 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Exploration from Language Abstractions and Pretrained Representations
Apr 08, 2022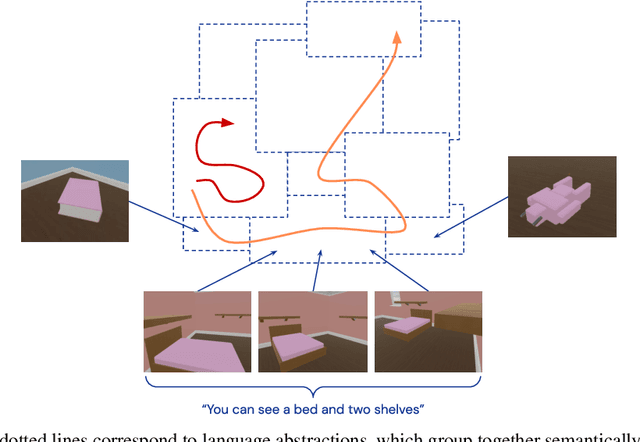


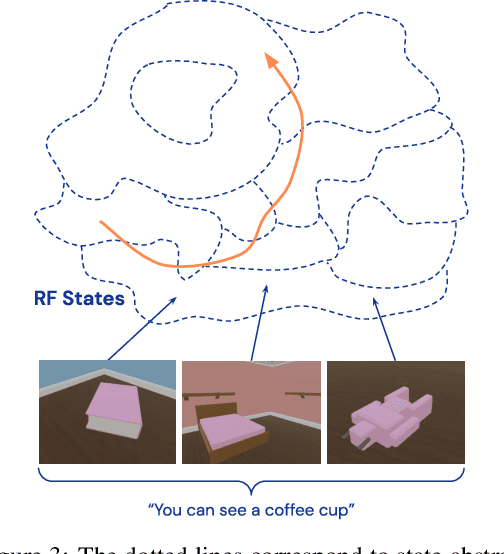
Continuous first-person 3D environments pose unique exploration challenges to reinforcement learning (RL) agents because of their high-dimensional state and action spaces. These challenges can be ameliorated by using semantically meaningful state abstractions to define novelty for exploration. We propose that learned representations shaped by natural language provide exactly this form of abstraction. In particular, we show that vision-language representations, when pretrained on image captioning datasets sampled from the internet, can drive meaningful, task-relevant exploration and improve performance on 3D simulated environments. We also characterize why and how language provides useful abstractions for exploration by comparing the impacts of using representations from a pretrained model, a language oracle, and several ablations. We demonstrate the benefits of our approach in two very different task domains -- one that stresses the identification and manipulation of everyday objects, and one that requires navigational exploration in an expansive world -- as well as two popular deep RL algorithms: Impala and R2D2. Our results suggest that using language-shaped representations could improve exploration for various algorithms and agents in challenging environments.
Tell me why! -- Explanations support learning of relational and causal structure
Dec 08, 2021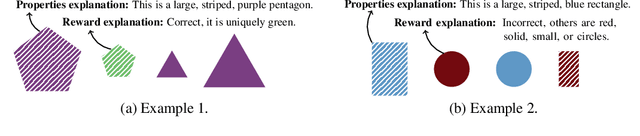
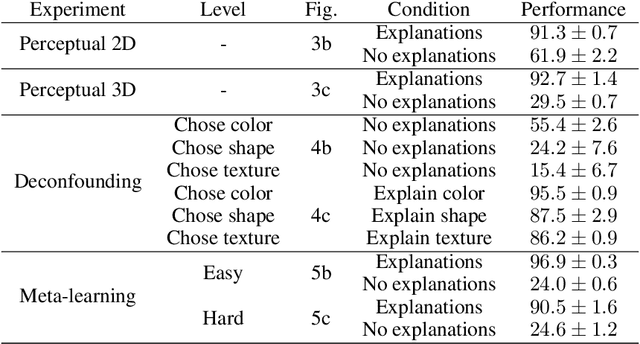
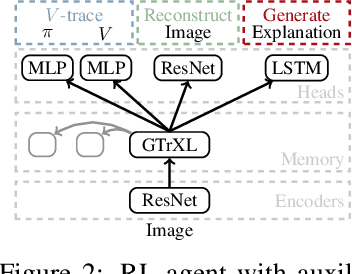
Explanations play a considerable role in human learning, especially in areas that remain major challenges for AI -- forming abstractions, and learning about the relational and causal structure of the world. Here, we explore whether reinforcement learning agents might likewise benefit from explanations. We outline a family of relational tasks that involve selecting an object that is the odd one out in a set (i.e., unique along one of many possible feature dimensions). Odd-one-out tasks require agents to reason over multi-dimensional relationships among a set of objects. We show that agents do not learn these tasks well from reward alone, but achieve >90% performance when they are also trained to generate language explaining object properties or why a choice is correct or incorrect. In further experiments, we show how predicting explanations enables agents to generalize appropriately from ambiguous, causally-confounded training, and even to meta-learn to perform experimental interventions to identify causal structure. We show that explanations help overcome the tendency of agents to fixate on simple features, and explore which aspects of explanations make them most beneficial. Our results suggest that learning from explanations is a powerful principle that could offer a promising path towards training more robust and general machine learning systems.
