 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIALSCOPE: A Unifying Causal Framework for Scaling Real-World Evidence Generation with Biomedical Language Models
Nov 06, 2023The rapid digitization of real-world data offers an unprecedented opportunity for optimizing healthcare delivery and accelerating biomedical discovery. In practice, however, such data is most abundantly available in unstructured forms, such as clinical notes in electronic medical records (EMRs), and it is generally plagued by confounders. In this paper, we present TRIALSCOPE, a unifying framework for distilling real-world evidence from population-level observational data. TRIALSCOPE leverages biomedical language models to structure clinical text at scale, employs advanced probabilistic modeling for denoising and imputation, and incorporates state-of-the-art causal inference techniques to combat common confounders. Using clinical trial specification as generic representation, TRIALSCOPE provides a turn-key solution to generate and reason with clinical hypotheses using observational data. In extensive experiments and analyses on a large-scale real-world dataset with over one million cancer patients from a large US healthcare network, we show that TRIALSCOPE can produce high-quality structuring of real-world data and generates comparable results to marquee cancer trials. In addition to facilitating in-silicon clinical trial design and optimization, TRIALSCOPE may be used to empower synthetic controls, pragmatic trials, post-market surveillance, as well as support fine-grained patient-like-me reasoning in precision diagnosis and treatment.
Multi-disciplinary fairness considerations in machine learning for clinical trials
May 18, 2022While interest in the application of machine learning to improve healthcare has grown tremendously in recent years, a number of barriers prevent deployment in medical practice. A notable concern is the potential to exacerbate entrenched biases and existing health disparities in society. The area of fairness in machine learning seeks to address these issues of equity; however, appropriate approaches are context-dependent, necessitating domain-specific consideration. We focus on clinical trials, i.e., research studies conducted on humans to evaluate medical treatments. Clinical trials are a relatively under-explored application in machine learning for healthcare, in part due to complex ethical, legal, and regulatory requirements and high costs. Our aim is to provide a multi-disciplinary assessment of how fairness for machine learning fits into the context of clinical trials research and practice. We start by reviewing the current ethical considerations and guidelines for clinical trials and examine their relationship with common definitions of fairness in machine learning. We examine potential sources of unfairness in clinical trials, providing concrete examples, and discuss the role machine learning might play in either mitigating potential biases or exacerbating them when applied without care. Particular focus is given to adaptive clinical trials, which may employ machine learning. Finally, we highlight concepts that require further investigation and development, and emphasize new approaches to fairness that may be relevant to the design of clinical trials.
DIVINE: Diverse Influential Training Points for Data Visualization and Model Refinement
Jul 13, 2021
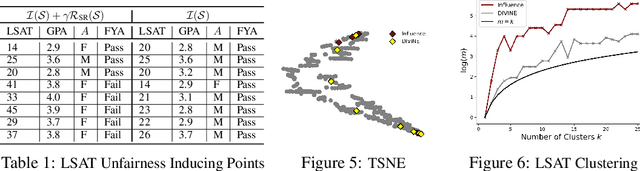

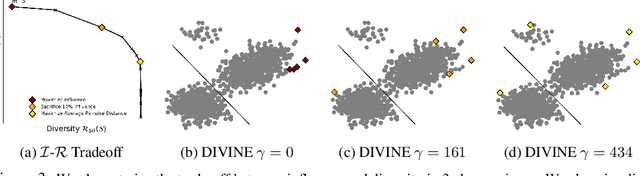
As the complexity of machine learning (ML) models increases, resulting in a lack of prediction explainability, several methods have been developed to explain a model's behavior in terms of the training data points that most influence the model. However, these methods tend to mark outliers as highly influential points, limiting the insights that practitioners can draw from points that are not representative of the training data. In this work, we take a step towards finding influential training points that also represent the training data well. We first review methods for assigning importance scores to training points. Given importance scores, we propose a method to select a set of DIVerse INfluEntial (DIVINE) training points as a useful explanation of model behavior. As practitioners might not only be interested in finding data points influential with respect to model accuracy, but also with respect to other important metrics, we show how to evaluate training data points on the basis of group fairness. Our method can identify unfairness-inducing training points, which can be removed to improve fairness outcomes. Our quantitative experiments and user studies show that visualizing DIVINE points helps practitioners understand and explain model behavior better than earlier approaches.