 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignals of Success and Struggle: Early Prediction and Physiological Signatures of Human Performance across Task Complexity
Mar 19, 2026User performance is crucial in interactive systems, capturing how effectively users engage with task execution. Prospectively predicting performance enables the timely identification of users struggling with task demands. While ocular and cardiac signals are widely used to characterise performance-relevant visual behaviour and physiological activation, their potential for early prediction and for revealing the physiological mechanisms underlying performance differences remains underexplored. We conducted a within-subject experiment in a game environment with naturally unfolding complexity, using early ocular and cardiac signals to predict later performance and to examine physiological and self-reported group differences. Results show that the ocular-cardiac fusion model achieves a balanced accuracy of 0.86, and the ocular-only model shows comparable predictive power. High performers exhibited targeted gaze and adjusted visual sampling, and sustained more stable cardiac activation as demands intensified, with a more positive affective experience. These findings demonstrate the feasibility of cross-session prediction from early physiology, providing interpretable insights into performance variation and facilitating future proactive intervention.
Flow-Enabled Generalization to Human Demonstrations in Few-Shot Imitation Learning
Feb 11, 2026Imitation Learning (IL) enables robots to learn complex skills from demonstrations without explicit task modeling, but it typically requires large amounts of demonstrations, creating significant collection costs. Prior work has investigated using flow as an intermediate representation to enable the use of human videos as a substitute, thereby reducing the amount of required robot demonstrations. However, most prior work has focused on the flow, either on the object or on specific points of the robot/hand, which cannot describe the motion of interaction. Meanwhile, relying on flow to achieve generalization to scenarios observed only in human videos remains limited, as flow alone cannot capture precise motion details. Furthermore, conditioning on scene observation to produce precise actions may cause the flow-conditioned policy to overfit to training tasks and weaken the generalization indicated by the flow. To address these gaps, we propose SFCrP, which includes a Scene Flow prediction model for Cross-embodiment learning (SFCr) and a Flow and Cropped point cloud conditioned Policy (FCrP). SFCr learns from both robot and human videos and predicts any point trajectories. FCrP follows the general flow motion and adjusts the action based on observations for precision tasks. Our method outperforms SOTA baselines across various real-world task settings, while also exhibiting strong spatial and instance generalization to scenarios seen only in human videos.
Large Language Models and Video Games: A Preliminary Scoping Review
Mar 05, 2024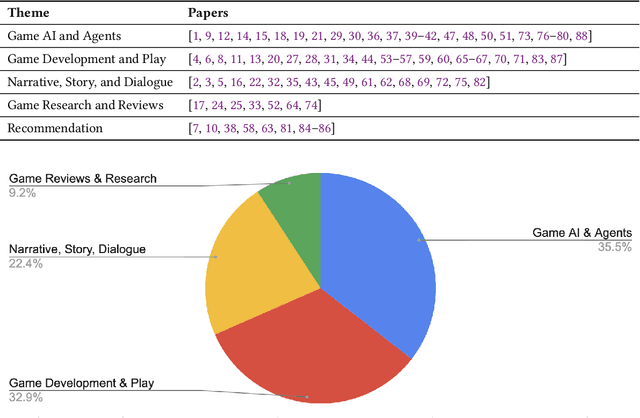
Large language models (LLMs) hold interesting potential for the design, development, and research of video games. Building on the decades of prior research on generative AI in games, many researchers have sped to investigate the power and potential of LLMs for games. Given the recent spike in LLM-related research in games, there is already a wealth of relevant research to survey. In order to capture a snapshot of the state of LLM research in games, and to help lay the foundation for future work, we carried out an initial scoping review of relevant papers published so far. In this paper, we review 76 papers published between 2022 to early 2024 on LLMs and video games, with key focus areas in game AI, game development, narrative, and game research and reviews. Our paper provides an early state of the field and lays the groundwork for future research and reviews on this topic.