Meta-learners' learning dynamics are unlike learners'
May 03, 2019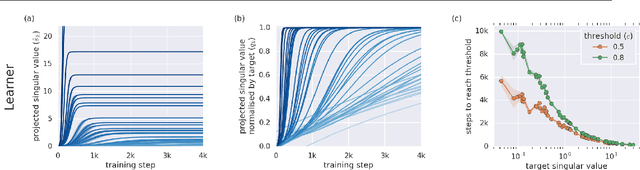
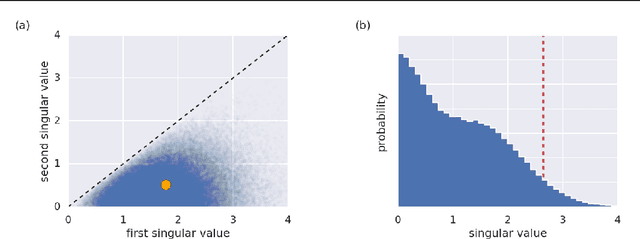
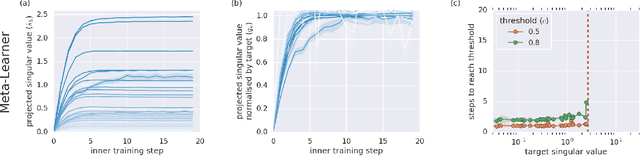
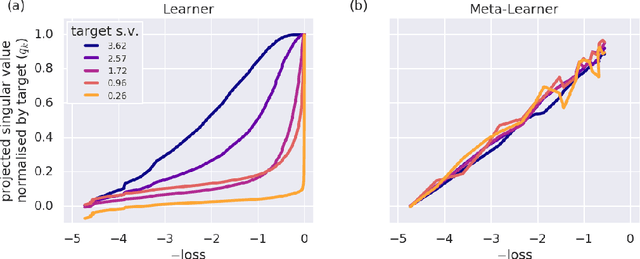
Meta-learning is a tool that allows us to build sample-efficient learning systems. Here we show that, once meta-trained, LSTM Meta-Learners aren't just faster learners than their sample-inefficient deep learning (DL) and reinforcement learning (RL) brethren, but that they actually pursue fundamentally different learning trajectories. We study their learning dynamics on three sets of structured tasks for which the corresponding learning dynamics of DL and RL systems have been previously described: linear regression (Saxe et al., 2013), nonlinear regression (Rahaman et al., 2018; Xu et al., 2018), and contextual bandits (Schaul et al., 2019). In each case, while sample-inefficient DL and RL Learners uncover the task structure in a staggered manner, meta-trained LSTM Meta-Learners uncover almost all task structure concurrently, congruent with the patterns expected from Bayes-optimal inference algorithms. This has implications for research areas wherever the learning behaviour itself is of interest, such as safety, curriculum design, and human-in-the-loop machine learning.
