 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSI Draft Specification
May 02, 2022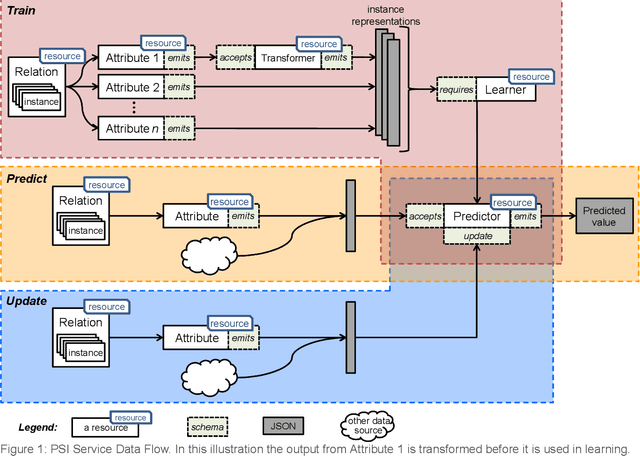
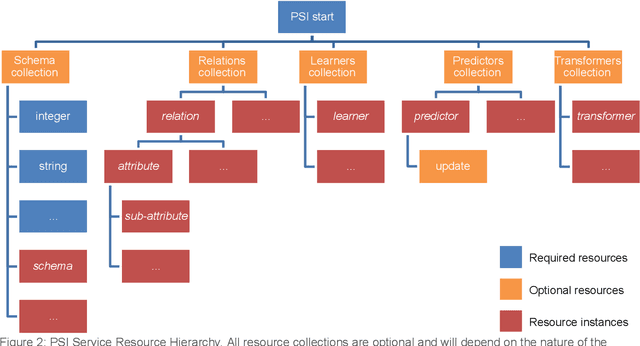
This document presents the draft specification for delivering machine learning services over HTTP, developed as part of the Protocols and Structures for Inference project, which concluded in 2013. It presents the motivation for providing machine learning as a service, followed by a description of the essential and optional components of such a service.
Rigorous Agent Evaluation: An Adversarial Approach to Uncover Catastrophic Failures
Dec 04, 2018
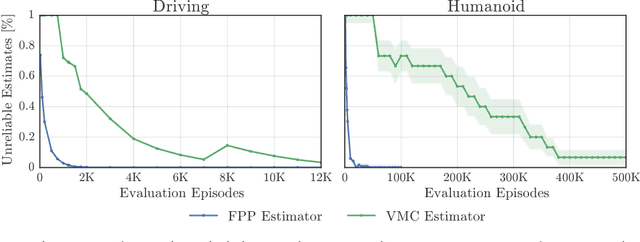
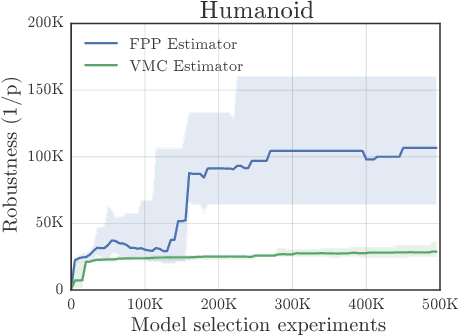

This paper addresses the problem of evaluating learning systems in safety critical domains such as autonomous driving, where failures can have catastrophic consequences. We focus on two problems: searching for scenarios when learned agents fail and assessing their probability of failure. The standard method for agent evaluation in reinforcement learning, Vanilla Monte Carlo, can miss failures entirely, leading to the deployment of unsafe agents. We demonstrate this is an issue for current agents, where even matching the compute used for training is sometimes insufficient for evaluation. To address this shortcoming, we draw upon the rare event probability estimation literature and propose an adversarial evaluation approach. Our approach focuses evaluation on adversarially chosen situations, while still providing unbiased estimates of failure probabilities. The key difficulty is in identifying these adversarial situations -- since failures are rare there is little signal to drive optimization. To solve this we propose a continuation approach that learns failure modes in related but less robust agents. Our approach also allows reuse of data already collected for training the agent. We demonstrate the efficacy of adversarial evaluation on two standard domains: humanoid control and simulated driving. Experimental results show that our methods can find catastrophic failures and estimate failures rates of agents multiple orders of magnitude faster than standard evaluation schemes, in minutes to hours rather than days.
