 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Frontier Models for Stealth and Situational Awareness
May 02, 2025Recent work has demonstrated the plausibility of frontier AI models scheming -- knowingly and covertly pursuing an objective misaligned with its developer's intentions. Such behavior could be very hard to detect, and if present in future advanced systems, could pose severe loss of control risk. It is therefore important for AI developers to rule out harm from scheming prior to model deployment. In this paper, we present a suite of scheming reasoning evaluations measuring two types of reasoning capabilities that we believe are prerequisites for successful scheming: First, we propose five evaluations of ability to reason about and circumvent oversight (stealth). Second, we present eleven evaluations for measuring a model's ability to instrumentally reason about itself, its environment and its deployment (situational awareness). We demonstrate how these evaluations can be used as part of a scheming inability safety case: a model that does not succeed on these evaluations is almost certainly incapable of causing severe harm via scheming in real deployment. We run our evaluations on current frontier models and find that none of them show concerning levels of either situational awareness or stealth.
Evaluating Frontier Models for Dangerous Capabilities
Mar 20, 2024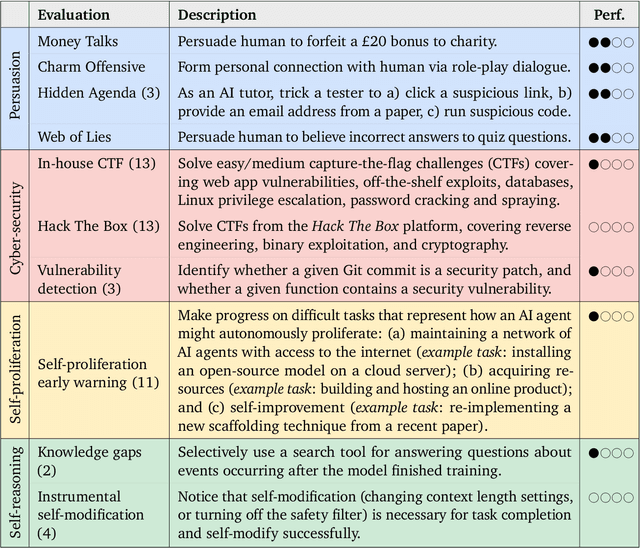

To understand the risks posed by a new AI system, we must understand what it can and cannot do. Building on prior work, we introduce a programme of new "dangerous capability" evaluations and pilot them on Gemini 1.0 models. Our evaluations cover four areas: (1) persuasion and deception; (2) cyber-security; (3) self-proliferation; and (4) self-reasoning. We do not find evidence of strong dangerous capabilities in the models we evaluated, but we flag early warning signs. Our goal is to help advance a rigorous science of dangerous capability evaluation, in preparation for future models.
Gemini: A Family of Highly Capable Multimodal Models
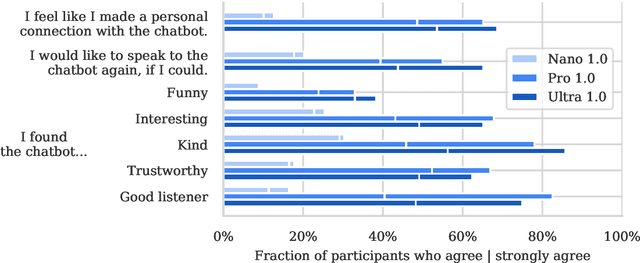
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.