 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Context Compression at Scale
Jun 08, 2026Long-context language model inference is bottlenecked by memory, as the KV cache grows with context length. Recent techniques to compress the KV cache fall short: they either degrade model quality substantially or require considerable time and compute to compress a single long prompt. Furthermore, many methods require the input to fit within the target model's context window, and are generally incompatible with modern production inference engines. Encoder-decoder compressors, which map a long token sequence to a shorter sequence of latent embeddings consumed by a decoder, are an appealing alternative in principle. However, existing approaches are not competitive with KV cache compression on the accuracy-efficiency frontier. In this work, we revisit encoder-decoder compression and close this gap. We first perform an architecture search, pre-training many variants from scratch to determine how best to design and train encoder-decoder compressors. Guided by our findings, we continually pre-train a family of 0.6B-encoder, 4B-decoder models on over 350B tokens each, at compression ratios of 1:4, 1:8, and 1:16. We introduce Latent Context Language Models (LCLMs), a family of compressors that improve the Pareto frontier across general-task performance, compression speed, and peak memory usage. We demonstrate that LCLMs serve as efficient backbones for long-horizon agents, letting the agent skim through a compressed long context and adaptively expand relevant segments on demand.
Do Language Models Need Sleep? Offline Recurrence for Improved Online Inference
May 27, 2026Transformer-based large language models are increasingly used for long-horizon tasks; however, their attention mechanism scales poorly with context length. To handle this, we study a sleep-like consolidation mechanism in which a model periodically converts recent context into persistent fast weights before clearing its key-value cache. During sleep, the model performs $N$ offline recurrent passes over the accumulated context and updates the fast weights in its state-space model (SSM) blocks through a learned local rule. During inference, this shifts extra computation to sleep while preserving the latency of wake-time prediction. We test our method on controlled synthetic tasks, including cellular automata and multi-hop graph retrieval, as well as a realistic math reasoning task, on which a regular transformer as well as SSM-attention hybrid models fail. We then show that increasing sleep duration $N$ for our models improves performance, with the largest gains on examples that require deeper reasoning.
Teaching Pretrained Language Models to Think Deeper with Retrofitted Recurrence
Nov 10, 2025Recent advances in depth-recurrent language models show that recurrence can decouple train-time compute and parameter count from test-time compute. In this work, we study how to convert existing pretrained non-recurrent language models into depth-recurrent models. We find that using a curriculum of recurrences to increase the effective depth of the model over the course of training preserves performance while reducing total computational cost. In our experiments, on mathematics, we observe that converting pretrained models to recurrent ones results in better performance at a given compute budget than simply post-training the original non-recurrent language model.
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Feb 07, 2025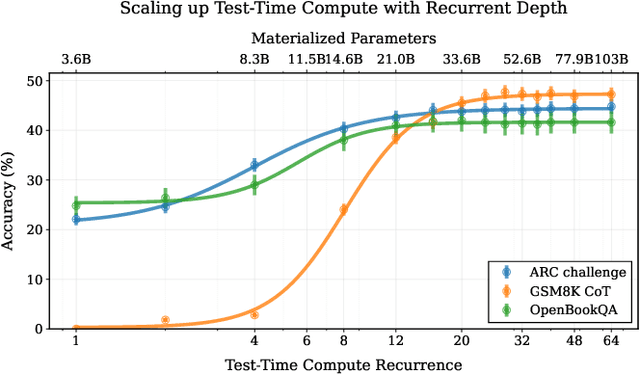