Atari-5: Distilling the Arcade Learning Environment down to Five Games
Oct 05, 2022
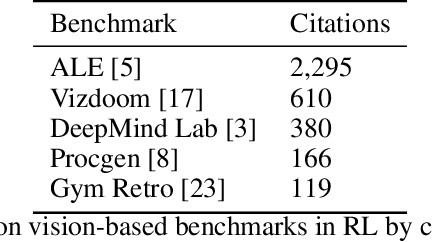

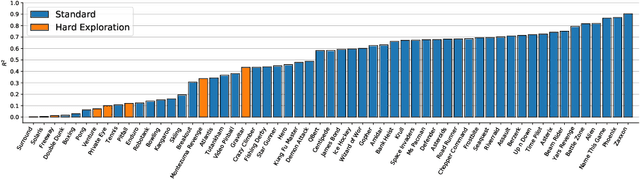
The Arcade Learning Environment (ALE) has become an essential benchmark for assessing the performance of reinforcement learning algorithms. However, the computational cost of generating results on the entire 57-game dataset limits ALE's use and makes the reproducibility of many results infeasible. We propose a novel solution to this problem in the form of a principled methodology for selecting small but representative subsets of environments within a benchmark suite. We applied our method to identify a subset of five ALE games, called Atari-5, which produces 57-game median score estimates within 10% of their true values. Extending the subset to 10-games recovers 80% of the variance for log-scores for all games within the 57-game set. We show this level of compression is possible due to a high degree of correlation between many of the games in ALE.
DNA: Proximal Policy Optimization with a Dual Network Architecture
Jun 20, 2022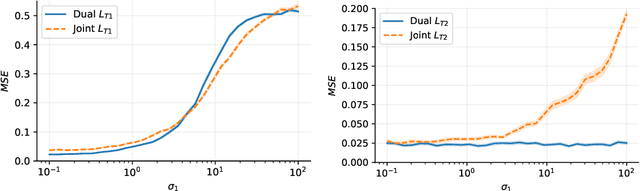
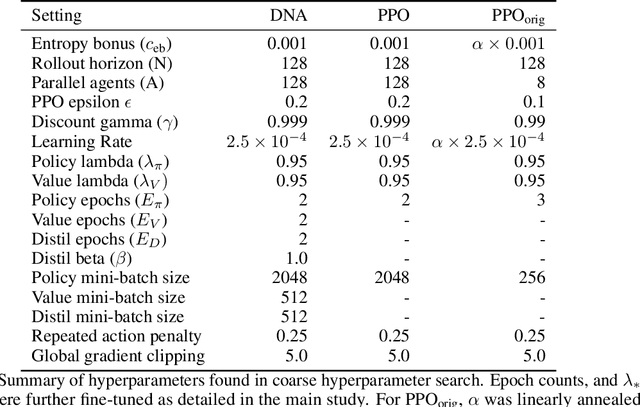
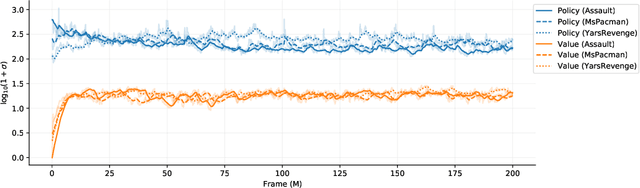

This paper explores the problem of simultaneously learning a value function and policy in deep actor-critic reinforcement learning models. We find that the common practice of learning these functions jointly is sub-optimal, due to an order-of-magnitude difference in noise levels between these two tasks. Instead, we show that learning these tasks independently, but with a constrained distillation phase, significantly improves performance. Furthermore, we find that the policy gradient noise levels can be decreased by using a lower \textit{variance} return estimate. Whereas, the value learning noise level decreases with a lower \textit{bias} estimate. Together these insights inform an extension to Proximal Policy Optimization we call \textit{Dual Network Architecture} (DNA), which significantly outperforms its predecessor. DNA also exceeds the performance of the popular Rainbow DQN algorithm on four of the five environments tested, even under more difficult stochastic control settings.