 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-based control with recurrent neural networks
Paper and Code
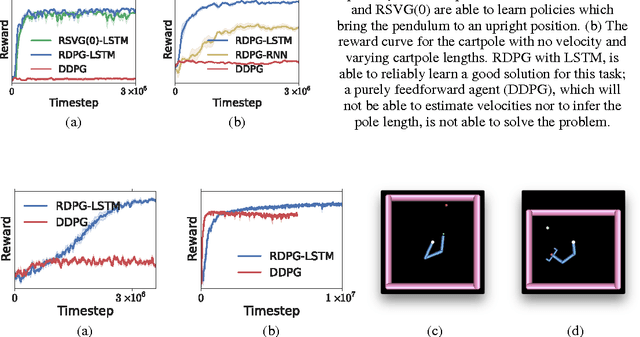
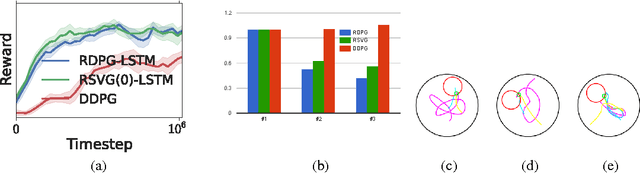
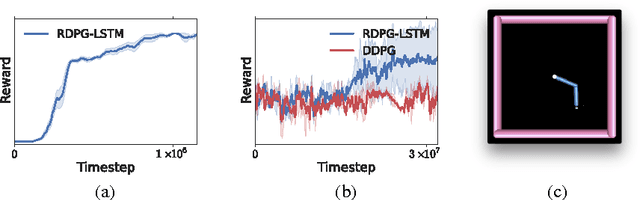
Partially observed control problems are a challenging aspect of reinforcement learning. We extend two related, model-free algorithms for continuous control -- deterministic policy gradient and stochastic value gradient -- to solve partially observed domains using recurrent neural networks trained with backpropagation through time. We demonstrate that this approach, coupled with long-short term memory is able to solve a variety of physical control problems exhibiting an assortment of memory requirements. These include the short-term integration of information from noisy sensors and the identification of system parameters, as well as long-term memory problems that require preserving information over many time steps. We also demonstrate success on a combined exploration and memory problem in the form of a simplified version of the well-known Morris water maze task. Finally, we show that our approach can deal with high-dimensional observations by learning directly from pixels. We find that recurrent deterministic and stochastic policies are able to learn similarly good solutions to these tasks, including the water maze where the agent must learn effective search strategies.