 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhylaFlow: Hybrid Flow Matching in Billera-Holmes-Vogtmann Tree Space for Phylogenetic Inference
May 21, 2026Phylogenetic trees are hybrid objects: branch lengths vary continuously, while topologies change discretely through edge contractions and expansions. Billera-Holmes-Vogtmann (BHV) tree space provides a canonical geometry for this structure, representing each resolved topology as a Euclidean orthant and topological changes as motion across shared lower-dimensional boundaries. We introduce PhylaFlow, a hybrid flow-matching model that learns posterior-basin transport in BHV tree space. PhylaFlow is trained on BHV geodesic paths from random starting trees to short-run posterior samples, coupling continuous branch-length motion within orthants with learned boundary events and discrete topology transitions. We evaluate the learned geometry operationally: if the flow reaches posterior-relevant regions, finite-budget Bayesian refinement initialized from, or guided by, its terminal trees should recover posterior-supported topologies more efficiently. Across DS1-DS8 phylogenetic posterior benchmarks, PhylaFlow substantially reduces initial Tree-KL relative to classical initializers. After finite-budget MrBayes refinement, direct PhylaFlow improves early and intermediate topology-recovery trajectories on most datasets, while split-guided PhylaFlow-MCMC obtains the strongest hard-case results. The best PhylaFlow variant outperforms short-warmup on seven of eight datasets and PhyloGFN on five of eight under the same refinement budget. In a joint sequence-conditioned experiment, sequence embeddings steer posterior split recovery, although exact posterior topology recovery remains preliminary. These results show that hybrid flow matching can learn actionable transport in BHV tree space and provide a geometry-aware proposal mechanism for Bayesian phylogenetic inference.
CancerGUIDE: Cancer Guideline Understanding via Internal Disagreement Estimation
Sep 09, 2025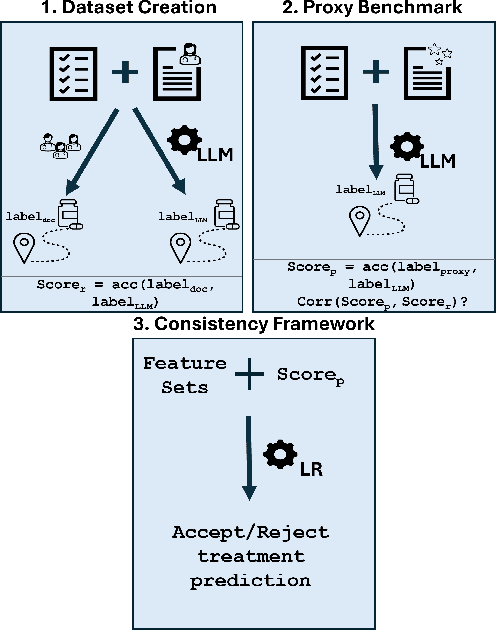
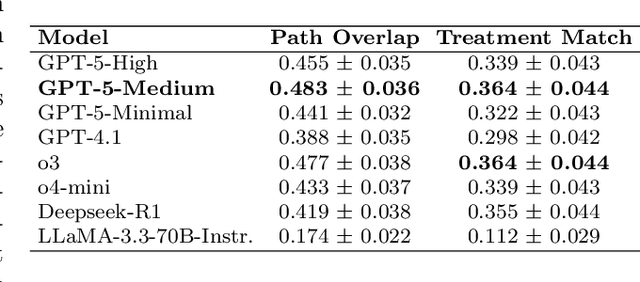
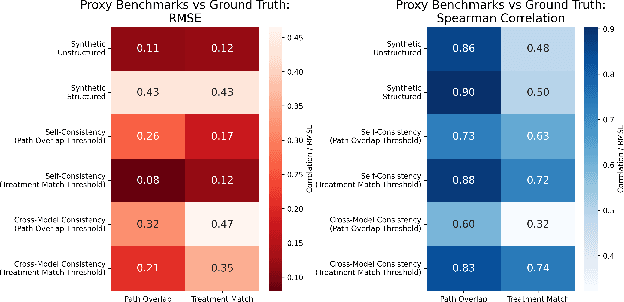

The National Comprehensive Cancer Network (NCCN) provides evidence-based guidelines for cancer treatment. Translating complex patient presentations into guideline-compliant treatment recommendations is time-intensive, requires specialized expertise, and is prone to error. Advances in large language model (LLM) capabilities promise to reduce the time required to generate treatment recommendations and improve accuracy. We present an LLM agent-based approach to automatically generate guideline-concordant treatment trajectories for patients with non-small cell lung cancer (NSCLC). Our contributions are threefold. First, we construct a novel longitudinal dataset of 121 cases of NSCLC patients that includes clinical encounters, diagnostic results, and medical histories, each expertly annotated with the corresponding NCCN guideline trajectories by board-certified oncologists. Second, we demonstrate that existing LLMs possess domain-specific knowledge that enables high-quality proxy benchmark generation for both model development and evaluation, achieving strong correlation (Spearman coefficient r=0.88, RMSE = 0.08) with expert-annotated benchmarks. Third, we develop a hybrid approach combining expensive human annotations with model consistency information to create both the agent framework that predicts the relevant guidelines for a patient, as well as a meta-classifier that verifies prediction accuracy with calibrated confidence scores for treatment recommendations (AUROC=0.800), a critical capability for communicating the accuracy of outputs, custom-tailoring tradeoffs in performance, and supporting regulatory compliance. This work establishes a framework for clinically viable LLM-based guideline adherence systems that balance accuracy, interpretability, and regulatory requirements while reducing annotation costs, providing a scalable pathway toward automated clinical decision support.
MedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
May 26, 2025



While large language models (LLMs) achieve near-perfect scores on medical licensing exams, these evaluations inadequately reflect the complexity and diversity of real-world clinical practice. We introduce MedHELM, an extensible evaluation framework for assessing LLM performance for medical tasks with three key contributions. First, a clinician-validated taxonomy spanning 5 categories, 22 subcategories, and 121 tasks developed with 29 clinicians. Second, a comprehensive benchmark suite comprising 35 benchmarks (17 existing, 18 newly formulated) providing complete coverage of all categories and subcategories in the taxonomy. Third, a systematic comparison of LLMs with improved evaluation methods (using an LLM-jury) and a cost-performance analysis. Evaluation of 9 frontier LLMs, using the 35 benchmarks, revealed significant performance variation. Advanced reasoning models (DeepSeek R1: 66% win-rate; o3-mini: 64% win-rate) demonstrated superior performance, though Claude 3.5 Sonnet achieved comparable results at 40% lower estimated computational cost. On a normalized accuracy scale (0-1), most models performed strongly in Clinical Note Generation (0.73-0.85) and Patient Communication & Education (0.78-0.83), moderately in Medical Research Assistance (0.65-0.75), and generally lower in Clinical Decision Support (0.56-0.72) and Administration & Workflow (0.53-0.63). Our LLM-jury evaluation method achieved good agreement with clinician ratings (ICC = 0.47), surpassing both average clinician-clinician agreement (ICC = 0.43) and automated baselines including ROUGE-L (0.36) and BERTScore-F1 (0.44). Claude 3.5 Sonnet achieved comparable performance to top models at lower estimated cost. These findings highlight the importance of real-world, task-specific evaluation for medical use of LLMs and provides an open source framework to enable this.
Universal Abstraction: Harnessing Frontier Models to Structure Real-World Data at Scale
Feb 02, 2025



The vast majority of real-world patient information resides in unstructured clinical text, and the process of medical abstraction seeks to extract and normalize structured information from this unstructured input. However, traditional medical abstraction methods can require significant manual efforts that can include crafting rules or annotating training labels, limiting scalability. In this paper, we propose UniMedAbstractor (UMA), a zero-shot medical abstraction framework leveraging Large Language Models (LLMs) through a modular and customizable prompt template. We refer to our approach as universal abstraction as it can quickly scale to new attributes through its universal prompt template without curating attribute-specific training labels or rules. We evaluate UMA for oncology applications, focusing on fifteen key attributes representing the cancer patient journey, from short-context attributes (e.g., performance status, treatment) to complex long-context attributes requiring longitudinal reasoning (e.g., tumor site, histology, TNM staging). Experiments on real-world data show UMA's strong performance and generalizability. Compared to supervised and heuristic baselines, UMA with GPT-4o achieves on average an absolute 2-point F1/accuracy improvement for both short-context and long-context attribute abstraction. For pathologic T staging, UMA even outperforms the supervised model by 20 points in accuracy.
