 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Exploit Temporal Structure for Biomedical Vision-Language Processing
Jan 11, 2023


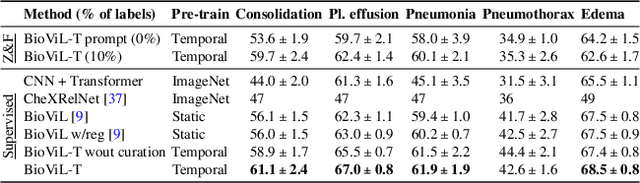
Self-supervised learning in vision-language processing exploits semantic alignment between imaging and text modalities. Prior work in biomedical VLP has mostly relied on the alignment of single image and report pairs even though clinical notes commonly refer to prior images. This does not only introduce poor alignment between the modalities but also a missed opportunity to exploit rich self-supervision through existing temporal content in the data. In this work, we explicitly account for prior images and reports when available during both training and fine-tuning. Our approach, named BioViL-T, uses a CNN-Transformer hybrid multi-image encoder trained jointly with a text model. It is designed to be versatile to arising challenges such as pose variations and missing input images across time. The resulting model excels on downstream tasks both in single- and multi-image setups, achieving state-of-the-art performance on (I) progression classification, (II) phrase grounding, and (III) report generation, whilst offering consistent improvements on disease classification and sentence-similarity tasks. We release a novel multi-modal temporal benchmark dataset, MS-CXR-T, to quantify the quality of vision-language representations in terms of temporal semantics. Our experimental results show the advantages of incorporating prior images and reports to make most use of the data.
Making the Most of Text Semantics to Improve Biomedical Vision--Language Processing
Apr 21, 2022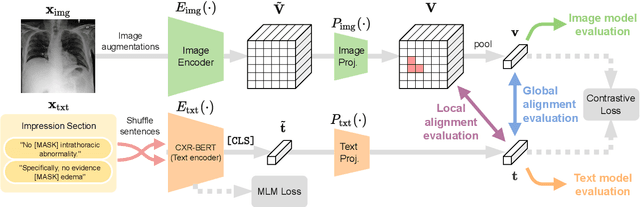

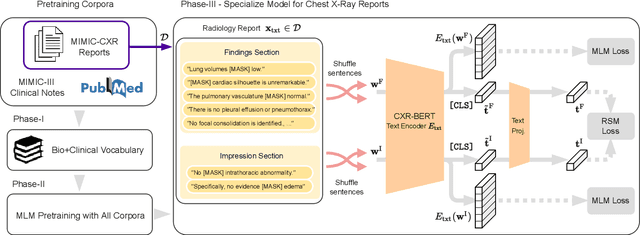

Multi-modal data abounds in biomedicine, such as radiology images and reports. Interpreting this data at scale is essential for improving clinical care and accelerating clinical research. Biomedical text with its complex semantics poses additional challenges in vision-language modelling compared to the general domain, and previous work has used insufficiently adapted models that lack domain-specific language understanding. In this paper, we show that principled textual semantic modelling can substantially improve contrastive learning in self-supervised vision--language processing. We release a language model that achieves state-of-the-art results in radiology natural language inference through its improved vocabulary and novel language pretraining objective leveraging semantics and discourse characteristics in radiology reports. Further, we propose a self-supervised joint vision--language approach with a focus on better text modelling. It establishes new state of the art results on a wide range of publicly available benchmarks, in part by leveraging our new domain-specific language model. We release a new dataset with locally-aligned phrase grounding annotations by radiologists to facilitate the study of complex semantic modelling in biomedical vision--language processing. A broad evaluation, including on this new dataset, shows that our contrastive learning approach, aided by textual-semantic modelling, outperforms prior methods in segmentation tasks, despite only using a global-alignment objective.
