 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan foundation models actively gather information in interactive environments to test hypotheses?
Dec 09, 2024



While problem solving is a standard evaluation task for foundation models, a crucial component of problem solving -- actively and strategically gathering information to test hypotheses -- has not been closely investigated. To assess the information gathering abilities of foundation models in interactive environments, we introduce a framework in which a model must determine the factors influencing a hidden reward function by iteratively reasoning about its previously gathered information and proposing its next exploratory action to maximize information gain at each step. We implement this framework in both a text-based environment, which offers a tightly controlled setting and enables high-throughput parameter sweeps, and in an embodied 3D environment, which requires addressing complexities of multi-modal interaction more relevant to real-world applications. We further investigate whether approaches such as self-correction and increased inference time improve information gathering efficiency. In a relatively simple task that requires identifying a single rewarding feature, we find that LLM's information gathering capability is close to optimal. However, when the model must identify a conjunction of rewarding features, performance is suboptimal. The hit in performance is due partly to the model translating task description to a policy and partly to the model's effectiveness in using its in-context memory. Performance is comparable in both text and 3D embodied environments, although imperfect visual object recognition reduces its accuracy in drawing conclusions from gathered information in the 3D embodied case. For single-feature-based rewards, we find that smaller models curiously perform better; for conjunction-based rewards, incorporating self correction into the model improves performance.
Meta-Learning Deep Energy-Based Memory Models
Oct 07, 2019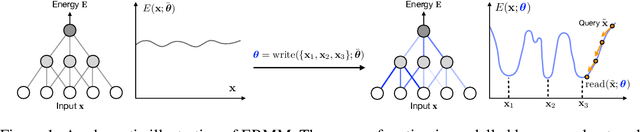
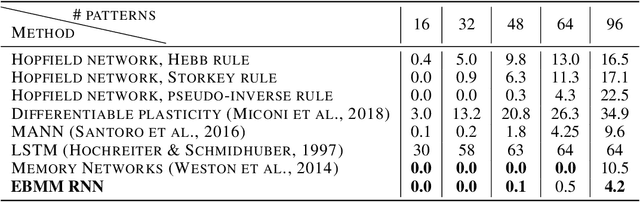
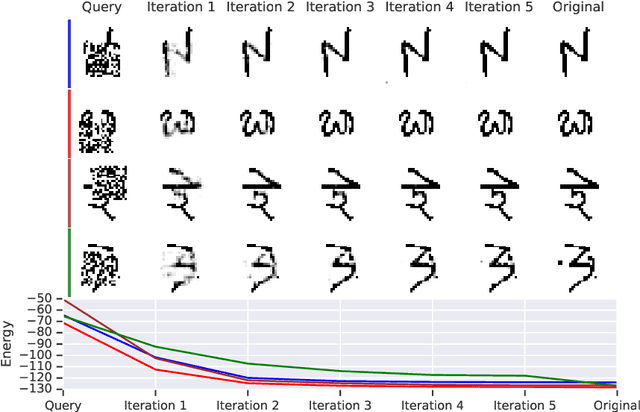
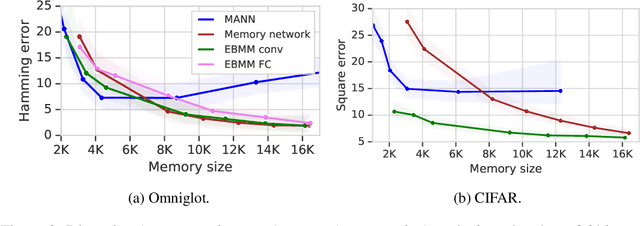
We study the problem of learning associative memory -- a system which is able to retrieve a remembered pattern based on its distorted or incomplete version. Attractor networks provide a sound model of associative memory: patterns are stored as attractors of the network dynamics and associative retrieval is performed by running the dynamics starting from a query pattern until it converges to an attractor. In such models the dynamics are often implemented as an optimization procedure that minimizes an energy function, such as in the classical Hopfield network. In general it is difficult to derive a writing rule for a given dynamics and energy that is both compressive and fast. Thus, most research in energy-based memory has been limited either to tractable energy models not expressive enough to handle complex high-dimensional objects such as natural images, or to models that do not offer fast writing. We present a novel meta-learning approach to energy-based memory models (EBMM) that allows one to use an arbitrary neural architecture as an energy model and quickly store patterns in its weights. We demonstrate experimentally that our EBMM approach can build compressed memories for synthetic and natural data, and is capable of associative retrieval that outperforms existing memory systems in terms of the reconstruction error and compression rate.