Relational Forward Models for Multi-Agent Learning
Sep 28, 2018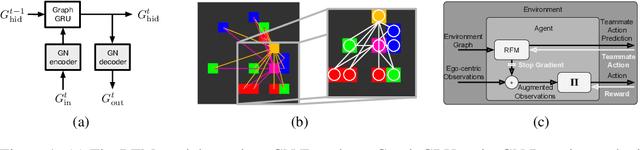
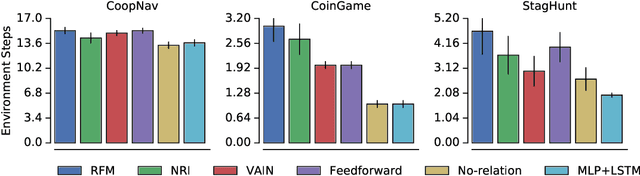
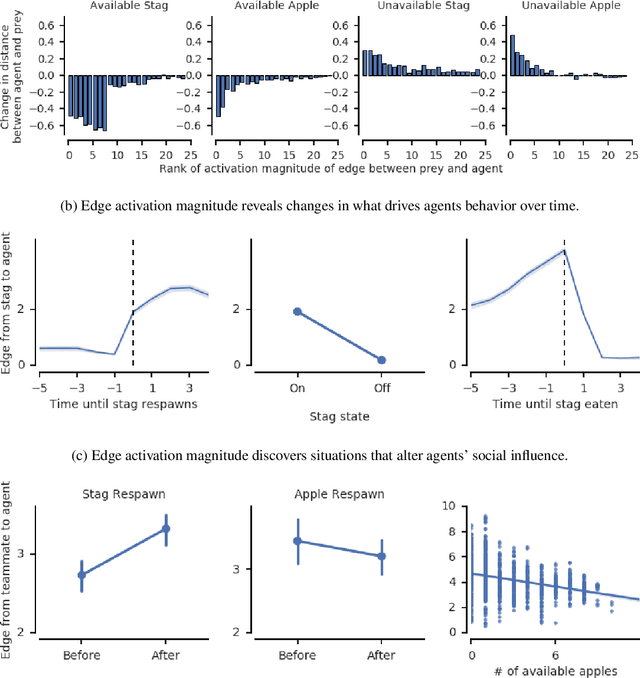
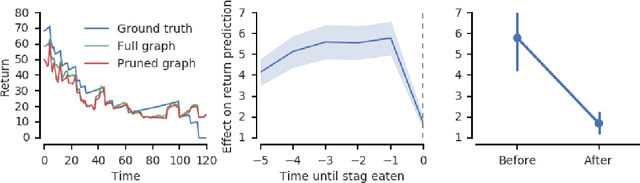
The behavioral dynamics of multi-agent systems have a rich and orderly structure, which can be leveraged to understand these systems, and to improve how artificial agents learn to operate in them. Here we introduce Relational Forward Models (RFM) for multi-agent learning, networks that can learn to make accurate predictions of agents' future behavior in multi-agent environments. Because these models operate on the discrete entities and relations present in the environment, they produce interpretable intermediate representations which offer insights into what drives agents' behavior, and what events mediate the intensity and valence of social interactions. Furthermore, we show that embedding RFM modules inside agents results in faster learning systems compared to non-augmented baselines. As more and more of the autonomous systems we develop and interact with become multi-agent in nature, developing richer analysis tools for characterizing how and why agents make decisions is increasingly necessary. Moreover, developing artificial agents that quickly and safely learn to coordinate with one another, and with humans in shared environments, is crucial.
Human-level performance in first-person multiplayer games with population-based deep reinforcement learning
Jul 03, 2018Recent progress in artificial intelligence through reinforcement learning (RL) has shown great success on increasingly complex single-agent environments and two-player turn-based games. However, the real-world contains multiple agents, each learning and acting independently to cooperate and compete with other agents, and environments reflecting this degree of complexity remain an open challenge. In this work, we demonstrate for the first time that an agent can achieve human-level in a popular 3D multiplayer first-person video game, Quake III Arena Capture the Flag, using only pixels and game points as input. These results were achieved by a novel two-tier optimisation process in which a population of independent RL agents are trained concurrently from thousands of parallel matches with agents playing in teams together and against each other on randomly generated environments. Each agent in the population learns its own internal reward signal to complement the sparse delayed reward from winning, and selects actions using a novel temporally hierarchical representation that enables the agent to reason at multiple timescales. During game-play, these agents display human-like behaviours such as navigating, following, and defending based on a rich learned representation that is shown to encode high-level game knowledge. In an extensive tournament-style evaluation the trained agents exceeded the win-rate of strong human players both as teammates and opponents, and proved far stronger than existing state-of-the-art agents. These results demonstrate a significant jump in the capabilities of artificial agents, bringing us closer to the goal of human-level intelligence.
