 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDependency Structure Misspecification in Multi-Source Weak Supervision Models
Paper and Code
Jun 18, 2021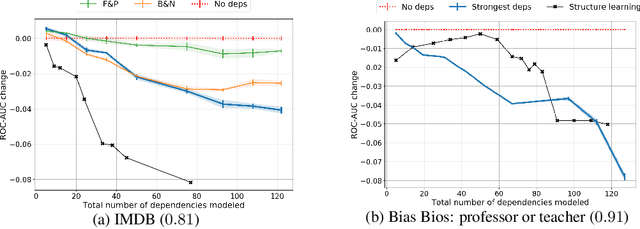

Data programming (DP) has proven to be an attractive alternative to costly hand-labeling of data. In DP, users encode domain knowledge into \emph{labeling functions} (LF), heuristics that label a subset of the data noisily and may have complex dependencies. A label model is then fit to the LFs to produce an estimate of the unknown class label. The effects of label model misspecification on test set performance of a downstream classifier are understudied. This presents a serious awareness gap to practitioners, in particular since the dependency structure among LFs is frequently ignored in field applications of DP. We analyse modeling errors due to structure over-specification. We derive novel theoretical bounds on the modeling error and empirically show that this error can be substantial, even when modeling a seemingly sensible structure.