 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Animal-AI Environment: Training and Testing Animal-Like Artificial Cognition
Sep 18, 2019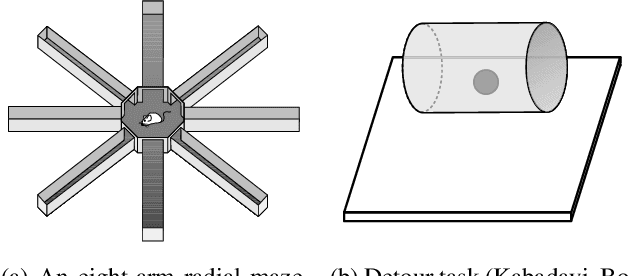


Recent advances in artificial intelligence have been strongly driven by the use of game environments for training and evaluating agents. Games are often accessible and versatile, with well-defined state-transitions and goals allowing for intensive training and experimentation. However, agents trained in a particular environment are usually tested on the same or slightly varied distributions, and solutions do not necessarily imply any understanding. If we want AI systems that can model and understand their environment, we need environments that explicitly test for this. Inspired by the extensive literature on animal cognition, we present an environment that keeps all the positive elements of standard gaming environments, but is explicitly designed for the testing of animal-like artificial cognition.
Dot-to-Dot: Achieving Structured Robotic Manipulation through Hierarchical Reinforcement Learning
Apr 14, 2019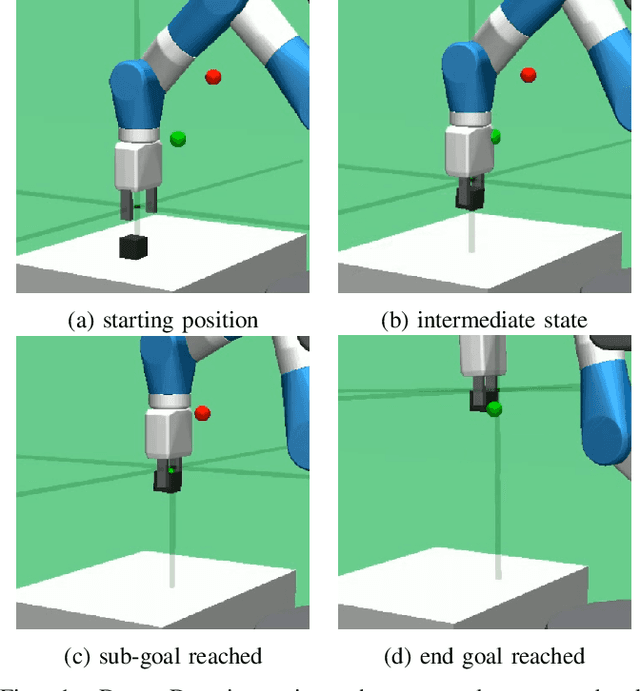
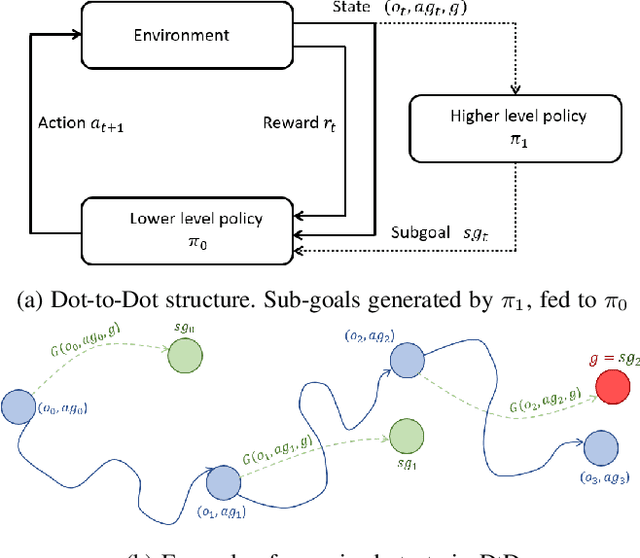
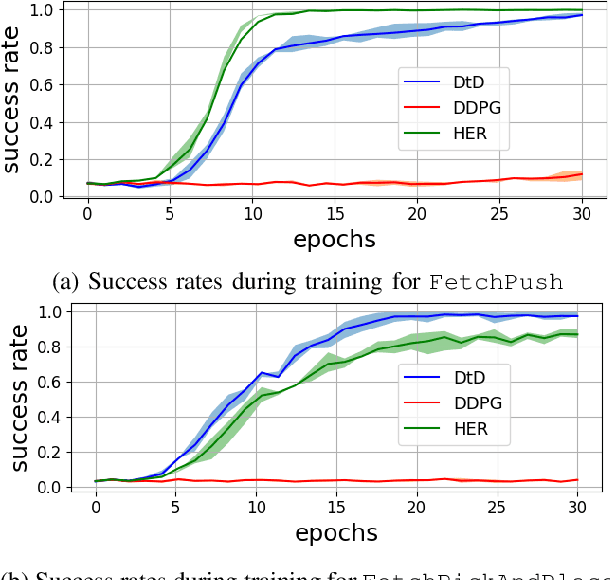
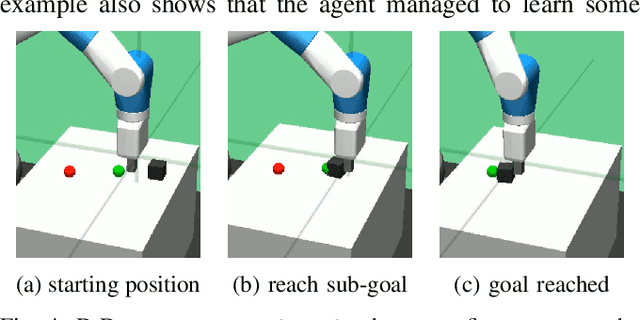
Robotic systems are ever more capable of automation and fulfilment of complex tasks, particularly with reliance on recent advances in intelligent systems, deep learning and artificial intelligence in general. However, as robots and humans come closer together in their interactions, the matter of interpretability, or explainability of robot decision-making processes for the human grows in importance. A successful interaction and collaboration would only be possible through mutual understanding of underlying representations of the environment and the task at hand. This is currently a challenge in deep learning systems. We present a hierarchical deep reinforcement learning system, consisting of a low-level agent handling the large actions/states space of a robotic system efficiently, by following the directives of a high-level agent which is learning the high-level dynamics of the environment and task. This high-level agent forms a representation of the world and task at hand that is interpretable for a human operator. The method, which we call Dot-to-Dot, is tested on a MuJoCo-based model of the Fetch Robotics Manipulator, as well as a Shadow Hand, to test its performance. Results show efficient learning of complex actions/states spaces by the low-level agent, and an interpretable representation of the task and decision-making process learned by the high-level agent.