MedImageInsight: An Open-Source Embedding Model for General Domain Medical Imaging
Oct 09, 2024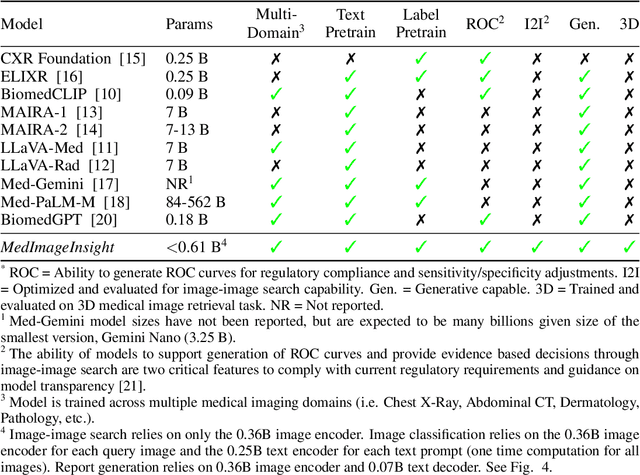
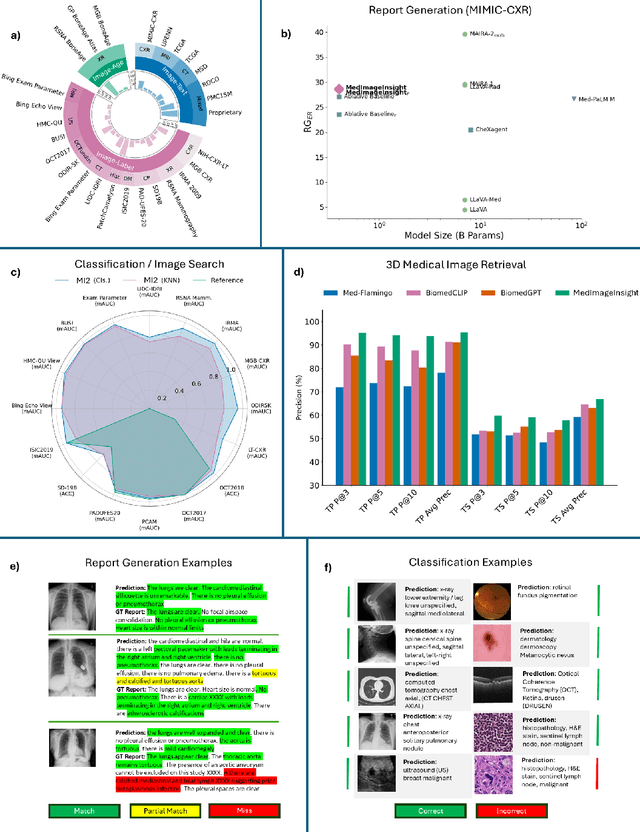
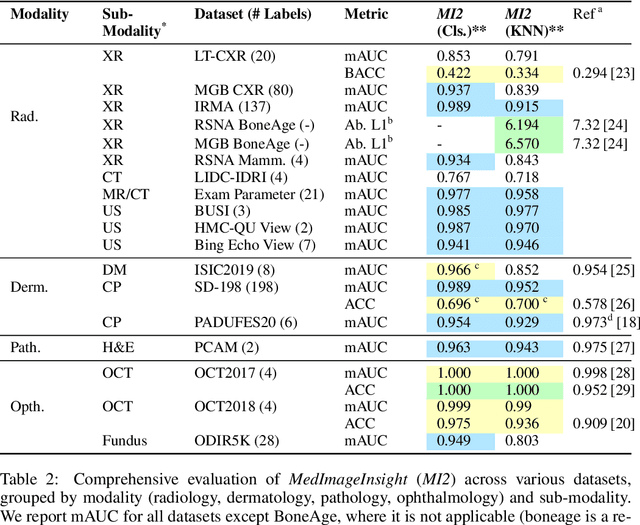
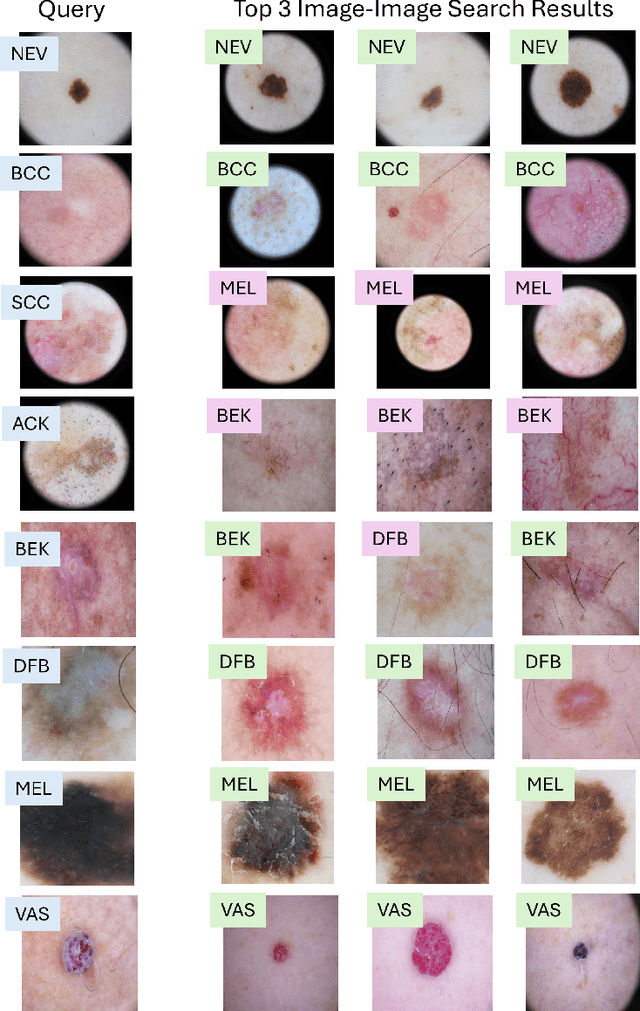
In this work, we present MedImageInsight, an open-source medical imaging embedding model. MedImageInsight is trained on medical images with associated text and labels across a diverse collection of domains, including X-Ray, CT, MRI, dermoscopy, OCT, fundus photography, ultrasound, histopathology, and mammography. Rigorous evaluations demonstrate MedImageInsight's ability to achieve state-of-the-art (SOTA) or human expert level performance across classification, image-image search, and fine-tuning tasks. Specifically, on public datasets, MedImageInsight achieves SOTA in CT 3D medical image retrieval, as well as SOTA in disease classification and search for chest X-ray, dermatology, and OCT imaging. Furthermore, MedImageInsight achieves human expert performance in bone age estimation (on both public and partner data), as well as AUC above 0.9 in most other domains. When paired with a text decoder, MedImageInsight achieves near SOTA level single image report findings generation with less than 10\% the parameters of other models. Compared to fine-tuning GPT-4o with only MIMIC-CXR data for the same task, MedImageInsight outperforms in clinical metrics, but underperforms on lexical metrics where GPT-4o sets a new SOTA. Importantly for regulatory purposes, MedImageInsight can generate ROC curves, adjust sensitivity and specificity based on clinical need, and provide evidence-based decision support through image-image search (which can also enable retrieval augmented generation). In an independent clinical evaluation of image-image search in chest X-ray, MedImageInsight outperformed every other publicly available foundation model evaluated by large margins (over 6 points AUC), and significantly outperformed other models in terms of AI fairness (across age and gender). We hope releasing MedImageInsight will help enhance collective progress in medical imaging AI research and development.
Push and Pull: A Framework for Measuring Attentional Agency
May 23, 2024

We propose a framework for measuring attentional agency - the ability to allocate one's attention according to personal desires, goals, and intentions - on digital platforms. Platforms extend people's limited powers of attention by extrapolating their preferences to large collections of previously unconsidered informational objects. However, platforms typically also allow people to influence one another's attention. We introduce a formal framework for measuring how much a given platform empowers people to both pull information into their own attentional field and push information into the attentional fields of others. We also use these definitions to shed light on the implications of generative foundation models, which enable users to bypass the implicit "attentional bargain" that underlies embedded advertising and other methods for capturing economic value from informational goods. We conclude with a set of policy strategies that can be used to understand and reshape the distribution of attentional agency online.