Pooling is neither necessary nor sufficient for appropriate deformation stability in CNNs
May 25, 2018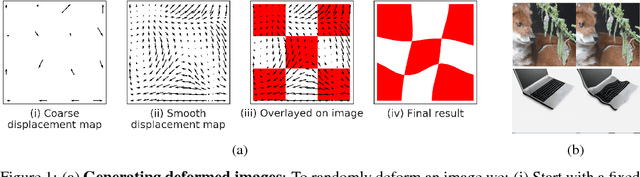
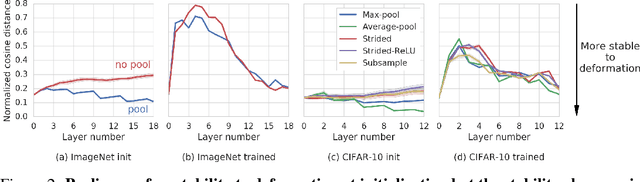
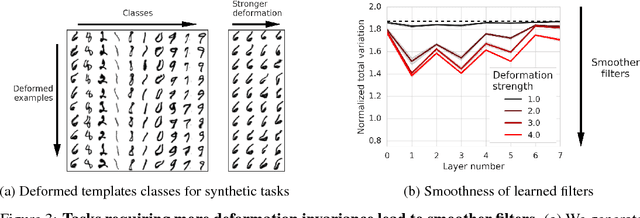
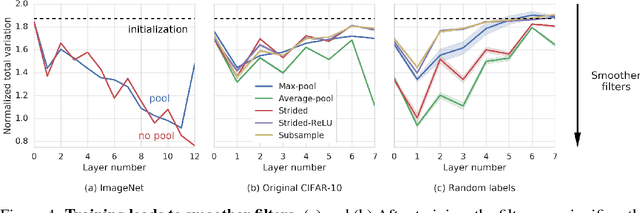
Many of our core assumptions about how neural networks operate remain empirically untested. One common assumption is that convolutional neural networks need to be stable to small translations and deformations to solve image recognition tasks. For many years, this stability was baked into CNN architectures by incorporating interleaved pooling layers. Recently, however, interleaved pooling has largely been abandoned. This raises a number of questions: Are our intuitions about deformation stability right at all? Is it important? Is pooling necessary for deformation invariance? If not, how is deformation invariance achieved in its absence? In this work, we rigorously test these questions, and find that deformation stability in convolutional networks is more nuanced than it first appears: (1) Deformation invariance is not a binary property, but rather that different tasks require different degrees of deformation stability at different layers. (2) Deformation stability is not a fixed property of a network and is heavily adjusted over the course of training, largely through the smoothness of the convolutional filters. (3) Interleaved pooling layers are neither necessary nor sufficient for achieving the optimal form of deformation stability for natural image classification. (4) Pooling confers too much deformation stability for image classification at initialization, and during training, networks have to learn to counteract this inductive bias. Together, these findings provide new insights into the role of interleaved pooling and deformation invariance in CNNs, and demonstrate the importance of rigorous empirical testing of even our most basic assumptions about the working of neural networks.