Meta-Learning Neural Bloom Filters
Jun 10, 2019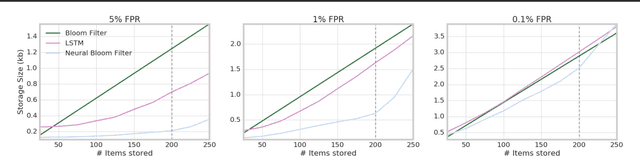
There has been a recent trend in training neural networks to replace data structures that have been crafted by hand, with an aim for faster execution, better accuracy, or greater compression. In this setting, a neural data structure is instantiated by training a network over many epochs of its inputs until convergence. In applications where inputs arrive at high throughput, or are ephemeral, training a network from scratch is not practical. This motivates the need for few-shot neural data structures. In this paper we explore the learning of approximate set membership over a set of data in one-shot via meta-learning. We propose a novel memory architecture, the Neural Bloom Filter, which is able to achieve significant compression gains over classical Bloom Filters and existing memory-augmented neural networks.
Entropic Policy Composition with Generalized Policy Improvement and Divergence Correction
Dec 05, 2018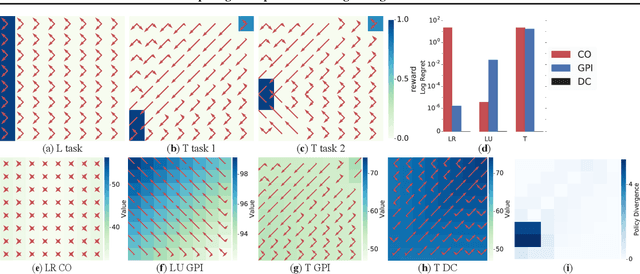



Deep reinforcement learning (RL) algorithms have made great strides in recent years. An important remaining challenge is the ability to quickly transfer existing skills to novel tasks, and to combine existing skills with newly acquired ones. In domains where tasks are solved by composing skills this capacity holds the promise of dramatically reducing the data requirements of deep RL algorithms, and hence increasing their applicability. Recent work has studied ways of composing behaviors represented in the form of action-value functions. We analyze these methods to highlight their strengths and weaknesses, and point out situations where each of them is susceptible to poor performance. To perform this analysis we extend generalized policy improvement to the max-entropy framework and introduce a method for the practical implementation of successor features in continuous action spaces. Then we propose a novel approach which, in principle, recovers the optimal policy during transfer. This method works by explicitly learning the (discounted, future) divergence between policies. We study this approach in the tabular case and propose a scalable variant that is applicable in multi-dimensional continuous action spaces. We compare our approach with existing ones on a range of non-trivial continuous control problems with compositional structure, and demonstrate qualitatively better performance despite not requiring simultaneous observation of all task rewards.
