 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers meet Neural Algorithmic Reasoners
Jun 13, 2024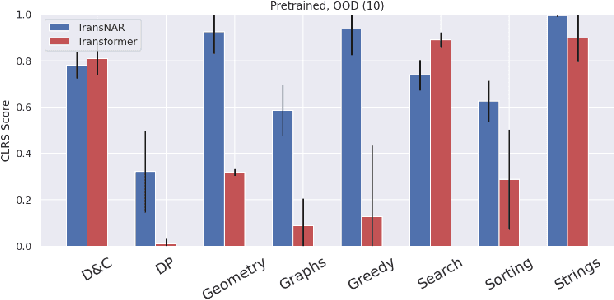
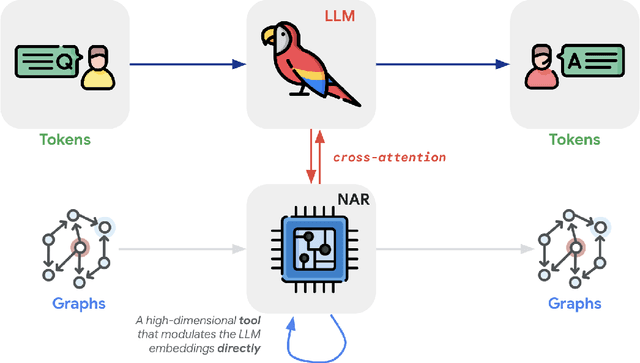
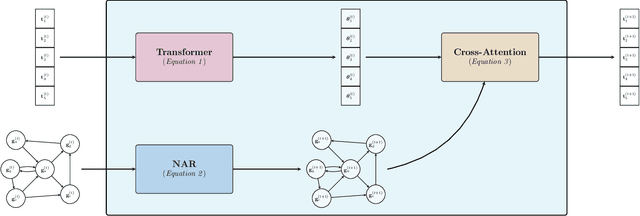
Transformers have revolutionized machine learning with their simple yet effective architecture. Pre-training Transformers on massive text datasets from the Internet has led to unmatched generalization for natural language understanding (NLU) tasks. However, such language models remain fragile when tasked with algorithmic forms of reasoning, where computations must be precise and robust. To address this limitation, we propose a novel approach that combines the Transformer's language understanding with the robustness of graph neural network (GNN)-based neural algorithmic reasoners (NARs). Such NARs proved effective as generic solvers for algorithmic tasks, when specified in graph form. To make their embeddings accessible to a Transformer, we propose a hybrid architecture with a two-phase training procedure, allowing the tokens in the language model to cross-attend to the node embeddings from the NAR. We evaluate our resulting TransNAR model on CLRS-Text, the text-based version of the CLRS-30 benchmark, and demonstrate significant gains over Transformer-only models for algorithmic reasoning, both in and out of distribution.
The CLRS-Text Algorithmic Reasoning Language Benchmark
Jun 06, 2024

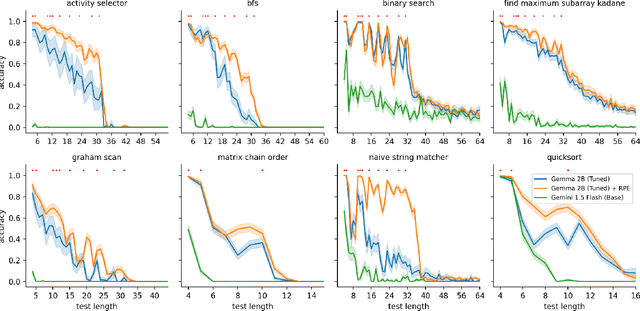
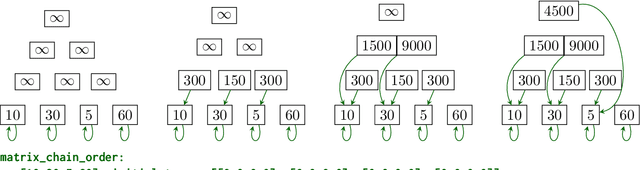
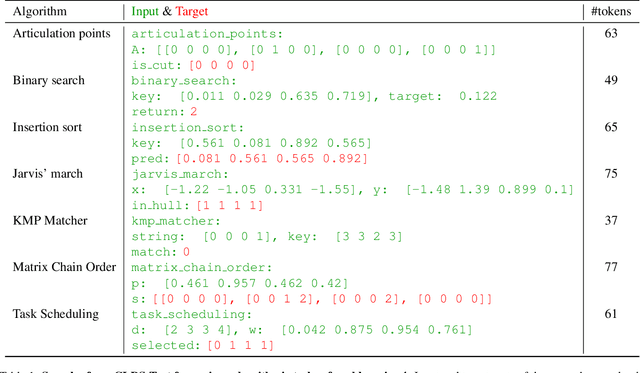
Eliciting reasoning capabilities from language models (LMs) is a critical direction on the path towards building intelligent systems. Most recent studies dedicated to reasoning focus on out-of-distribution performance on procedurally-generated synthetic benchmarks, bespoke-built to evaluate specific skills only. This trend makes results hard to transfer across publications, slowing down progress. Three years ago, a similar issue was identified and rectified in the field of neural algorithmic reasoning, with the advent of the CLRS benchmark. CLRS is a dataset generator comprising graph execution traces of classical algorithms from the Introduction to Algorithms textbook. Inspired by this, we propose CLRS-Text -- a textual version of these algorithmic traces. Out of the box, CLRS-Text is capable of procedurally generating trace data for thirty diverse, challenging algorithmic tasks across any desirable input distribution, while offering a standard pipeline in which any additional algorithmic tasks may be created in the benchmark. We fine-tune and evaluate various LMs as generalist executors on this benchmark, validating prior work and revealing a novel, interesting challenge for the LM reasoning community. Our code is available at https://github.com/google-deepmind/clrs/tree/master/clrs/_src/clrs_text.
