 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learners' learning dynamics are unlike learners'
Paper and Code
May 03, 2019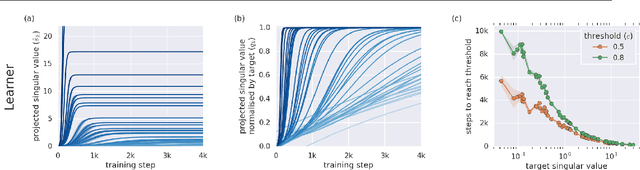
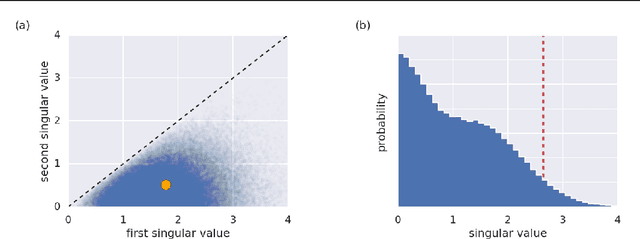
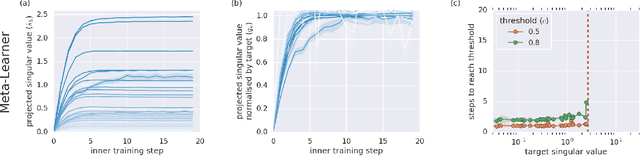
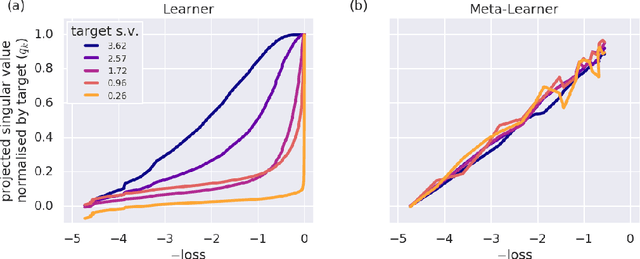
Meta-learning is a tool that allows us to build sample-efficient learning systems. Here we show that, once meta-trained, LSTM Meta-Learners aren't just faster learners than their sample-inefficient deep learning (DL) and reinforcement learning (RL) brethren, but that they actually pursue fundamentally different learning trajectories. We study their learning dynamics on three sets of structured tasks for which the corresponding learning dynamics of DL and RL systems have been previously described: linear regression (Saxe et al., 2013), nonlinear regression (Rahaman et al., 2018; Xu et al., 2018), and contextual bandits (Schaul et al., 2019). In each case, while sample-inefficient DL and RL Learners uncover the task structure in a staggered manner, meta-trained LSTM Meta-Learners uncover almost all task structure concurrently, congruent with the patterns expected from Bayes-optimal inference algorithms. This has implications for research areas wherever the learning behaviour itself is of interest, such as safety, curriculum design, and human-in-the-loop machine learning.