 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Learning with an Evolving Library
May 14, 2026We introduce EvoLib, a test-time learning framework that enables large language models to accumulate, reuse, and evolve knowledge across problem instances without parameter updates or external supervision. Instead of adapting model parameters, our approach maintains a shared library of knowledge abstractions, including modular skills and reflective insights, automatically extracted from the model's own inference trajectories. To support continual improvement, we introduce a principled weighting and consolidation mechanism that jointly optimizes for immediate utility and long-term value. This allows simple, instance-specific abstractions to evolve into more general and reusable ones over time. Across challenging benchmarks in mathematical reasoning, code generation, and multi-turn agentic environments, EvoLib improves substantially over the top test-time scaling and learning methods without ground-truth feedback.
Agentic-imodels: Evolving agentic interpretability tools via autoresearch
May 05, 2026Agentic data science (ADS) systems are rapidly improving their capability to autonomously analyze, fit, and interpret data, potentially moving towards a future where agents conduct the vast majority of data-science work. However, current ADS systems use statistical tools designed to be interpretable by humans, rather than interpretable by agents. To address this, we introduce Agentic-imodels, an agentic autoresearch loop that evolves data-science tools designed to be interpretable by agents. Specifically, it develops a library of scikit-learn-compatible regressors for tabular data that are optimized for both predictive performance and a novel LLM-based interpretability metric. The metric measures a suite of LLM-graded tests that probe whether a fitted model's string representation is "simulatable" by an LLM, i.e. whether the LLM can answer questions about the model's behavior by reading its string output alone. We find that the evolved models jointly improve predictive performance and agent-facing interpretability, generalizing to new datasets and new interpretability tests. Furthermore, these evolved models improve downstream end-to-end ADS, increasing performance for Copilot CLI, Claude Code, and Codex on the BLADE benchmark by up to 73%
CancerGUIDE: Cancer Guideline Understanding via Internal Disagreement Estimation
Sep 09, 2025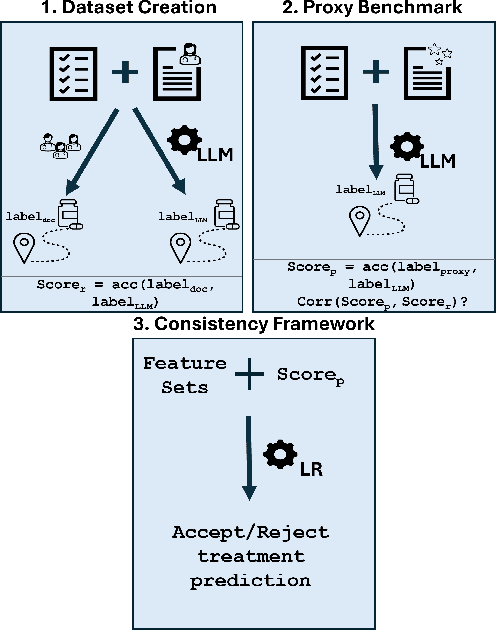
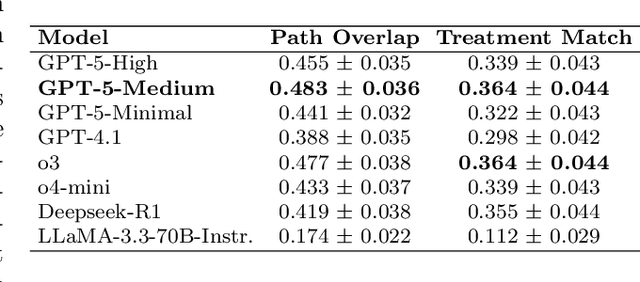
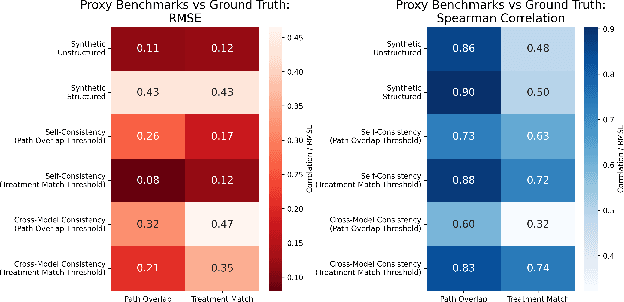

The National Comprehensive Cancer Network (NCCN) provides evidence-based guidelines for cancer treatment. Translating complex patient presentations into guideline-compliant treatment recommendations is time-intensive, requires specialized expertise, and is prone to error. Advances in large language model (LLM) capabilities promise to reduce the time required to generate treatment recommendations and improve accuracy. We present an LLM agent-based approach to automatically generate guideline-concordant treatment trajectories for patients with non-small cell lung cancer (NSCLC). Our contributions are threefold. First, we construct a novel longitudinal dataset of 121 cases of NSCLC patients that includes clinical encounters, diagnostic results, and medical histories, each expertly annotated with the corresponding NCCN guideline trajectories by board-certified oncologists. Second, we demonstrate that existing LLMs possess domain-specific knowledge that enables high-quality proxy benchmark generation for both model development and evaluation, achieving strong correlation (Spearman coefficient r=0.88, RMSE = 0.08) with expert-annotated benchmarks. Third, we develop a hybrid approach combining expensive human annotations with model consistency information to create both the agent framework that predicts the relevant guidelines for a patient, as well as a meta-classifier that verifies prediction accuracy with calibrated confidence scores for treatment recommendations (AUROC=0.800), a critical capability for communicating the accuracy of outputs, custom-tailoring tradeoffs in performance, and supporting regulatory compliance. This work establishes a framework for clinically viable LLM-based guideline adherence systems that balance accuracy, interpretability, and regulatory requirements while reducing annotation costs, providing a scalable pathway toward automated clinical decision support.
Universal Abstraction: Harnessing Frontier Models to Structure Real-World Data at Scale
Feb 02, 2025