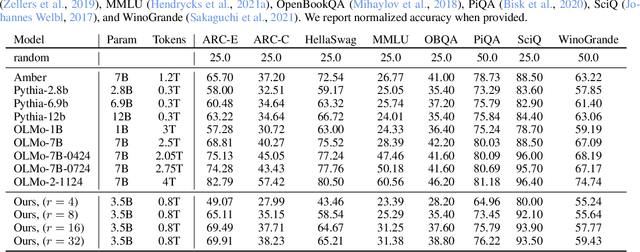
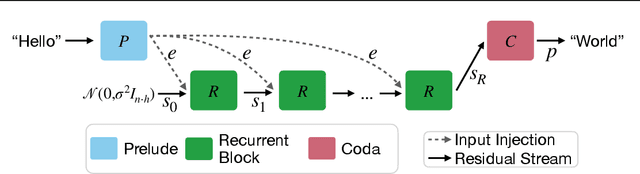
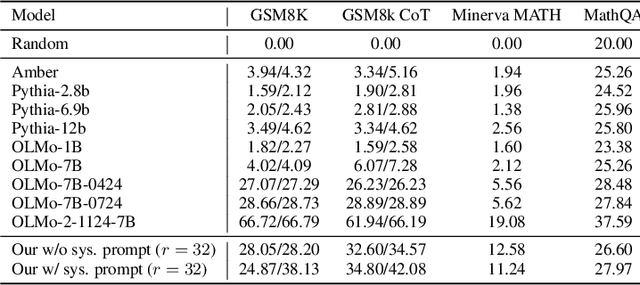
We study a novel language model architecture that is capable of scaling test-time computation by implicitly reasoning in latent space. Our model works by iterating a recurrent block, thereby unrolling to arbitrary depth at test-time. This stands in contrast to mainstream reasoning models that scale up compute by producing more tokens. Unlike approaches based on chain-of-thought, our approach does not require any specialized training data, can work with small context windows, and can capture types of reasoning that are not easily represented in words. We scale a proof-of-concept model to 3.5 billion parameters and 800 billion tokens. We show that the resulting model can improve its performance on reasoning benchmarks, sometimes dramatically, up to a computation load equivalent to 50 billion parameters.
Gemstones: A Model Suite for Multi-Faceted Scaling Laws
Feb 07, 2025



Scaling laws are typically fit using a family of models with a narrow range of frozen hyper-parameter choices. In this work we study scaling laws using a wide range of architecture and hyper-parameter choices, and highlight their impact on resulting prescriptions. As a primary artifact of our research, we release the Gemstones: the most comprehensive open-source scaling law dataset to date, consisting of over 4000 checkpoints from transformers with up to 2 billion parameters; these models have been trained with different learning rates, cooldown schedules, and architectural shapes. Our checkpoints enable more complex studies of scaling, such as a law that predicts language modeling performance as a function of model width and depth. By examining the various facets of our model suite, we find that the prescriptions of scaling laws can be highly sensitive to the experimental design process and the specific model checkpoints used during fitting. Code: https://github.com/mcleish7/gemstone-scaling-laws
The CLRS-Text Algorithmic Reasoning Language Benchmark
Jun 06, 2024

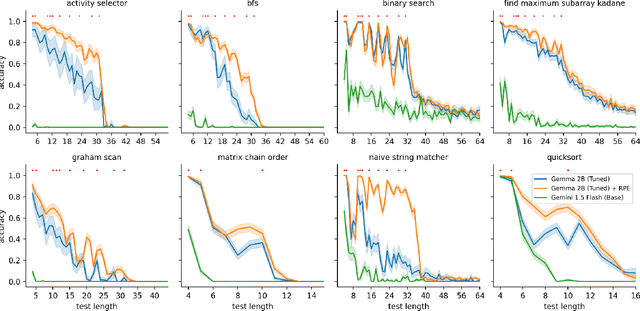
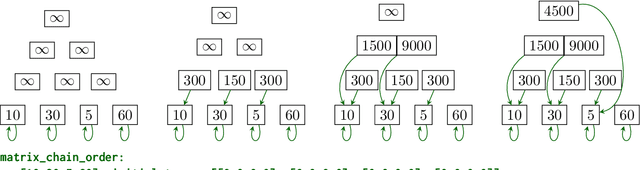
Eliciting reasoning capabilities from language models (LMs) is a critical direction on the path towards building intelligent systems. Most recent studies dedicated to reasoning focus on out-of-distribution performance on procedurally-generated synthetic benchmarks, bespoke-built to evaluate specific skills only. This trend makes results hard to transfer across publications, slowing down progress. Three years ago, a similar issue was identified and rectified in the field of neural algorithmic reasoning, with the advent of the CLRS benchmark. CLRS is a dataset generator comprising graph execution traces of classical algorithms from the Introduction to Algorithms textbook. Inspired by this, we propose CLRS-Text -- a textual version of these algorithmic traces. Out of the box, CLRS-Text is capable of procedurally generating trace data for thirty diverse, challenging algorithmic tasks across any desirable input distribution, while offering a standard pipeline in which any additional algorithmic tasks may be created in the benchmark. We fine-tune and evaluate various LMs as generalist executors on this benchmark, validating prior work and revealing a novel, interesting challenge for the LM reasoning community. Our code is available at https://github.com/google-deepmind/clrs/tree/master/clrs/_src/clrs_text.