Looking for a Handsome Carpenter! Debiasing GPT-3 Job Advertisements
May 23, 2022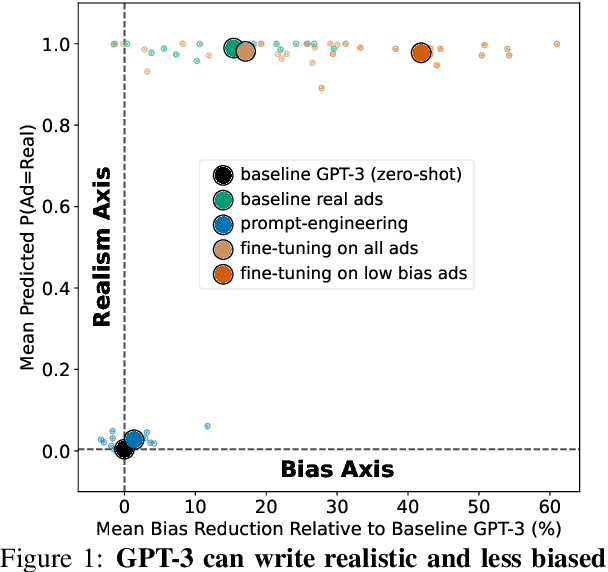
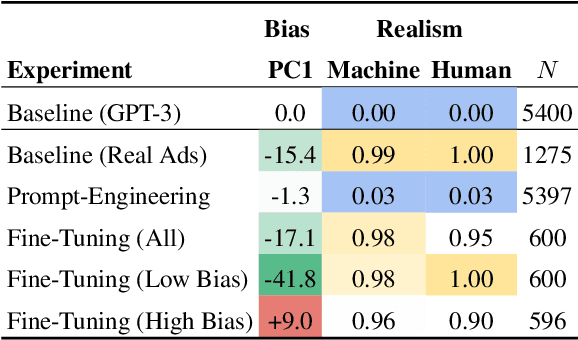
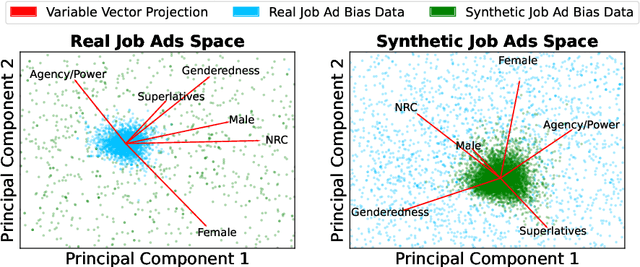
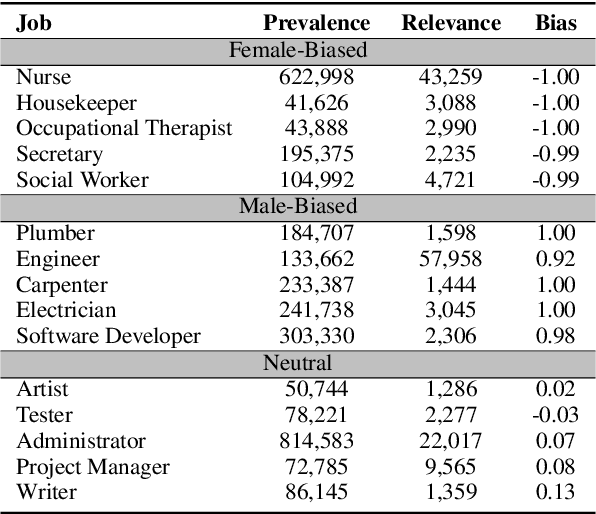
The growing capability and availability of generative language models has enabled a wide range of new downstream tasks. Academic research has identified, quantified and mitigated biases present in language models but is rarely tailored to downstream tasks where wider impact on individuals and society can be felt. In this work, we leverage one popular generative language model, GPT-3, with the goal of writing unbiased and realistic job advertisements. We first assess the bias and realism of zero-shot generated advertisements and compare them to real-world advertisements. We then evaluate prompt-engineering and fine-tuning as debiasing methods. We find that prompt-engineering with diversity-encouraging prompts gives no significant improvement to bias, nor realism. Conversely, fine-tuning, especially on unbiased real advertisements, can improve realism and reduce bias.