Constrained Clustering and Multiple Kernel Learning without Pairwise Constraint Relaxation
Mar 23, 2022
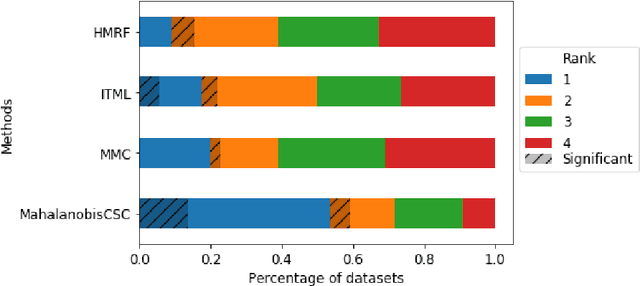
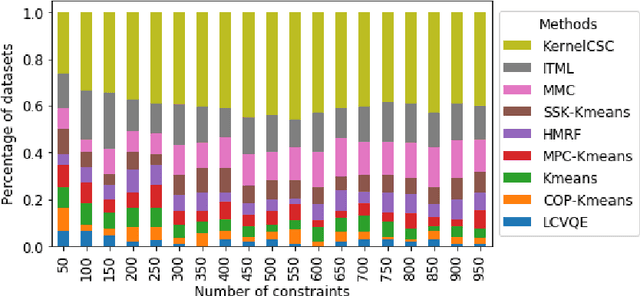

Clustering under pairwise constraints is an important knowledge discovery tool that enables the learning of appropriate kernels or distance metrics to improve clustering performance. These pairwise constraints, which come in the form of must-link and cannot-link pairs, arise naturally in many applications and are intuitive for users to provide. However, the common practice of relaxing discrete constraints to a continuous domain to ease optimization when learning kernels or metrics can harm generalization, as information which only encodes linkage is transformed to informing distances. We introduce a new constrained clustering algorithm that jointly clusters data and learns a kernel in accordance with the available pairwise constraints. To generalize well, our method is designed to maximize constraint satisfaction without relaxing pairwise constraints to a continuous domain where they inform distances. We show that the proposed method outperforms existing approaches on a large number of diverse publicly available datasets, and we discuss how our method can scale to handling large data.
Generative Modeling Helps Weak Supervision (and Vice Versa)
Mar 22, 2022
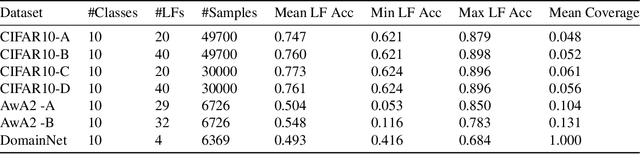
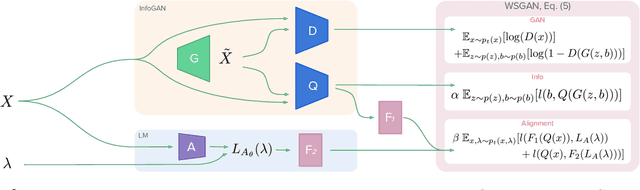
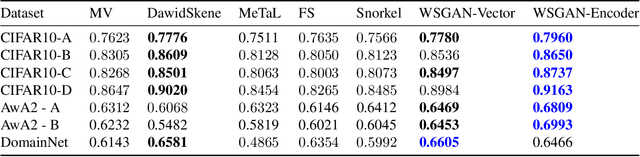
Many promising applications of supervised machine learning face hurdles in the acquisition of labeled data in sufficient quantity and quality, creating an expensive bottleneck. To overcome such limitations, techniques that do not depend on ground truth labels have been developed, including weak supervision and generative modeling. While these techniques would seem to be usable in concert, improving one another, how to build an interface between them is not well-understood. In this work, we propose a model fusing weak supervision and generative adversarial networks. It captures discrete variables in the data alongside the weak supervision derived label estimate. Their alignment allows for better modeling of sample-dependent accuracies of the weak supervision sources, improving the unobserved ground truth estimate. It is the first approach to enable data augmentation through weakly supervised synthetic images and pseudolabels. Additionally, its learned discrete variables can be inspected qualitatively. The model outperforms baseline weak supervision label models on a number of multiclass classification datasets, improves the quality of generated images, and further improves end-model performance through data augmentation with synthetic samples.