Human-level performance in first-person multiplayer games with population-based deep reinforcement learning
Jul 03, 2018Recent progress in artificial intelligence through reinforcement learning (RL) has shown great success on increasingly complex single-agent environments and two-player turn-based games. However, the real-world contains multiple agents, each learning and acting independently to cooperate and compete with other agents, and environments reflecting this degree of complexity remain an open challenge. In this work, we demonstrate for the first time that an agent can achieve human-level in a popular 3D multiplayer first-person video game, Quake III Arena Capture the Flag, using only pixels and game points as input. These results were achieved by a novel two-tier optimisation process in which a population of independent RL agents are trained concurrently from thousands of parallel matches with agents playing in teams together and against each other on randomly generated environments. Each agent in the population learns its own internal reward signal to complement the sparse delayed reward from winning, and selects actions using a novel temporally hierarchical representation that enables the agent to reason at multiple timescales. During game-play, these agents display human-like behaviours such as navigating, following, and defending based on a rich learned representation that is shown to encode high-level game knowledge. In an extensive tournament-style evaluation the trained agents exceeded the win-rate of strong human players both as teammates and opponents, and proved far stronger than existing state-of-the-art agents. These results demonstrate a significant jump in the capabilities of artificial agents, bringing us closer to the goal of human-level intelligence.
Pooling is neither necessary nor sufficient for appropriate deformation stability in CNNs
May 25, 2018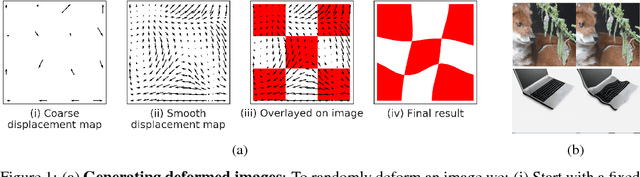
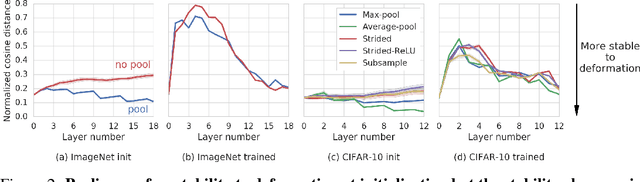
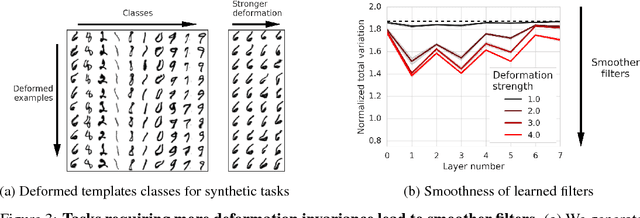
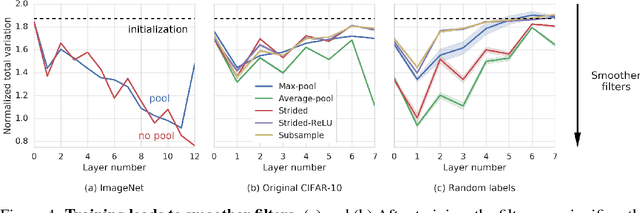
Many of our core assumptions about how neural networks operate remain empirically untested. One common assumption is that convolutional neural networks need to be stable to small translations and deformations to solve image recognition tasks. For many years, this stability was baked into CNN architectures by incorporating interleaved pooling layers. Recently, however, interleaved pooling has largely been abandoned. This raises a number of questions: Are our intuitions about deformation stability right at all? Is it important? Is pooling necessary for deformation invariance? If not, how is deformation invariance achieved in its absence? In this work, we rigorously test these questions, and find that deformation stability in convolutional networks is more nuanced than it first appears: (1) Deformation invariance is not a binary property, but rather that different tasks require different degrees of deformation stability at different layers. (2) Deformation stability is not a fixed property of a network and is heavily adjusted over the course of training, largely through the smoothness of the convolutional filters. (3) Interleaved pooling layers are neither necessary nor sufficient for achieving the optimal form of deformation stability for natural image classification. (4) Pooling confers too much deformation stability for image classification at initialization, and during training, networks have to learn to counteract this inductive bias. Together, these findings provide new insights into the role of interleaved pooling and deformation invariance in CNNs, and demonstrate the importance of rigorous empirical testing of even our most basic assumptions about the working of neural networks.
