 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEthical and social risks of harm from Language Models
Dec 08, 2021
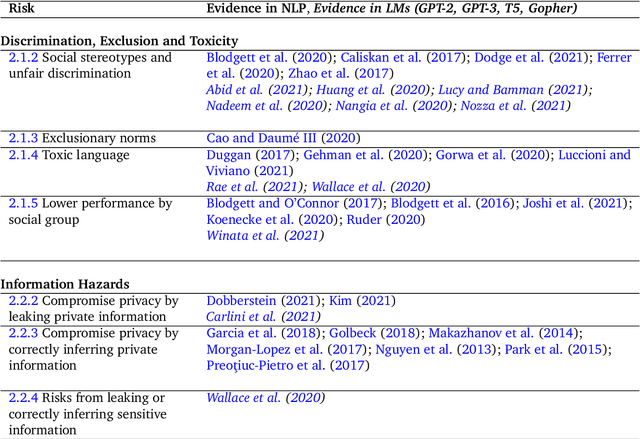
This paper aims to help structure the risk landscape associated with large-scale Language Models (LMs). In order to foster advances in responsible innovation, an in-depth understanding of the potential risks posed by these models is needed. A wide range of established and anticipated risks are analysed in detail, drawing on multidisciplinary expertise and literature from computer science, linguistics, and social sciences. We outline six specific risk areas: I. Discrimination, Exclusion and Toxicity, II. Information Hazards, III. Misinformation Harms, V. Malicious Uses, V. Human-Computer Interaction Harms, VI. Automation, Access, and Environmental Harms. The first area concerns the perpetuation of stereotypes, unfair discrimination, exclusionary norms, toxic language, and lower performance by social group for LMs. The second focuses on risks from private data leaks or LMs correctly inferring sensitive information. The third addresses risks arising from poor, false or misleading information including in sensitive domains, and knock-on risks such as the erosion of trust in shared information. The fourth considers risks from actors who try to use LMs to cause harm. The fifth focuses on risks specific to LLMs used to underpin conversational agents that interact with human users, including unsafe use, manipulation or deception. The sixth discusses the risk of environmental harm, job automation, and other challenges that may have a disparate effect on different social groups or communities. In total, we review 21 risks in-depth. We discuss the points of origin of different risks and point to potential mitigation approaches. Lastly, we discuss organisational responsibilities in implementing mitigations, and the role of collaboration and participation. We highlight directions for further research, particularly on expanding the toolkit for assessing and evaluating the outlined risks in LMs.
Counterfactual Credit Assignment in Model-Free Reinforcement Learning
Nov 18, 2020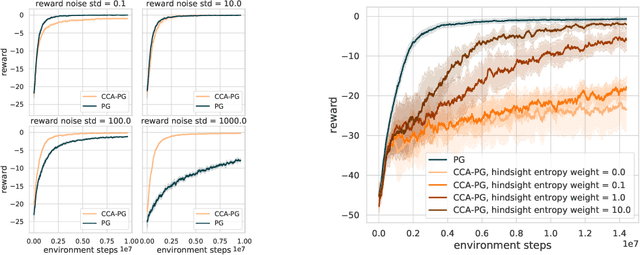
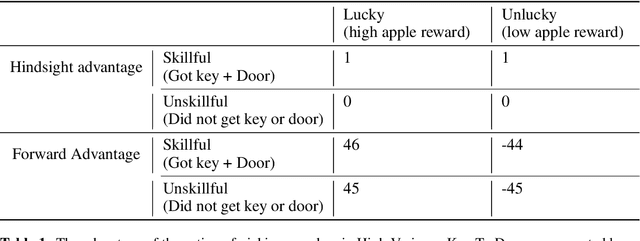

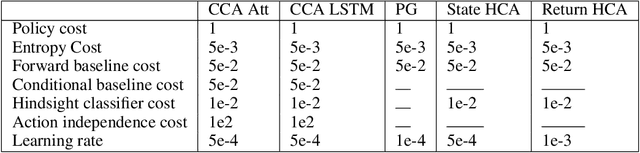
Credit assignment in reinforcement learning is the problem of measuring an action influence on future rewards. In particular, this requires separating skill from luck, ie. disentangling the effect of an action on rewards from that of external factors and subsequent actions. To achieve this, we adapt the notion of counterfactuals from causality theory to a model-free RL setup. The key idea is to condition value functions on future events, by learning to extract relevant information from a trajectory. We then propose to use these as future-conditional baselines and critics in policy gradient algorithms and we develop a valid, practical variant with provably lower variance, while achieving unbiasedness by constraining the hindsight information not to contain information about the agent actions. We demonstrate the efficacy and validity of our algorithm on a number of illustrative problems.