Weak Supervision for Affordable Modeling of Electrocardiogram Data
Jan 09, 2022


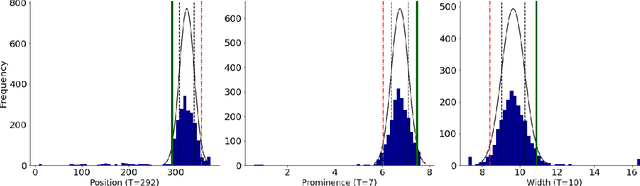
Analysing electrocardiograms (ECGs) is an inexpensive and non-invasive, yet powerful way to diagnose heart disease. ECG studies using Machine Learning to automatically detect abnormal heartbeats so far depend on large, manually annotated datasets. While collecting vast amounts of unlabeled data can be straightforward, the point-by-point annotation of abnormal heartbeats is tedious and expensive. We explore the use of multiple weak supervision sources to learn diagnostic models of abnormal heartbeats via human designed heuristics, without using ground truth labels on individual data points. Our work is among the first to define weak supervision sources directly on time series data. Results show that with as few as six intuitive time series heuristics, we are able to infer high quality probabilistic label estimates for over 100,000 heartbeats with little human effort, and use the estimated labels to train competitive classifiers evaluated on held out test data.
End-to-End Weak Supervision
Jul 05, 2021
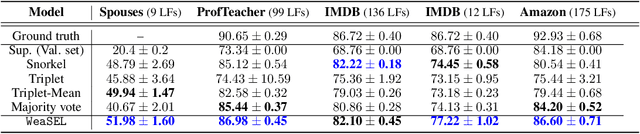
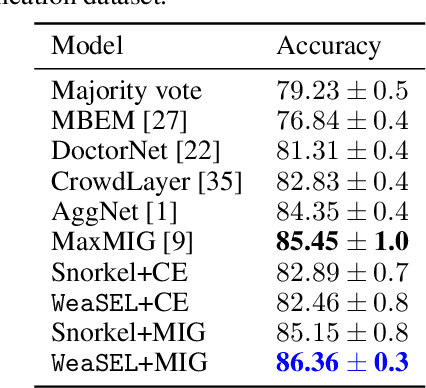

Aggregating multiple sources of weak supervision (WS) can ease the data-labeling bottleneck prevalent in many machine learning applications, by replacing the tedious manual collection of ground truth labels. Current state of the art approaches that do not use any labeled training data, however, require two separate modeling steps: Learning a probabilistic latent variable model based on the WS sources -- making assumptions that rarely hold in practice -- followed by downstream model training. Importantly, the first step of modeling does not consider the performance of the downstream model. To address these caveats we propose an end-to-end approach for directly learning the downstream model by maximizing its agreement with probabilistic labels generated by reparameterizing previous probabilistic posteriors with a neural network. Our results show improved performance over prior work in terms of end model performance on downstream test sets, as well as in terms of improved robustness to dependencies among weak supervision sources.
Dependency Structure Misspecification in Multi-Source Weak Supervision Models
Jun 18, 2021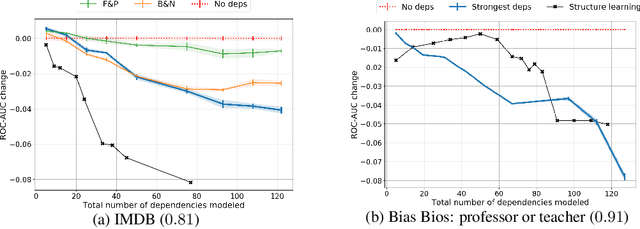

Data programming (DP) has proven to be an attractive alternative to costly hand-labeling of data. In DP, users encode domain knowledge into \emph{labeling functions} (LF), heuristics that label a subset of the data noisily and may have complex dependencies. A label model is then fit to the LFs to produce an estimate of the unknown class label. The effects of label model misspecification on test set performance of a downstream classifier are understudied. This presents a serious awareness gap to practitioners, in particular since the dependency structure among LFs is frequently ignored in field applications of DP. We analyse modeling errors due to structure over-specification. We derive novel theoretical bounds on the modeling error and empirically show that this error can be substantial, even when modeling a seemingly sensible structure.