Verifiable evaluations of machine learning models using zkSNARKs
Feb 05, 2024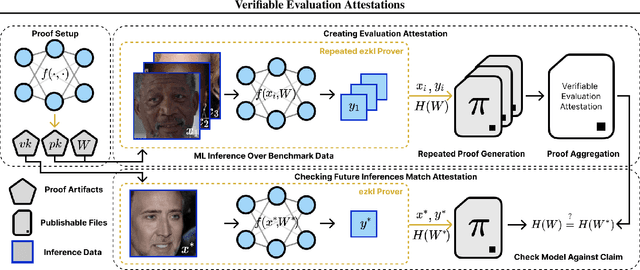

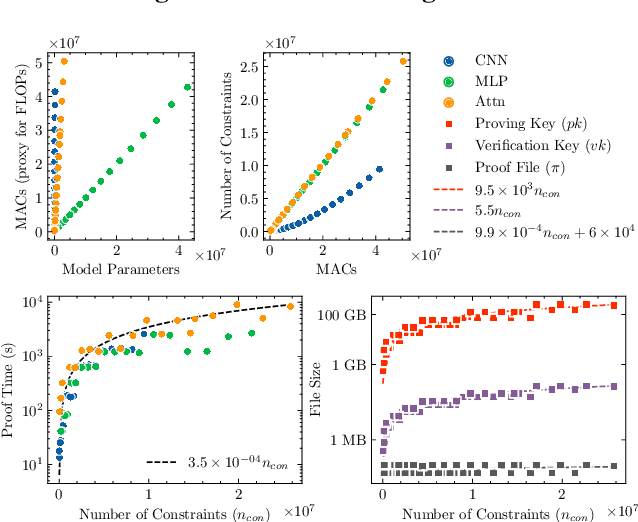
In a world of increasing closed-source commercial machine learning models, model evaluations from developers must be taken at face value. These benchmark results, whether over task accuracy, bias evaluations, or safety checks, are traditionally impossible to verify by a model end-user without the costly or impossible process of re-performing the benchmark on black-box model outputs. This work presents a method of verifiable model evaluation using model inference through zkSNARKs. The resulting zero-knowledge computational proofs of model outputs over datasets can be packaged into verifiable evaluation attestations showing that models with fixed private weights achieve stated performance or fairness metrics over public inputs. These verifiable attestations can be performed on any standard neural network model with varying compute requirements. For the first time, we demonstrate this across a sample of real-world models and highlight key challenges and design solutions. This presents a new transparency paradigm in the verifiable evaluation of private models.
Contextual Confidence and Generative AI
Nov 02, 2023

Generative AI models perturb the foundations of effective human communication. They present new challenges to contextual confidence, disrupting participants' ability to identify the authentic context of communication and their ability to protect communication from reuse and recombination outside its intended context. In this paper, we describe strategies--tools, technologies and policies--that aim to stabilize communication in the face of these challenges. The strategies we discuss fall into two broad categories. Containment strategies aim to reassert context in environments where it is currently threatened--a reaction to the context-free expectations and norms established by the internet. Mobilization strategies, by contrast, view the rise of generative AI as an opportunity to proactively set new and higher expectations around privacy and authenticity in mediated communication.
Unsupervised Learning of Molecular Embeddings for Enhanced Clustering and Emergent Properties for Chemical Compounds
Oct 25, 2023The detailed analysis of molecular structures and properties holds great potential for drug development discovery through machine learning. Developing an emergent property in the model to understand molecules would broaden the horizons for development with a new computational tool. We introduce various methods to detect and cluster chemical compounds based on their SMILES data. Our first method, analyzing the graphical structures of chemical compounds using embedding data, employs vector search to meet our threshold value. The results yielded pronounced, concentrated clusters, and the method produced favorable results in querying and understanding the compounds. We also used natural language description embeddings stored in a vector database with GPT3.5, which outperforms the base model. Thus, we introduce a similarity search and clustering algorithm to aid in searching for and interacting with molecules, enhancing efficiency in chemical exploration and enabling future development of emergent properties in molecular property prediction models.
Face Recognition in the age of CLIP & Billion image datasets
Jan 18, 2023


CLIP (Contrastive Language-Image Pre-training) models developed by OpenAI have achieved outstanding results on various image recognition and retrieval tasks, displaying strong zero-shot performance. This means that they are able to perform effectively on tasks for which they have not been explicitly trained. Inspired by the success of OpenAI CLIP, a new publicly available dataset called LAION-5B was collected which resulted in the development of open ViT-H/14, ViT-G/14 models that outperform the OpenAI L/14 model. The LAION-5B dataset also released an approximate nearest neighbor index, with a web interface for search & subset creation. In this paper, we evaluate the performance of various CLIP models as zero-shot face recognizers. Our findings show that CLIP models perform well on face recognition tasks, but increasing the size of the CLIP model does not necessarily lead to improved accuracy. Additionally, we investigate the robustness of CLIP models against data poisoning attacks by testing their performance on poisoned data. Through this analysis, we aim to understand the potential consequences and misuse of search engines built using CLIP models, which could potentially function as unintentional face recognition engines.