 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEthical and social risks of harm from Language Models
Paper and Code

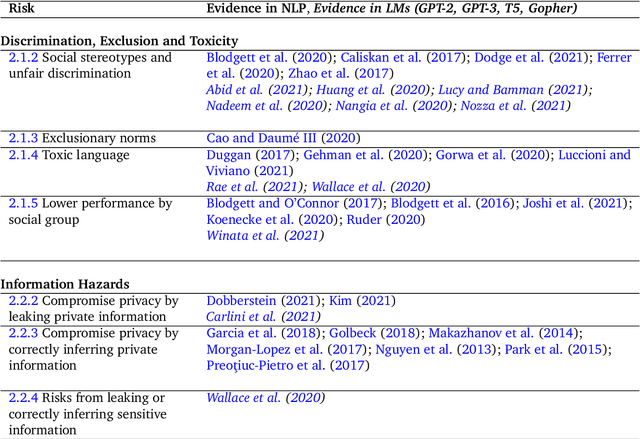
This paper aims to help structure the risk landscape associated with large-scale Language Models (LMs). In order to foster advances in responsible innovation, an in-depth understanding of the potential risks posed by these models is needed. A wide range of established and anticipated risks are analysed in detail, drawing on multidisciplinary expertise and literature from computer science, linguistics, and social sciences. We outline six specific risk areas: I. Discrimination, Exclusion and Toxicity, II. Information Hazards, III. Misinformation Harms, V. Malicious Uses, V. Human-Computer Interaction Harms, VI. Automation, Access, and Environmental Harms. The first area concerns the perpetuation of stereotypes, unfair discrimination, exclusionary norms, toxic language, and lower performance by social group for LMs. The second focuses on risks from private data leaks or LMs correctly inferring sensitive information. The third addresses risks arising from poor, false or misleading information including in sensitive domains, and knock-on risks such as the erosion of trust in shared information. The fourth considers risks from actors who try to use LMs to cause harm. The fifth focuses on risks specific to LLMs used to underpin conversational agents that interact with human users, including unsafe use, manipulation or deception. The sixth discusses the risk of environmental harm, job automation, and other challenges that may have a disparate effect on different social groups or communities. In total, we review 21 risks in-depth. We discuss the points of origin of different risks and point to potential mitigation approaches. Lastly, we discuss organisational responsibilities in implementing mitigations, and the role of collaboration and participation. We highlight directions for further research, particularly on expanding the toolkit for assessing and evaluating the outlined risks in LMs.