 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIALSCOPE: A Unifying Causal Framework for Scaling Real-World Evidence Generation with Biomedical Language Models
Nov 06, 2023The rapid digitization of real-world data offers an unprecedented opportunity for optimizing healthcare delivery and accelerating biomedical discovery. In practice, however, such data is most abundantly available in unstructured forms, such as clinical notes in electronic medical records (EMRs), and it is generally plagued by confounders. In this paper, we present TRIALSCOPE, a unifying framework for distilling real-world evidence from population-level observational data. TRIALSCOPE leverages biomedical language models to structure clinical text at scale, employs advanced probabilistic modeling for denoising and imputation, and incorporates state-of-the-art causal inference techniques to combat common confounders. Using clinical trial specification as generic representation, TRIALSCOPE provides a turn-key solution to generate and reason with clinical hypotheses using observational data. In extensive experiments and analyses on a large-scale real-world dataset with over one million cancer patients from a large US healthcare network, we show that TRIALSCOPE can produce high-quality structuring of real-world data and generates comparable results to marquee cancer trials. In addition to facilitating in-silicon clinical trial design and optimization, TRIALSCOPE may be used to empower synthetic controls, pragmatic trials, post-market surveillance, as well as support fine-grained patient-like-me reasoning in precision diagnosis and treatment.
Looking for a Handsome Carpenter! Debiasing GPT-3 Job Advertisements
May 23, 2022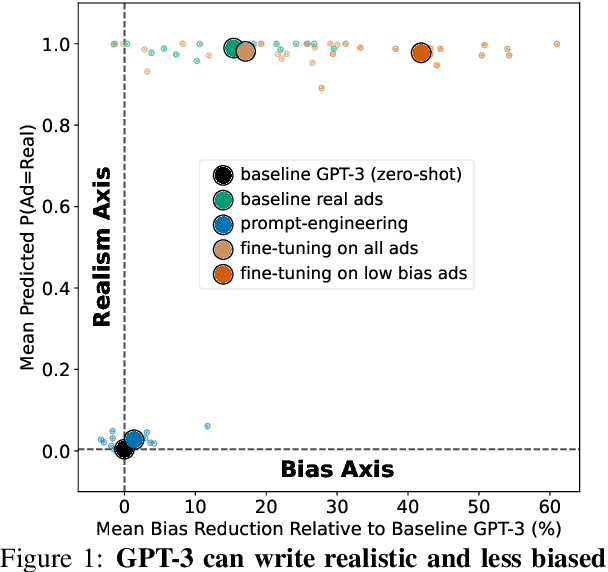
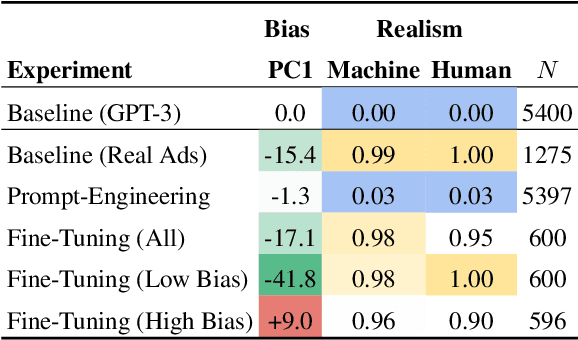
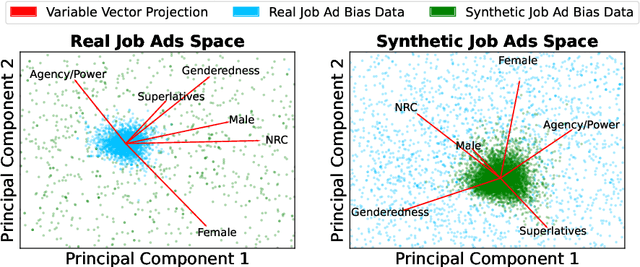
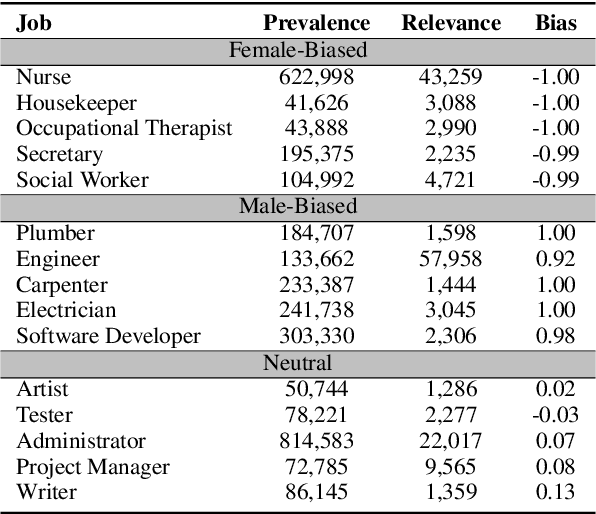
The growing capability and availability of generative language models has enabled a wide range of new downstream tasks. Academic research has identified, quantified and mitigated biases present in language models but is rarely tailored to downstream tasks where wider impact on individuals and society can be felt. In this work, we leverage one popular generative language model, GPT-3, with the goal of writing unbiased and realistic job advertisements. We first assess the bias and realism of zero-shot generated advertisements and compare them to real-world advertisements. We then evaluate prompt-engineering and fine-tuning as debiasing methods. We find that prompt-engineering with diversity-encouraging prompts gives no significant improvement to bias, nor realism. Conversely, fine-tuning, especially on unbiased real advertisements, can improve realism and reduce bias.
