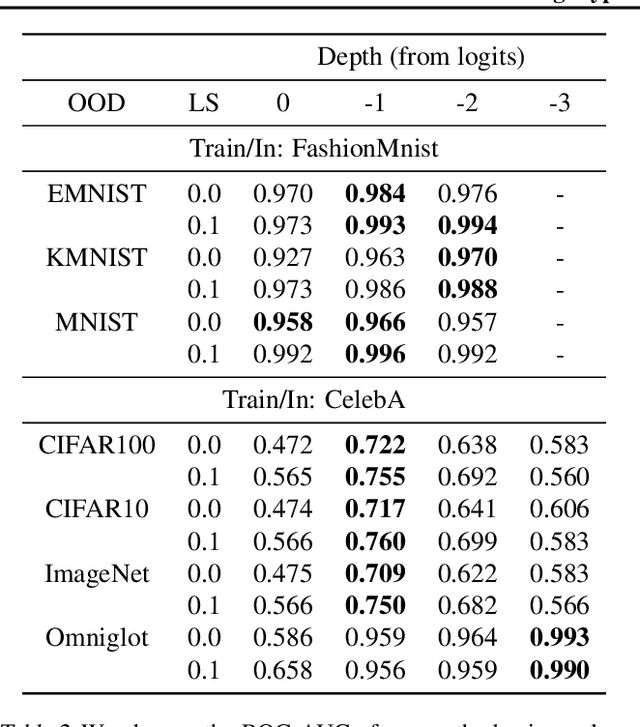
Detecting out-of-distribution (OOD) examples is critical in many applications. We propose an unsupervised method to detect OOD samples using a $k$-NN density estimate with respect to a classification model's intermediate activations on in-distribution samples. We leverage a recent insight about label smoothing, which we call the \emph{Label Smoothed Embedding Hypothesis}, and show that one of the implications is that the $k$-NN density estimator performs better as an OOD detection method both theoretically and empirically when the model is trained with label smoothing. Finally, we show that our proposal outperforms many OOD baselines and also provide new finite-sample high-probability statistical results for $k$-NN density estimation's ability to detect OOD examples.