Wasserstein Fair Classification
Jul 28, 2019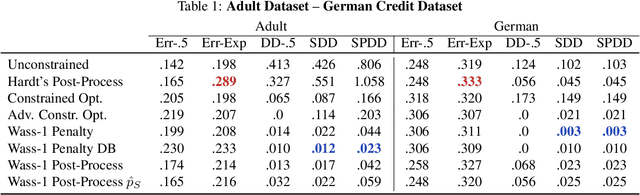
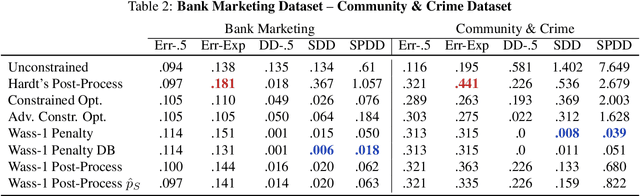
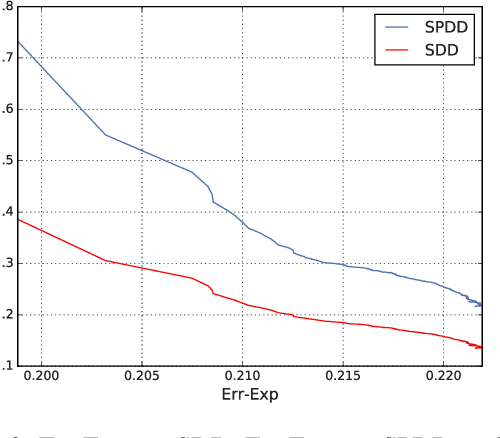
We propose an approach to fair classification that enforces independence between the classifier outputs and sensitive information by minimizing Wasserstein-1 distances. The approach has desirable theoretical properties and is robust to specific choices of the threshold used to obtain class predictions from model outputs. We introduce different methods that enable hiding sensitive information at test time or have a simple and fast implementation. We show empirical performance against different fairness baselines on several benchmark fairness datasets.
Safe and Efficient Off-Policy Reinforcement Learning
Nov 07, 2016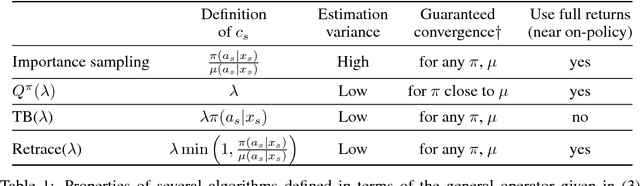
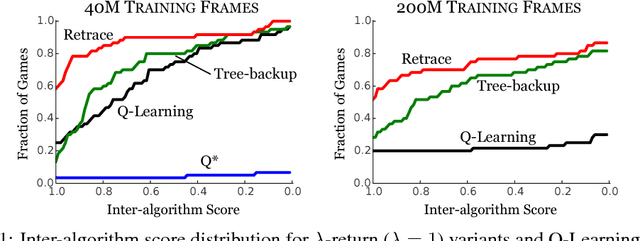
In this work, we take a fresh look at some old and new algorithms for off-policy, return-based reinforcement learning. Expressing these in a common form, we derive a novel algorithm, Retrace($\lambda$), with three desired properties: (1) it has low variance; (2) it safely uses samples collected from any behaviour policy, whatever its degree of "off-policyness"; and (3) it is efficient as it makes the best use of samples collected from near on-policy behaviour policies. We analyze the contractive nature of the related operator under both off-policy policy evaluation and control settings and derive online sample-based algorithms. We believe this is the first return-based off-policy control algorithm converging a.s. to $Q^*$ without the GLIE assumption (Greedy in the Limit with Infinite Exploration). As a corollary, we prove the convergence of Watkins' Q($\lambda$), which was an open problem since 1989. We illustrate the benefits of Retrace($\lambda$) on a standard suite of Atari 2600 games.
Q($λ$) with Off-Policy Corrections
Aug 11, 2016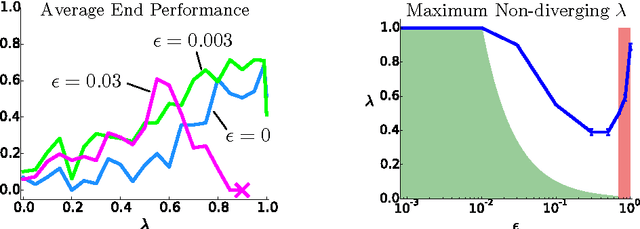
We propose and analyze an alternate approach to off-policy multi-step temporal difference learning, in which off-policy returns are corrected with the current Q-function in terms of rewards, rather than with the target policy in terms of transition probabilities. We prove that such approximate corrections are sufficient for off-policy convergence both in policy evaluation and control, provided certain conditions. These conditions relate the distance between the target and behavior policies, the eligibility trace parameter and the discount factor, and formalize an underlying tradeoff in off-policy TD($\lambda$). We illustrate this theoretical relationship empirically on a continuous-state control task.