 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Frontier Models for Dangerous Capabilities
Mar 20, 2024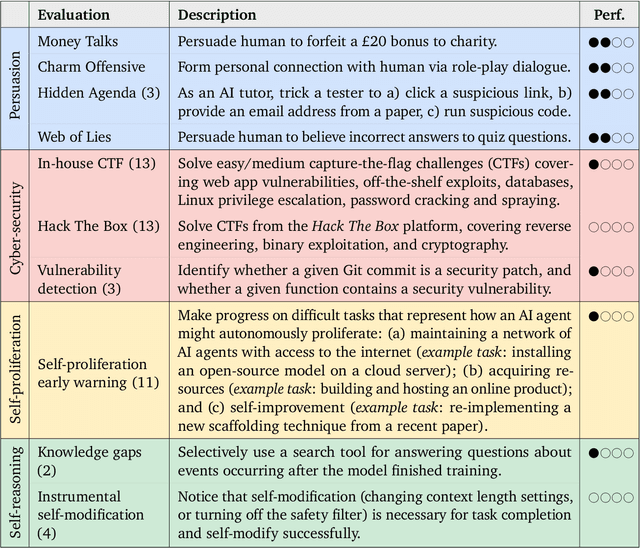
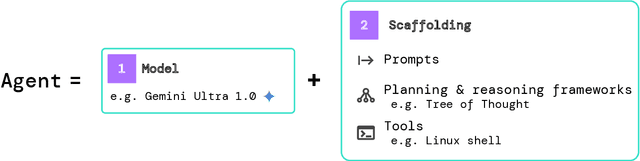

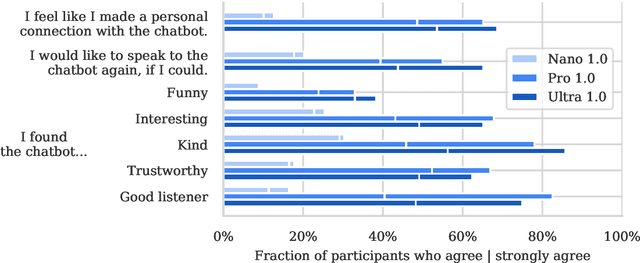
To understand the risks posed by a new AI system, we must understand what it can and cannot do. Building on prior work, we introduce a programme of new "dangerous capability" evaluations and pilot them on Gemini 1.0 models. Our evaluations cover four areas: (1) persuasion and deception; (2) cyber-security; (3) self-proliferation; and (4) self-reasoning. We do not find evidence of strong dangerous capabilities in the models we evaluated, but we flag early warning signs. Our goal is to help advance a rigorous science of dangerous capability evaluation, in preparation for future models.
Learning Universal Predictors
Jan 26, 2024