Fast Parametric Learning with Activation Memorization
Mar 27, 2018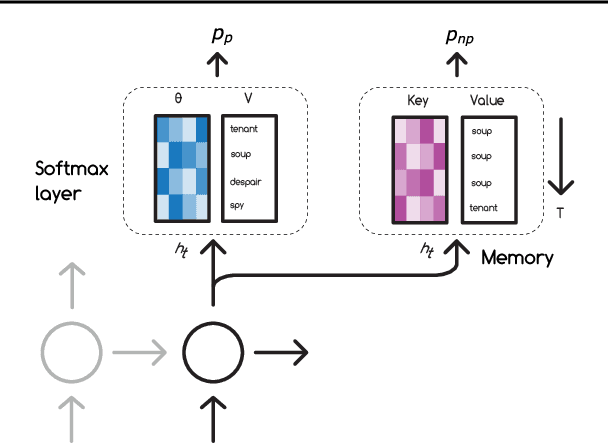
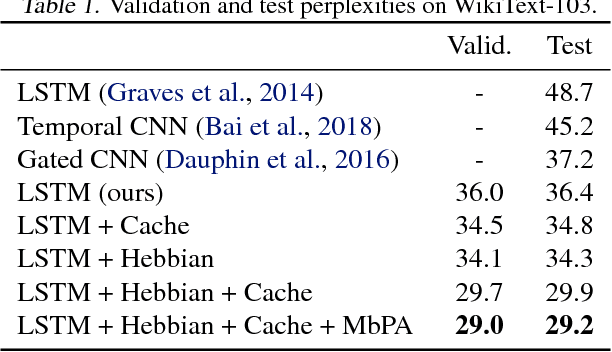
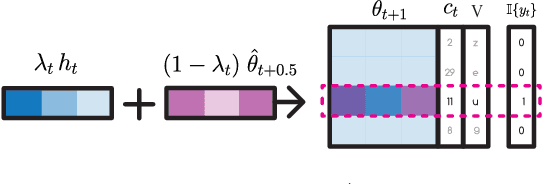
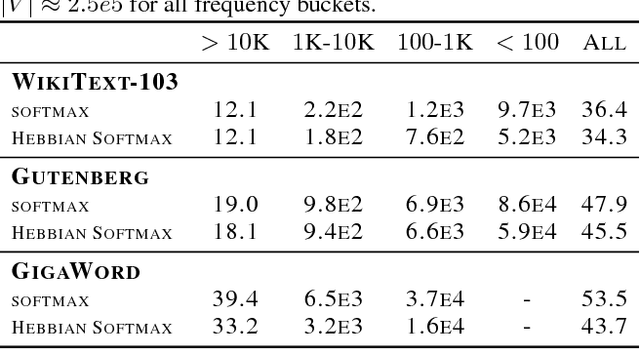
Neural networks trained with backpropagation often struggle to identify classes that have been observed a small number of times. In applications where most class labels are rare, such as language modelling, this can become a performance bottleneck. One potential remedy is to augment the network with a fast-learning non-parametric model which stores recent activations and class labels into an external memory. We explore a simplified architecture where we treat a subset of the model parameters as fast memory stores. This can help retain information over longer time intervals than a traditional memory, and does not require additional space or compute. In the case of image classification, we display faster binding of novel classes on an Omniglot image curriculum task. We also show improved performance for word-based language models on news reports (GigaWord), books (Project Gutenberg) and Wikipedia articles (WikiText-103) --- the latter achieving a state-of-the-art perplexity of 29.2.
Scaling Memory-Augmented Neural Networks with Sparse Reads and Writes
Oct 27, 2016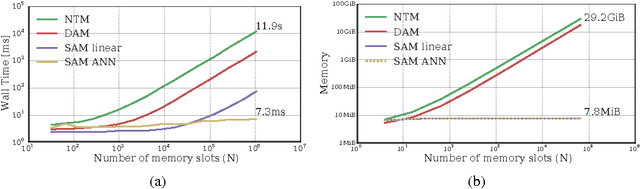
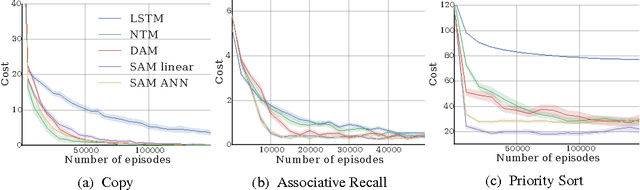
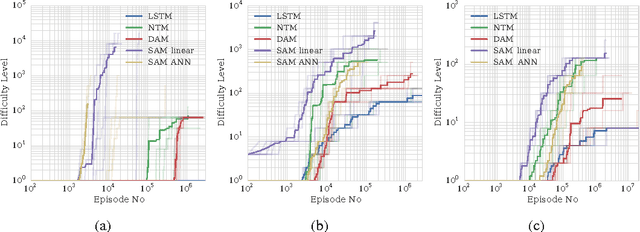
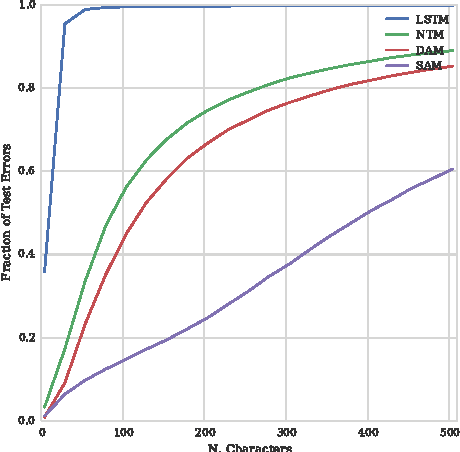
Neural networks augmented with external memory have the ability to learn algorithmic solutions to complex tasks. These models appear promising for applications such as language modeling and machine translation. However, they scale poorly in both space and time as the amount of memory grows --- limiting their applicability to real-world domains. Here, we present an end-to-end differentiable memory access scheme, which we call Sparse Access Memory (SAM), that retains the representational power of the original approaches whilst training