On the importance of single directions for generalization
May 22, 2018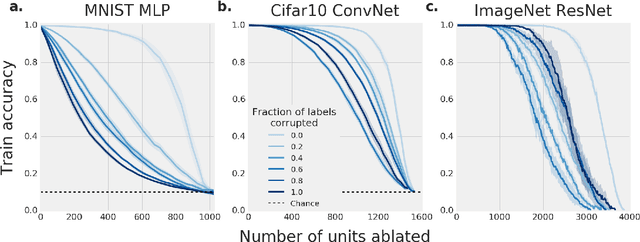
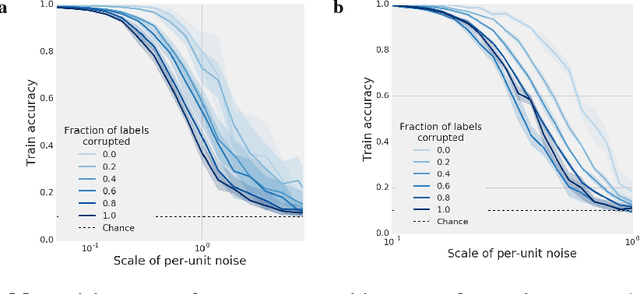
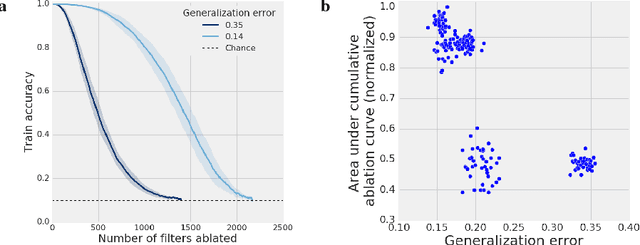
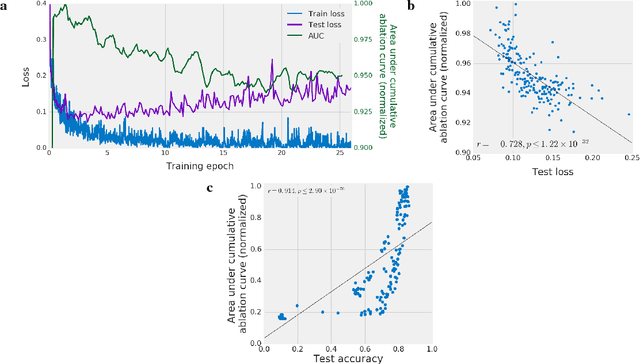
Despite their ability to memorize large datasets, deep neural networks often achieve good generalization performance. However, the differences between the learned solutions of networks which generalize and those which do not remain unclear. Additionally, the tuning properties of single directions (defined as the activation of a single unit or some linear combination of units in response to some input) have been highlighted, but their importance has not been evaluated. Here, we connect these lines of inquiry to demonstrate that a network's reliance on single directions is a good predictor of its generalization performance, across networks trained on datasets with different fractions of corrupted labels, across ensembles of networks trained on datasets with unmodified labels, across different hyperparameters, and over the course of training. While dropout only regularizes this quantity up to a point, batch normalization implicitly discourages single direction reliance, in part by decreasing the class selectivity of individual units. Finally, we find that class selectivity is a poor predictor of task importance, suggesting not only that networks which generalize well minimize their dependence on individual units by reducing their selectivity, but also that individually selective units may not be necessary for strong network performance.