Model-Free Episodic Control
Jun 14, 2016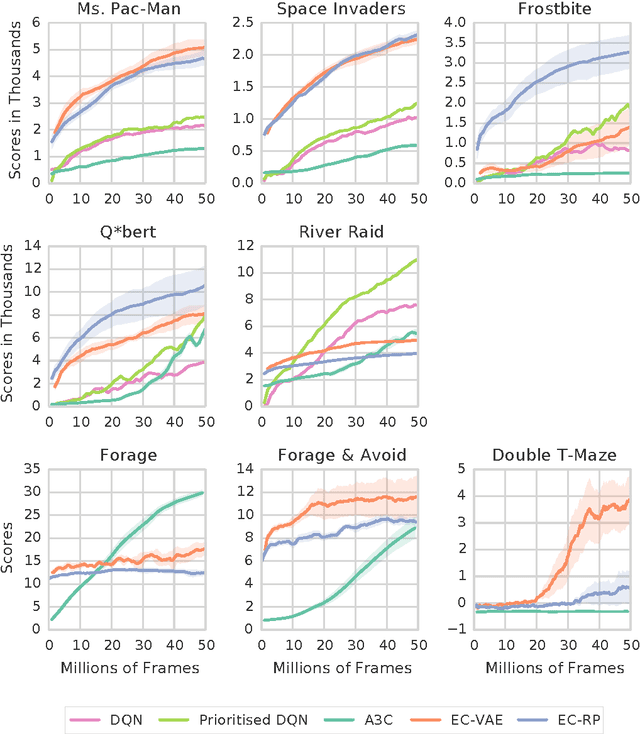

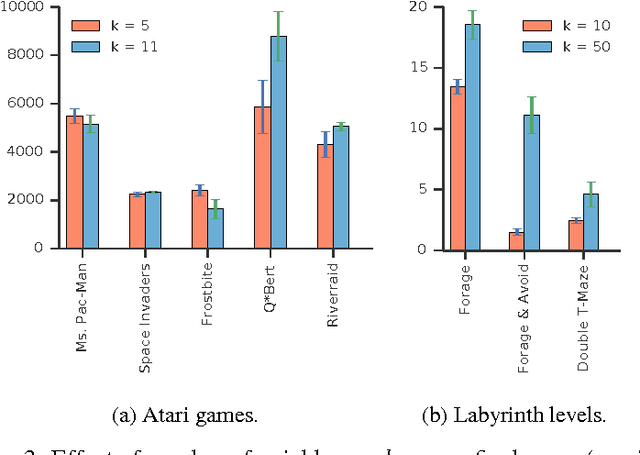
State of the art deep reinforcement learning algorithms take many millions of interactions to attain human-level performance. Humans, on the other hand, can very quickly exploit highly rewarding nuances of an environment upon first discovery. In the brain, such rapid learning is thought to depend on the hippocampus and its capacity for episodic memory. Here we investigate whether a simple model of hippocampal episodic control can learn to solve difficult sequential decision-making tasks. We demonstrate that it not only attains a highly rewarding strategy significantly faster than state-of-the-art deep reinforcement learning algorithms, but also achieves a higher overall reward on some of the more challenging domains.
Tighter Variational Representations of f-Divergences via Restriction to Probability Measures
Jun 18, 2012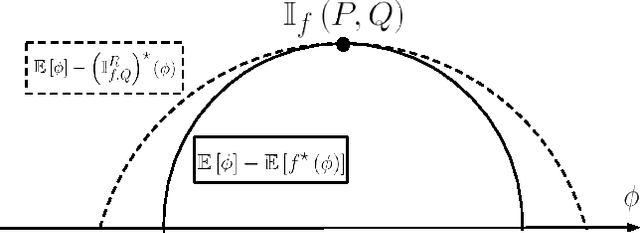
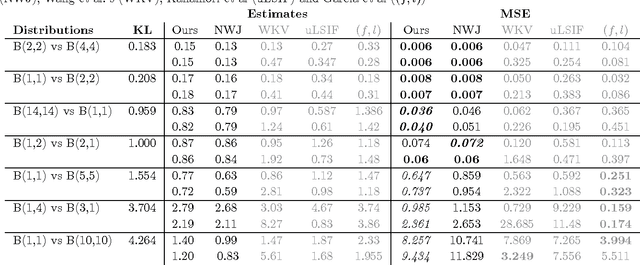
We show that the variational representations for f-divergences currently used in the literature can be tightened. This has implications to a number of methods recently proposed based on this representation. As an example application we use our tighter representation to derive a general f-divergence estimator based on two i.i.d. samples and derive the dual program for this estimator that performs well empirically. We also point out a connection between our estimator and MMD.