On Optimal Interpolation In Linear Regression
Oct 21, 2021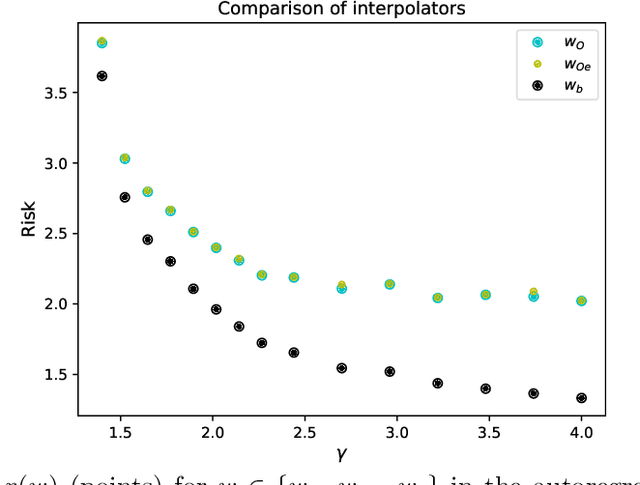
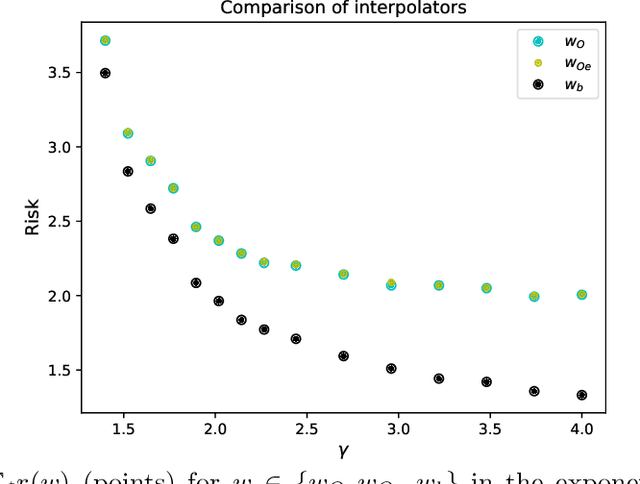
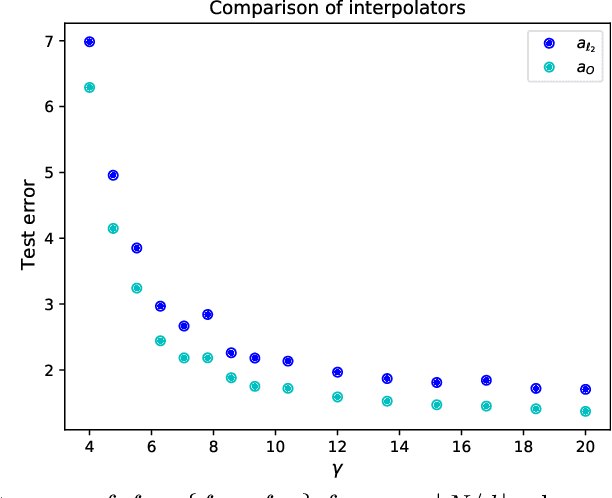
Understanding when and why interpolating methods generalize well has recently been a topic of interest in statistical learning theory. However, systematically connecting interpolating methods to achievable notions of optimality has only received partial attention. In this paper, we investigate the question of what is the optimal way to interpolate in linear regression using functions that are linear in the response variable (as the case for the Bayes optimal estimator in ridge regression) and depend on the data, the population covariance of the data, the signal-to-noise ratio and the covariance of the prior for the signal, but do not depend on the value of the signal itself nor the noise vector in the training data. We provide a closed-form expression for the interpolator that achieves this notion of optimality and show that it can be derived as the limit of preconditioned gradient descent with a specific initialization. We identify a regime where the minimum-norm interpolator provably generalizes arbitrarily worse than the optimal response-linear achievable interpolator that we introduce, and validate with numerical experiments that the notion of optimality we consider can be achieved by interpolating methods that only use the training data as input in the case of an isotropic prior. Finally, we extend the notion of optimal response-linear interpolation to random features regression under a linear data-generating model that has been previously studied in the literature.