 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Inference as a Model of Agency
Jan 23, 2024



Is there a canonical way to think of agency beyond reward maximisation? In this paper, we show that any type of behaviour complying with physically sound assumptions about how macroscopic biological agents interact with the world canonically integrates exploration and exploitation in the sense of minimising risk and ambiguity about states of the world. This description, known as active inference, refines the free energy principle, a popular descriptive framework for action and perception originating in neuroscience. Active inference provides a normative Bayesian framework to simulate and model agency that is widely used in behavioural neuroscience, reinforcement learning (RL) and robotics. The usefulness of active inference for RL is three-fold. \emph{a}) Active inference provides a principled solution to the exploration-exploitation dilemma that usefully simulates biological agency. \emph{b}) It provides an explainable recipe to simulate behaviour, whence behaviour follows as an explainable mixture of exploration and exploitation under a generative world model, and all differences in behaviour are explicit in differences in world model. \emph{c}) This framework is universal in the sense that it is theoretically possible to rewrite any RL algorithm conforming to the descriptive assumptions of active inference as an active inference algorithm. Thus, active inference can be used as a tool to uncover and compare the commitments and assumptions of more specific models of agency.
Learning What and Where to Draw
Oct 08, 2016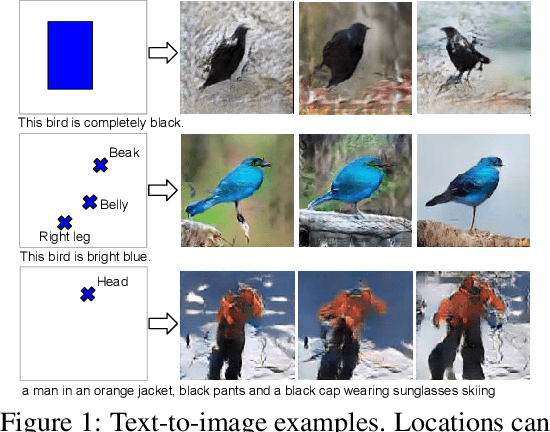
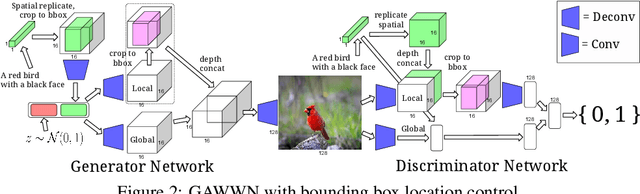
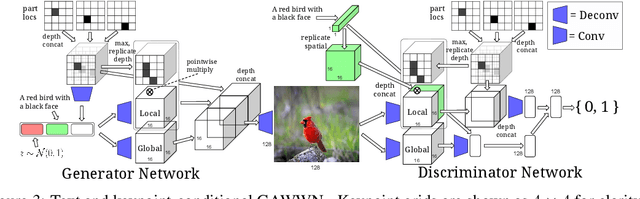
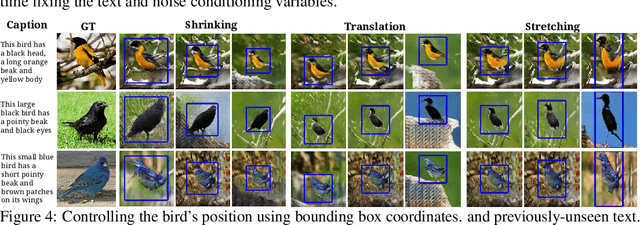
Generative Adversarial Networks (GANs) have recently demonstrated the capability to synthesize compelling real-world images, such as room interiors, album covers, manga, faces, birds, and flowers. While existing models can synthesize images based on global constraints such as a class label or caption, they do not provide control over pose or object location. We propose a new model, the Generative Adversarial What-Where Network (GAWWN), that synthesizes images given instructions describing what content to draw in which location. We show high-quality 128 x 128 image synthesis on the Caltech-UCSD Birds dataset, conditioned on both informal text descriptions and also object location. Our system exposes control over both the bounding box around the bird and its constituent parts. By modeling the conditional distributions over part locations, our system also enables conditioning on arbitrary subsets of parts (e.g. only the beak and tail), yielding an efficient interface for picking part locations. We also show preliminary results on the more challenging domain of text- and location-controllable synthesis of images of human actions on the MPII Human Pose dataset.