Machine Theory of Mind
Mar 12, 2018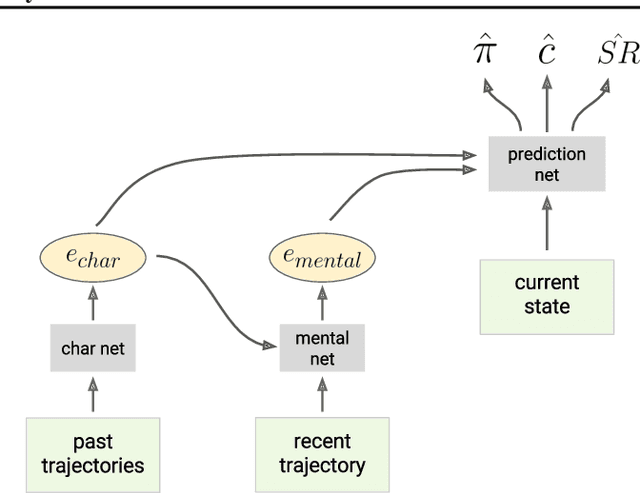
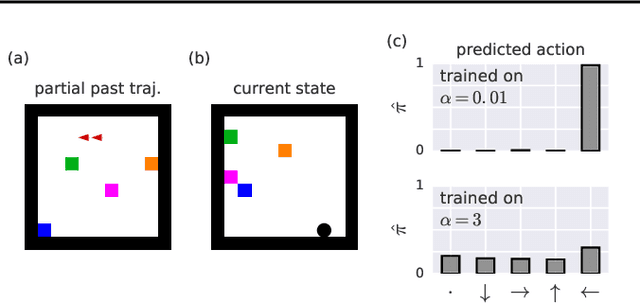
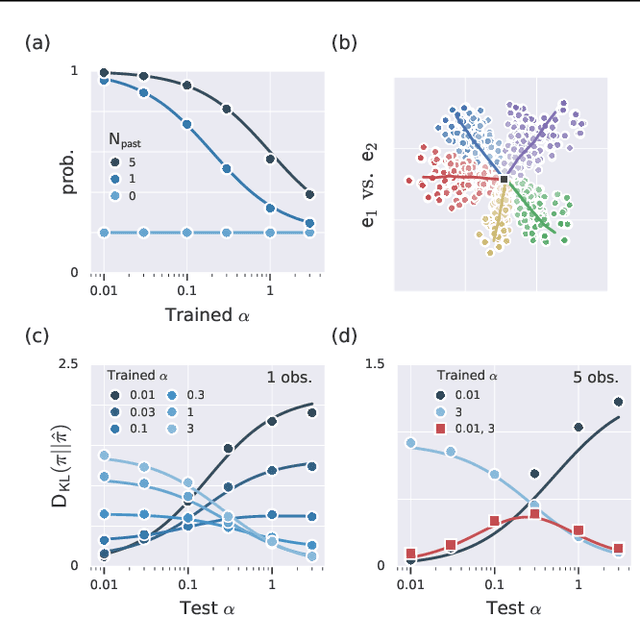
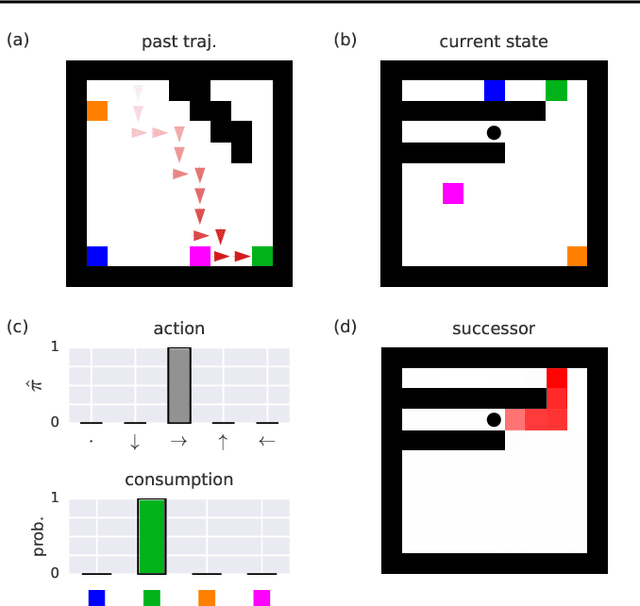
Theory of mind (ToM; Premack & Woodruff, 1978) broadly refers to humans' ability to represent the mental states of others, including their desires, beliefs, and intentions. We propose to train a machine to build such models too. We design a Theory of Mind neural network -- a ToMnet -- which uses meta-learning to build models of the agents it encounters, from observations of their behaviour alone. Through this process, it acquires a strong prior model for agents' behaviour, as well as the ability to bootstrap to richer predictions about agents' characteristics and mental states using only a small number of behavioural observations. We apply the ToMnet to agents behaving in simple gridworld environments, showing that it learns to model random, algorithmic, and deep reinforcement learning agents from varied populations, and that it passes classic ToM tasks such as the "Sally-Anne" test (Wimmer & Perner, 1983; Baron-Cohen et al., 1985) of recognising that others can hold false beliefs about the world. We argue that this system -- which autonomously learns how to model other agents in its world -- is an important step forward for developing multi-agent AI systems, for building intermediating technology for machine-human interaction, and for advancing the progress on interpretable AI.