The vast majority of real-world patient information resides in unstructured clinical text, and the process of medical abstraction seeks to extract and normalize structured information from this unstructured input. However, traditional medical abstraction methods can require significant manual efforts that can include crafting rules or annotating training labels, limiting scalability. In this paper, we propose UniMedAbstractor (UMA), a zero-shot medical abstraction framework leveraging Large Language Models (LLMs) through a modular and customizable prompt template. We refer to our approach as universal abstraction as it can quickly scale to new attributes through its universal prompt template without curating attribute-specific training labels or rules. We evaluate UMA for oncology applications, focusing on fifteen key attributes representing the cancer patient journey, from short-context attributes (e.g., performance status, treatment) to complex long-context attributes requiring longitudinal reasoning (e.g., tumor site, histology, TNM staging). Experiments on real-world data show UMA's strong performance and generalizability. Compared to supervised and heuristic baselines, UMA with GPT-4o achieves on average an absolute 2-point F1/accuracy improvement for both short-context and long-context attribute abstraction. For pathologic T staging, UMA even outperforms the supervised model by 20 points in accuracy.
Attribute Structuring Improves LLM-Based Evaluation of Clinical Text Summaries
Mar 01, 2024



Summarizing clinical text is crucial in health decision-support and clinical research. Large language models (LLMs) have shown the potential to generate accurate clinical text summaries, but still struggle with issues regarding grounding and evaluation, especially in safety-critical domains such as health. Holistically evaluating text summaries is challenging because they may contain unsubstantiated information. Here, we explore a general mitigation framework using Attribute Structuring (AS), which structures the summary evaluation process. It decomposes the evaluation process into a grounded procedure that uses an LLM for relatively simple structuring and scoring tasks, rather than the full task of holistic summary evaluation. Experiments show that AS consistently improves the correspondence between human annotations and automated metrics in clinical text summarization. Additionally, AS yields interpretations in the form of a short text span corresponding to each output, which enables efficient human auditing, paving the way towards trustworthy evaluation of clinical information in resource-constrained scenarios. We release our code, prompts, and an open-source benchmark at https://github.com/microsoft/attribute-structuring.
Enhancing Medical Text Evaluation with GPT-4
Nov 16, 2023In the evaluation of medical text generation, it is essential to scrutinize each piece of information and ensure the utmost accuracy of the evaluation. Existing evaluation metrics either focus on coarse-level evaluation that assigns one score for the whole generated output or rely on evaluation models trained on general domain, resulting in inaccuracies when adapted to the medical domain. To address these issues, we propose a set of factuality-centric evaluation aspects and design corresponding GPT-4-based metrics for medical text generation. We systematically compare these metrics with existing ones on clinical note generation and medical report summarization tasks, revealing low inter-metric correlation. A comprehensive human evaluation confirms that the proposed GPT-4-based metrics exhibit substantially higher agreement with human judgments than existing evaluation metrics. Our study contributes to the understanding of medical text generation evaluation and offers a more reliable alternative to existing metrics.
TRIALSCOPE: A Unifying Causal Framework for Scaling Real-World Evidence Generation with Biomedical Language Models
Nov 06, 2023The rapid digitization of real-world data offers an unprecedented opportunity for optimizing healthcare delivery and accelerating biomedical discovery. In practice, however, such data is most abundantly available in unstructured forms, such as clinical notes in electronic medical records (EMRs), and it is generally plagued by confounders. In this paper, we present TRIALSCOPE, a unifying framework for distilling real-world evidence from population-level observational data. TRIALSCOPE leverages biomedical language models to structure clinical text at scale, employs advanced probabilistic modeling for denoising and imputation, and incorporates state-of-the-art causal inference techniques to combat common confounders. Using clinical trial specification as generic representation, TRIALSCOPE provides a turn-key solution to generate and reason with clinical hypotheses using observational data. In extensive experiments and analyses on a large-scale real-world dataset with over one million cancer patients from a large US healthcare network, we show that TRIALSCOPE can produce high-quality structuring of real-world data and generates comparable results to marquee cancer trials. In addition to facilitating in-silicon clinical trial design and optimization, TRIALSCOPE may be used to empower synthetic controls, pragmatic trials, post-market surveillance, as well as support fine-grained patient-like-me reasoning in precision diagnosis and treatment.
Self-Verification Improves Few-Shot Clinical Information Extraction
May 30, 2023Extracting patient information from unstructured text is a critical task in health decision-support and clinical research. Large language models (LLMs) have shown the potential to accelerate clinical curation via few-shot in-context learning, in contrast to supervised learning which requires much more costly human annotations. However, despite drastic advances in modern LLMs such as GPT-4, they still struggle with issues regarding accuracy and interpretability, especially in mission-critical domains such as health. Here, we explore a general mitigation framework using self-verification, which leverages the LLM to provide provenance for its own extraction and check its own outputs. This is made possible by the asymmetry between verification and generation, where the latter is often much easier than the former. Experimental results show that our method consistently improves accuracy for various LLMs in standard clinical information extraction tasks. Additionally, self-verification yields interpretations in the form of a short text span corresponding to each output, which makes it very efficient for human experts to audit the results, paving the way towards trustworthy extraction of clinical information in resource-constrained scenarios. To facilitate future research in this direction, we release our code and prompts.