 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive label cleaning: Improving dataset quality under resource constraints
Paper and Code
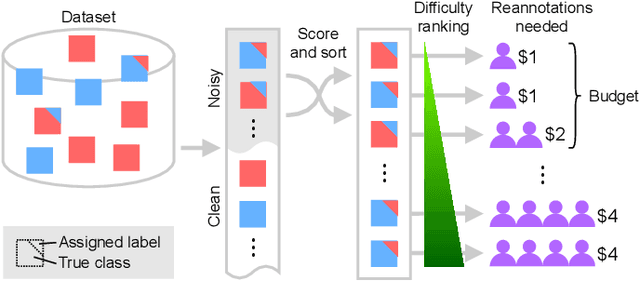
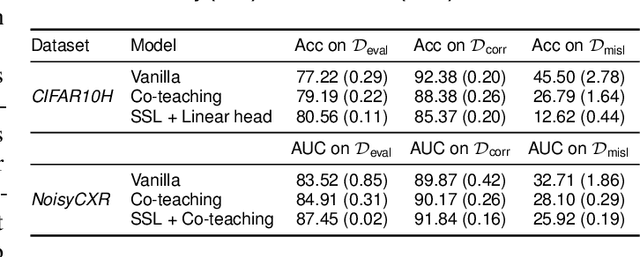
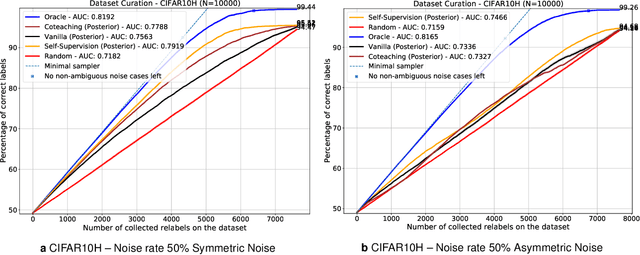
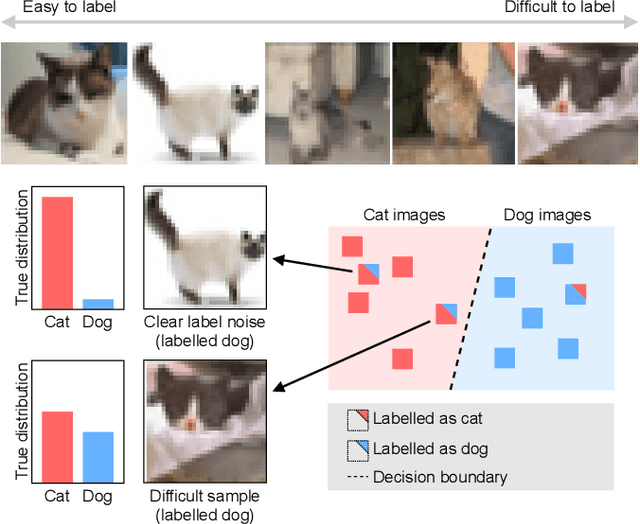
Imperfections in data annotation, known as label noise, are detrimental to the training of machine learning models and have an often-overlooked confounding effect on the assessment of model performance. Nevertheless, employing experts to remove label noise by fully re-annotating large datasets is infeasible in resource-constrained settings, such as healthcare. This work advocates for a data-driven approach to prioritising samples for re-annotation - which we term "active label cleaning". We propose to rank instances according to estimated label correctness and labelling difficulty of each sample, and introduce a simulation framework to evaluate relabelling efficacy. Our experiments on natural images and on a new medical imaging benchmark show that cleaning noisy labels mitigates their negative impact on model training, evaluation, and selection. Crucially, the proposed active label cleaning enables correcting labels up to 4 times more effectively than typical random selection in realistic conditions, making better use of experts' valuable time for improving dataset quality.