Meta-learning has emerged as a powerful approach to train neural networks to learn new tasks quickly from limited data. Broad exposure to different tasks leads to versatile representations enabling general problem solving. But, what are the limits of meta-learning? In this work, we explore the potential of amortizing the most powerful universal predictor, namely Solomonoff Induction (SI), into neural networks via leveraging meta-learning to its limits. We use Universal Turing Machines (UTMs) to generate training data used to expose networks to a broad range of patterns. We provide theoretical analysis of the UTM data generation processes and meta-training protocols. We conduct comprehensive experiments with neural architectures (e.g. LSTMs, Transformers) and algorithmic data generators of varying complexity and universality. Our results suggest that UTM data is a valuable resource for meta-learning, and that it can be used to train neural networks capable of learning universal prediction strategies.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Distributional Bellman Operators over Mean Embeddings
Dec 09, 2023We propose a novel algorithmic framework for distributional reinforcement learning, based on learning finite-dimensional mean embeddings of return distributions. We derive several new algorithms for dynamic programming and temporal-difference learning based on this framework, provide asymptotic convergence theory, and examine the empirical performance of the algorithms on a suite of tabular tasks. Further, we show that this approach can be straightforwardly combined with deep reinforcement learning, and obtain a new deep RL agent that improves over baseline distributional approaches on the Arcade Learning Environment.
Language Modeling Is Compression
Sep 19, 2023It has long been established that predictive models can be transformed into lossless compressors and vice versa. Incidentally, in recent years, the machine learning community has focused on training increasingly large and powerful self-supervised (language) models. Since these large language models exhibit impressive predictive capabilities, they are well-positioned to be strong compressors. In this work, we advocate for viewing the prediction problem through the lens of compression and evaluate the compression capabilities of large (foundation) models. We show that large language models are powerful general-purpose predictors and that the compression viewpoint provides novel insights into scaling laws, tokenization, and in-context learning. For example, Chinchilla 70B, while trained primarily on text, compresses ImageNet patches to 43.4% and LibriSpeech samples to 16.4% of their raw size, beating domain-specific compressors like PNG (58.5%) or FLAC (30.3%), respectively. Finally, we show that the prediction-compression equivalence allows us to use any compressor (like gzip) to build a conditional generative model.
Atari-5: Distilling the Arcade Learning Environment down to Five Games
Oct 05, 2022
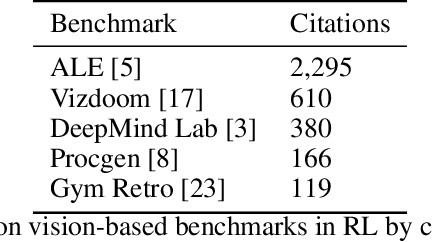

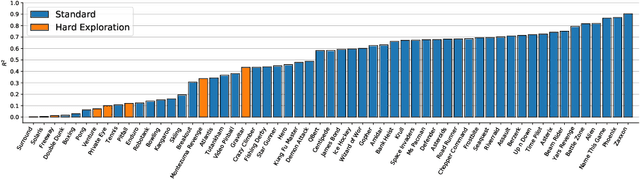
The Arcade Learning Environment (ALE) has become an essential benchmark for assessing the performance of reinforcement learning algorithms. However, the computational cost of generating results on the entire 57-game dataset limits ALE's use and makes the reproducibility of many results infeasible. We propose a novel solution to this problem in the form of a principled methodology for selecting small but representative subsets of environments within a benchmark suite. We applied our method to identify a subset of five ALE games, called Atari-5, which produces 57-game median score estimates within 10% of their true values. Extending the subset to 10-games recovers 80% of the variance for log-scores for all games within the 57-game set. We show this level of compression is possible due to a high degree of correlation between many of the games in ALE.
Optimal Use of Experience in First Person Shooter Environments
Jun 24, 2019


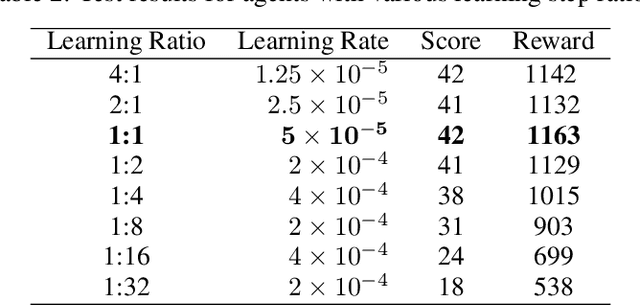
Although reinforcement learning has made great strides recently, a continuing limitation is that it requires an extremely high number of interactions with the environment. In this paper, we explore the effectiveness of reusing experience from the experience replay buffer in the Deep Q-Learning algorithm. We test the effectiveness of applying learning update steps multiple times per environmental step in the VizDoom environment and show first, this requires a change in the learning rate, and second that it does not improve the performance of the agent. Furthermore, we show that updating less frequently is effective up to a ratio of 4:1, after which performance degrades significantly. These results quantitatively confirm the widespread practice of performing learning updates every 4th environmental step.