Transformers Can Do Arithmetic with the Right Embeddings
May 27, 2024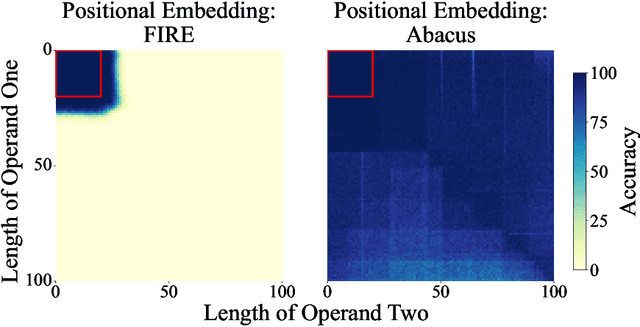
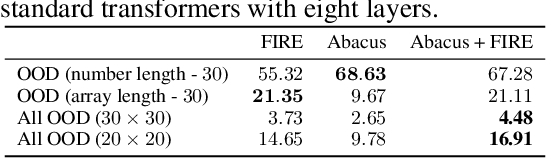

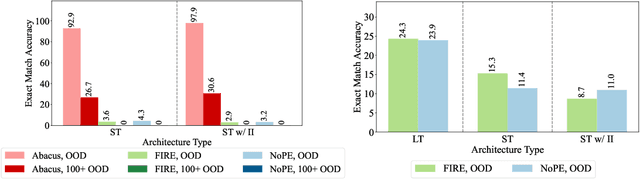
The poor performance of transformers on arithmetic tasks seems to stem in large part from their inability to keep track of the exact position of each digit inside of a large span of digits. We mend this problem by adding an embedding to each digit that encodes its position relative to the start of the number. In addition to the boost these embeddings provide on their own, we show that this fix enables architectural modifications such as input injection and recurrent layers to improve performance even further. With positions resolved, we can study the logical extrapolation ability of transformers. Can they solve arithmetic problems that are larger and more complex than those in their training data? We find that training on only 20 digit numbers with a single GPU for one day, we can reach state-of-the-art performance, achieving up to 99% accuracy on 100 digit addition problems. Finally, we show that these gains in numeracy also unlock improvements on other multi-step reasoning tasks including sorting and multiplication.
Benchmarking ChatGPT on Algorithmic Reasoning
Apr 04, 2024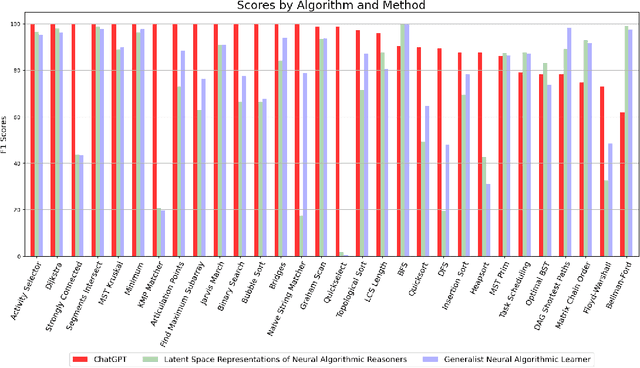


We evaluate ChatGPT's ability to solve algorithm problems from the CLRS benchmark suite that is designed for GNNs. The benchmark requires the use of a specified classical algorithm to solve a given problem. We find that ChatGPT outperforms specialist GNN models, using Python to successfully solve these problems. This raises new points in the discussion about learning algorithms with neural networks.