efficiently with very large memories. We show that SAM achieves asymptotic lower bounds in space and time complexity, and find that an implementation runs $1,\!000\times$ faster and with $3,\!000\times$ less physical memory than non-sparse models. SAM learns with comparable data efficiency to existing models on a range of synthetic tasks and one-shot Omniglot character recognition, and can scale to tasks requiring $100,\!000$s of time steps and memories. As well, we show how our approach can be adapted for models that maintain temporal associations between memories, as with the recently introduced Differentiable Neural Computer.
Memory-based control with recurrent neural networks
Dec 14, 2015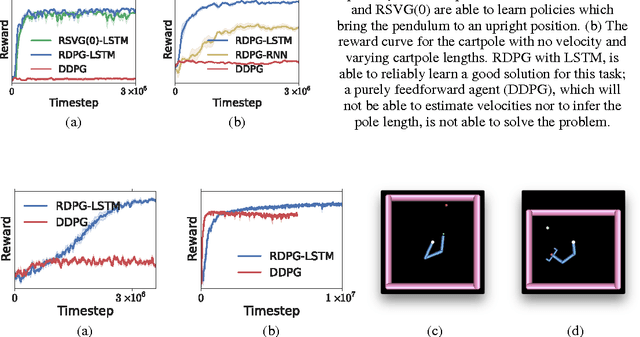
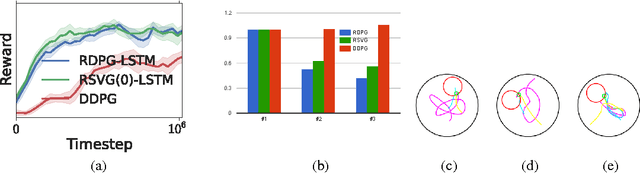
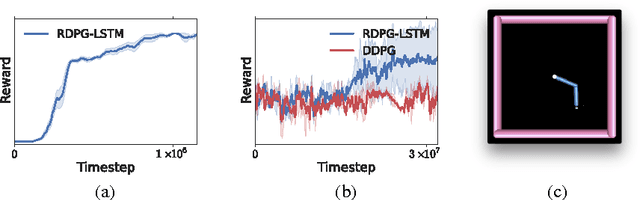
Partially observed control problems are a challenging aspect of reinforcement learning. We extend two related, model-free algorithms for continuous control -- deterministic policy gradient and stochastic value gradient -- to solve partially observed domains using recurrent neural networks trained with backpropagation through time. We demonstrate that this approach, coupled with long-short term memory is able to solve a variety of physical control problems exhibiting an assortment of memory requirements. These include the short-term integration of information from noisy sensors and the identification of system parameters, as well as long-term memory problems that require preserving information over many time steps. We also demonstrate success on a combined exploration and memory problem in the form of a simplified version of the well-known Morris water maze task. Finally, we show that our approach can deal with high-dimensional observations by learning directly from pixels. We find that recurrent deterministic and stochastic policies are able to learn similarly good solutions to these tasks, including the water maze where the agent must learn effective search strategies.