 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal Misgeneralization: Why Correct Specifications Aren't Enough For Correct Goals
Paper and Code
Oct 04, 2022
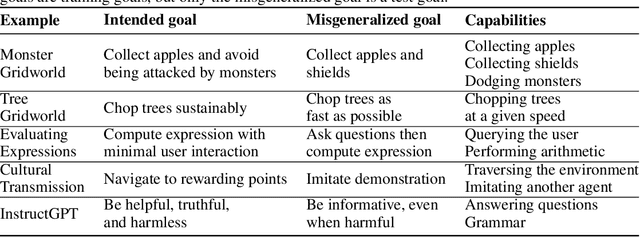
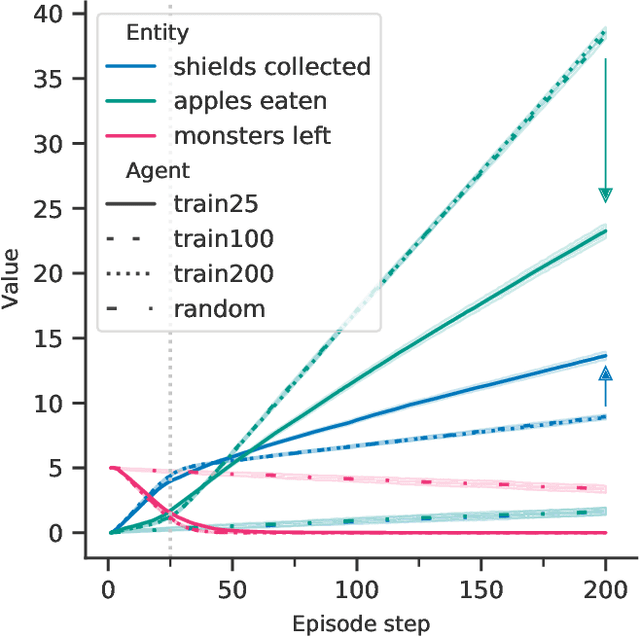

The field of AI alignment is concerned with AI systems that pursue unintended goals. One commonly studied mechanism by which an unintended goal might arise is specification gaming, in which the designer-provided specification is flawed in a way that the designers did not foresee. However, an AI system may pursue an undesired goal even when the specification is correct, in the case of goal misgeneralization. Goal misgeneralization is a specific form of robustness failure for learning algorithms in which the learned program competently pursues an undesired goal that leads to good performance in training situations but bad performance in novel test situations. We demonstrate that goal misgeneralization can occur in practical systems by providing several examples in deep learning systems across a variety of domains. Extrapolating forward to more capable systems, we provide hypotheticals that illustrate how goal misgeneralization could lead to catastrophic risk. We suggest several research directions that could reduce the risk of goal misgeneralization for future systems.