 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMILE-UHURA Challenge -- Small Vessel Segmentation at Mesoscopic Scale from Ultra-High Resolution 7T Magnetic Resonance Angiograms
Nov 14, 2024The human brain receives nutrients and oxygen through an intricate network of blood vessels. Pathology affecting small vessels, at the mesoscopic scale, represents a critical vulnerability within the cerebral blood supply and can lead to severe conditions, such as Cerebral Small Vessel Diseases. The advent of 7 Tesla MRI systems has enabled the acquisition of higher spatial resolution images, making it possible to visualise such vessels in the brain. However, the lack of publicly available annotated datasets has impeded the development of robust, machine learning-driven segmentation algorithms. To address this, the SMILE-UHURA challenge was organised. This challenge, held in conjunction with the ISBI 2023, in Cartagena de Indias, Colombia, aimed to provide a platform for researchers working on related topics. The SMILE-UHURA challenge addresses the gap in publicly available annotated datasets by providing an annotated dataset of Time-of-Flight angiography acquired with 7T MRI. This dataset was created through a combination of automated pre-segmentation and extensive manual refinement. In this manuscript, sixteen submitted methods and two baseline methods are compared both quantitatively and qualitatively on two different datasets: held-out test MRAs from the same dataset as the training data (with labels kept secret) and a separate 7T ToF MRA dataset where both input volumes and labels are kept secret. The results demonstrate that most of the submitted deep learning methods, trained on the provided training dataset, achieved reliable segmentation performance. Dice scores reached up to 0.838 $\pm$ 0.066 and 0.716 $\pm$ 0.125 on the respective datasets, with an average performance of up to 0.804 $\pm$ 0.15.
Facilitating phenotyping from clinical texts: the medkit library
Aug 30, 2024

Phenotyping consists in applying algorithms to identify individuals associated with a specific, potentially complex, trait or condition, typically out of a collection of Electronic Health Records (EHRs). Because a lot of the clinical information of EHRs are lying in texts, phenotyping from text takes an important role in studies that rely on the secondary use of EHRs. However, the heterogeneity and highly specialized aspect of both the content and form of clinical texts makes this task particularly tedious, and is the source of time and cost constraints in observational studies. To facilitate the development, evaluation and reproductibility of phenotyping pipelines, we developed an open-source Python library named medkit. It enables composing data processing pipelines made of easy-to-reuse software bricks, named medkit operations. In addition to the core of the library, we share the operations and pipelines we already developed and invite the phenotyping community for their reuse and enrichment. medkit is available at https://github.com/medkit-lib/medkit
Automatic View Planning with Multi-scale Deep Reinforcement Learning Agents
Jun 08, 2018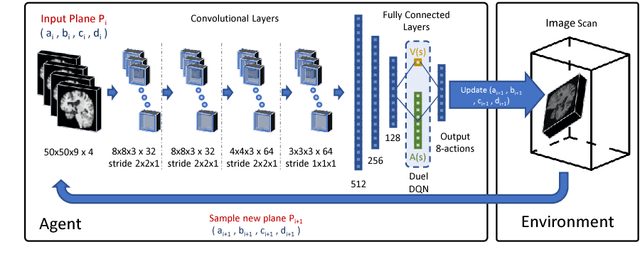
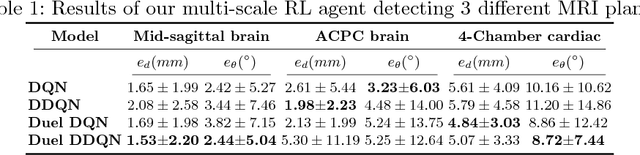
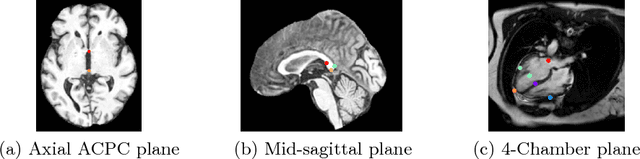
We propose a fully automatic method to find standardized view planes in 3D image acquisitions. Standard view images are important in clinical practice as they provide a means to perform biometric measurements from similar anatomical regions. These views are often constrained to the native orientation of a 3D image acquisition. Navigating through target anatomy to find the required view plane is tedious and operator-dependent. For this task, we employ a multi-scale reinforcement learning (RL) agent framework and extensively evaluate several Deep Q-Network (DQN) based strategies. RL enables a natural learning paradigm by interaction with the environment, which can be used to mimic experienced operators. We evaluate our results using the distance between the anatomical landmarks and detected planes, and the angles between their normal vector and target. The proposed algorithm is assessed on the mid-sagittal and anterior-posterior commissure planes of brain MRI, and the 4-chamber long-axis plane commonly used in cardiac MRI, achieving accuracy of 1.53mm, 1.98mm and 4.84mm, respectively.