Progressive Neural Networks
Sep 07, 2016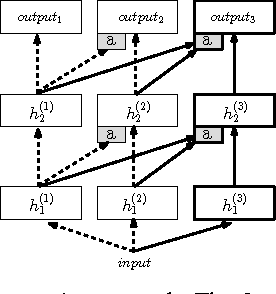
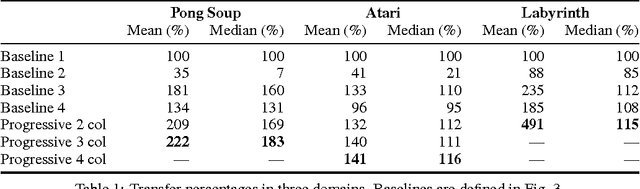

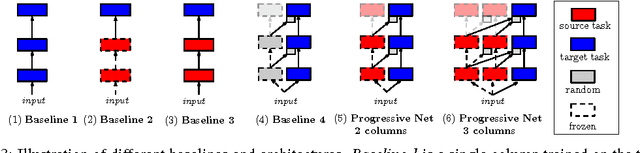
Learning to solve complex sequences of tasks--while both leveraging transfer and avoiding catastrophic forgetting--remains a key obstacle to achieving human-level intelligence. The progressive networks approach represents a step forward in this direction: they are immune to forgetting and can leverage prior knowledge via lateral connections to previously learned features. We evaluate this architecture extensively on a wide variety of reinforcement learning tasks (Atari and 3D maze games), and show that it outperforms common baselines based on pretraining and finetuning. Using a novel sensitivity measure, we demonstrate that transfer occurs at both low-level sensory and high-level control layers of the learned policy.
A model of sensory neural responses in the presence of unknown modulatory inputs
Jul 07, 2015
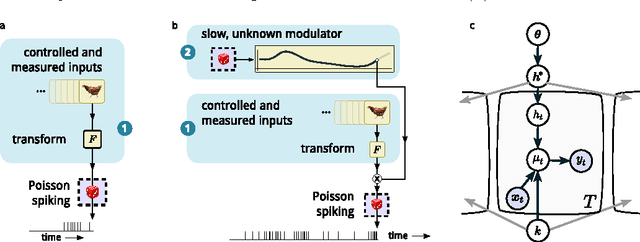
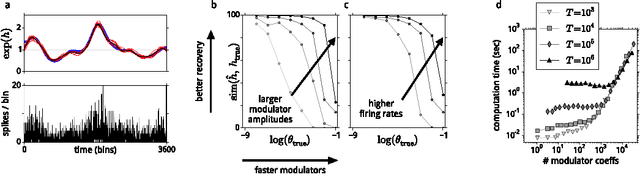
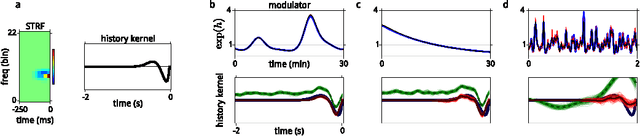
Neural responses are highly variable, and some portion of this variability arises from fluctuations in modulatory factors that alter their gain, such as adaptation, attention, arousal, expected or actual reward, emotion, and local metabolic resource availability. Regardless of their origin, fluctuations in these signals can confound or bias the inferences that one derives from spiking responses. Recent work demonstrates that for sensory neurons, these effects can be captured by a modulated Poisson model, whose rate is the product of a stimulus-driven response function and an unknown modulatory signal. Here, we extend this model, by incorporating explicit modulatory elements that are known (specifically, spike-history dependence, as in previous models), and by constraining the remaining latent modulatory signals to be smooth in time. We develop inference procedures for fitting the entire model, including hyperparameters, via evidence optimization, and apply these to simulated data, and to responses of ferret auditory midbrain and cortical neurons to complex sounds. We show that integrating out the latent modulators yields better (or more readily-interpretable) receptive field estimates than a standard Poisson model. Conversely, integrating out the stimulus dependence yields estimates of the slowly-varying latent modulators.