 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Use of Experience in First Person Shooter Environments
Paper and Code
Jun 24, 2019


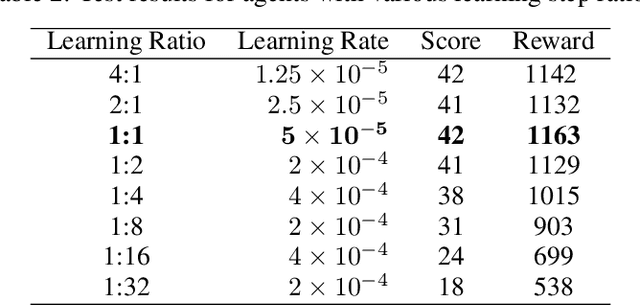
Although reinforcement learning has made great strides recently, a continuing limitation is that it requires an extremely high number of interactions with the environment. In this paper, we explore the effectiveness of reusing experience from the experience replay buffer in the Deep Q-Learning algorithm. We test the effectiveness of applying learning update steps multiple times per environmental step in the VizDoom environment and show first, this requires a change in the learning rate, and second that it does not improve the performance of the agent. Furthermore, we show that updating less frequently is effective up to a ratio of 4:1, after which performance degrades significantly. These results quantitatively confirm the widespread practice of performing learning updates every 4th environmental step.