Automated cardiovascular magnetic resonance image analysis with fully convolutional networks
May 22, 2018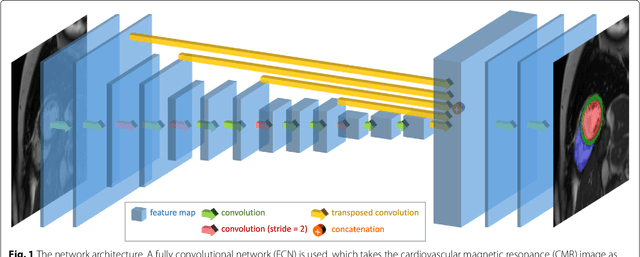

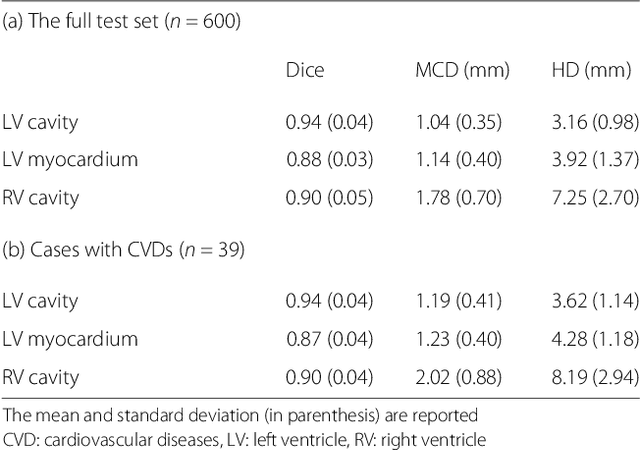
Cardiovascular magnetic resonance (CMR) imaging is a standard imaging modality for assessing cardiovascular diseases (CVDs), the leading cause of death globally. CMR enables accurate quantification of the cardiac chamber volume, ejection fraction and myocardial mass, providing information for diagnosis and monitoring of CVDs. However, for years, clinicians have been relying on manual approaches for CMR image analysis, which is time consuming and prone to subjective errors. It is a major clinical challenge to automatically derive quantitative and clinically relevant information from CMR images. Deep neural networks have shown a great potential in image pattern recognition and segmentation for a variety of tasks. Here we demonstrate an automated analysis method for CMR images, which is based on a fully convolutional network (FCN). The network is trained and evaluated on a large-scale dataset from the UK Biobank, consisting of 4,875 subjects with 93,500 pixelwise annotated images. The performance of the method has been evaluated using a number of technical metrics, including the Dice metric, mean contour distance and Hausdorff distance, as well as clinically relevant measures, including left ventricle (LV) end-diastolic volume (LVEDV) and end-systolic volume (LVESV), LV mass (LVM); right ventricle (RV) end-diastolic volume (RVEDV) and end-systolic volume (RVESV). By combining FCN with a large-scale annotated dataset, the proposed automated method achieves a high performance on par with human experts in segmenting the LV and RV on short-axis CMR images and the left atrium (LA) and right atrium (RA) on long-axis CMR images.