Interactive Weak Supervision: Learning Useful Heuristics for Data Labeling
Dec 11, 2020

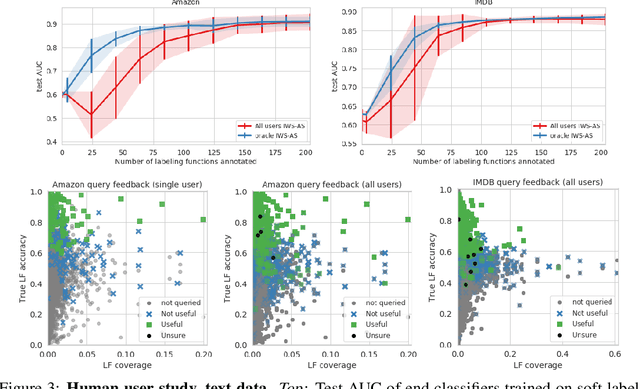
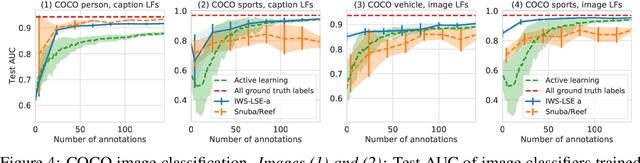
Obtaining large annotated datasets is critical for training successful machine learning models and it is often a bottleneck in practice. Weak supervision offers a promising alternative for producing labeled datasets without ground truth annotations by generating probabilistic labels using multiple noisy heuristics. This process can scale to large datasets and has demonstrated state of the art performance in diverse domains such as healthcare and e-commerce. One practical issue with learning from user-generated heuristics is that their creation requires creativity, foresight, and domain expertise from those who hand-craft them, a process which can be tedious and subjective. We develop the first framework for interactive weak supervision in which a method proposes heuristics and learns from user feedback given on each proposed heuristic. Our experiments demonstrate that only a small number of feedback iterations are needed to train models that achieve highly competitive test set performance without access to ground truth training labels. We conduct user studies, which show that users are able to effectively provide feedback on heuristics and that test set results track the performance of simulated oracles.
Pairwise Feedback for Data Programming
Dec 16, 2019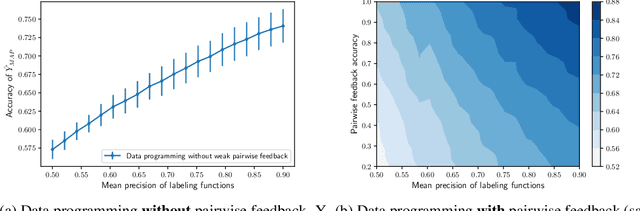
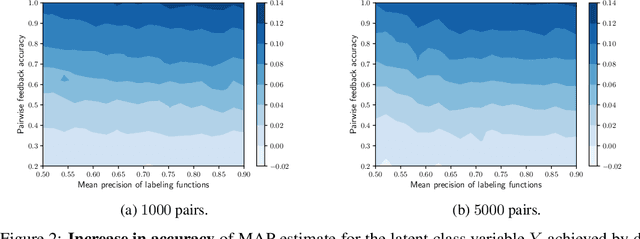
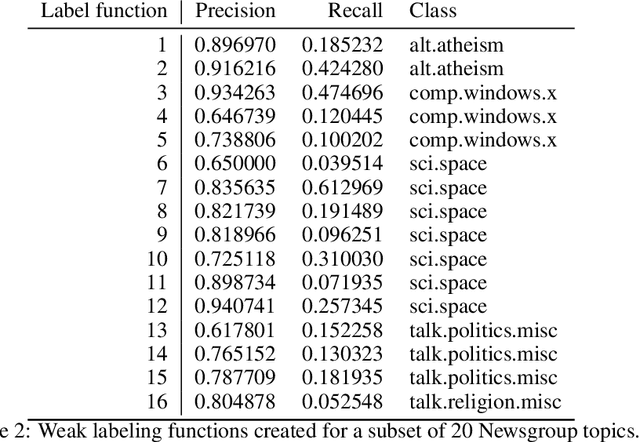
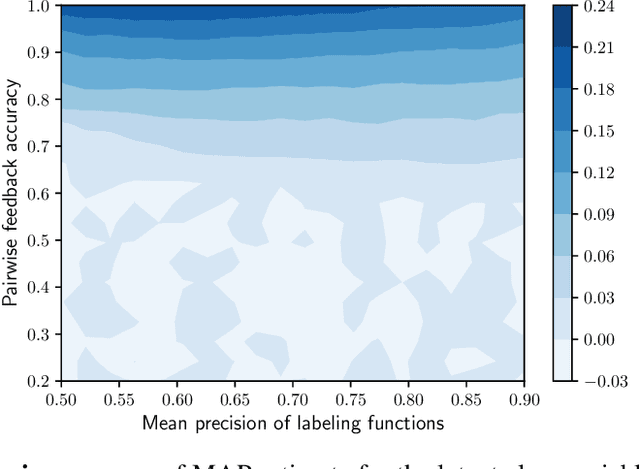
The scalability of the labeling process and the attainable quality of labels have become limiting factors for many applications of machine learning. The programmatic creation of labeled datasets via the synthesis of noisy heuristics provides a promising avenue to address this problem. We propose to improve modeling of latent class variables in the programmatic creation of labeled datasets by incorporating pairwise feedback into the process. We discuss the ease with which such pairwise feedback can be obtained or generated in many application domains. Our experiments show that even a small number of sources of pairwise feedback can substantially improve the quality of the posterior estimate of the latent class variable.
Always Lurking: Understanding and Mitigating Bias in Online Human Trafficking Detection
Dec 03, 2017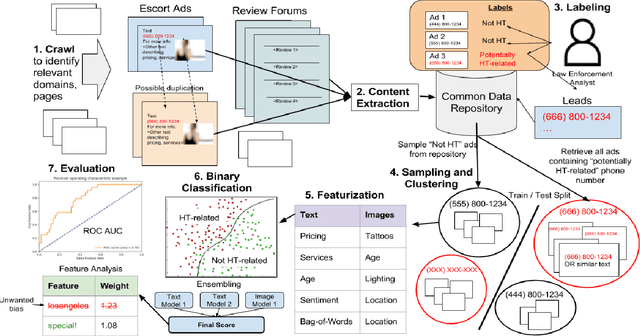
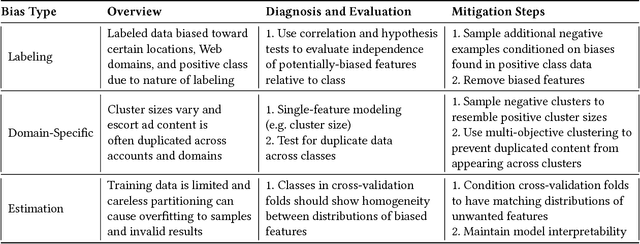
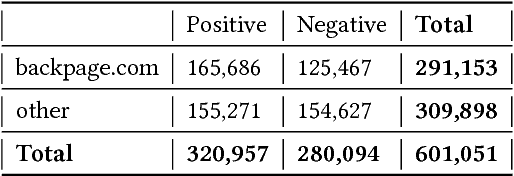
Web-based human trafficking activity has increased in recent years but it remains sparsely dispersed among escort advertisements and difficult to identify due to its often-latent nature. The use of intelligent systems to detect trafficking can thus have a direct impact on investigative resource allocation and decision-making, and, more broadly, help curb a widespread social problem. Trafficking detection involves assigning a normalized score to a set of escort advertisements crawled from the Web -- a higher score indicates a greater risk of trafficking-related (involuntary) activities. In this paper, we define and study the problem of trafficking detection and present a trafficking detection pipeline architecture developed over three years of research within the DARPA Memex program. Drawing on multi-institutional data, systems, and experiences collected during this time, we also conduct post hoc bias analyses and present a bias mitigation plan. Our findings show that, while automatic trafficking detection is an important application of AI for social good, it also provides cautionary lessons for deploying predictive machine learning algorithms without appropriate de-biasing. This ultimately led to integration of an interpretable solution into a search system that contains over 100 million advertisements and is used by over 200 law enforcement agencies to investigate leads.
* Submitted to 2018 AAAI 1st conference on AI, Ethics, and Society. Awaiting review