 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolipsistic Superintelligence is Unlikely to be Cooperative
Jun 02, 2026AI's central challenge is shifting from capability to coexistence. The dominant paradigm in AI research focuses on developing powerful agents that treat the world as an exogenous and stationary source of feedback. We contend that superintelligence, an extremely capable task solver, born out of such a solipsistic approach to AI design, is unlikely to be cooperative. Deploying AI systems induces endogenous non-stationarity, resulting in a train-test-deploy gap where historical distributions diverge from the deployment context. We refer to this as the self-undermining property of unilateral optimization. Closing this gap requires AI that participates in cooperation: the equilibrium-selection process through which multiple actors navigate their interdependence. We call for a non-solipsistic research paradigm that treats this interdependence as a core design principle rather than approaching cooperation as a task to solve. This entails building dynamic evaluation testbeds involving adaptive counterparties, treating institutions as design primitives, and preserving human agency as a structural feature of the systems we build.
Smooth markets: A basic mechanism for organizing gradient-based learners
Jan 18, 2020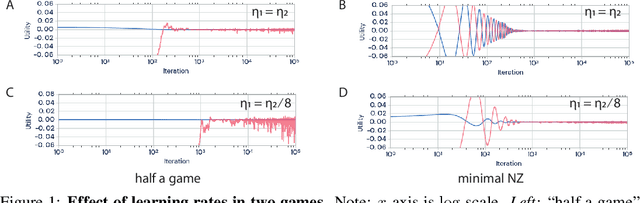
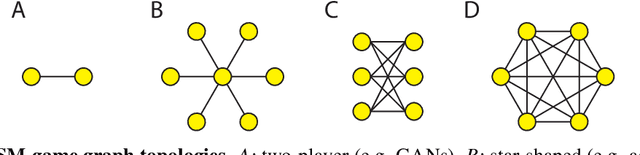
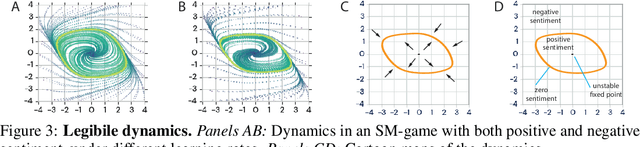
With the success of modern machine learning, it is becoming increasingly important to understand and control how learning algorithms interact. Unfortunately, negative results from game theory show there is little hope of understanding or controlling general n-player games. We therefore introduce smooth markets (SM-games), a class of n-player games with pairwise zero sum interactions. SM-games codify a common design pattern in machine learning that includes (some) GANs, adversarial training, and other recent algorithms. We show that SM-games are amenable to analysis and optimization using first-order methods.
* 18 pages, 3 figures
Generalization of Reinforcement Learners with Working and Episodic Memory
Oct 29, 2019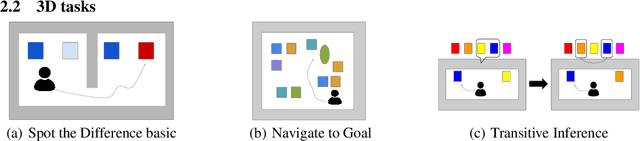
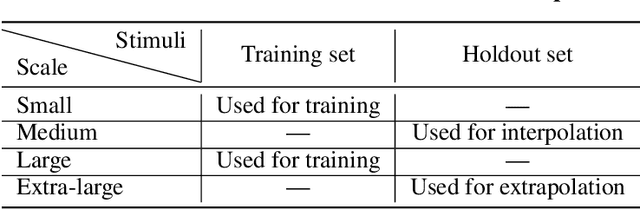
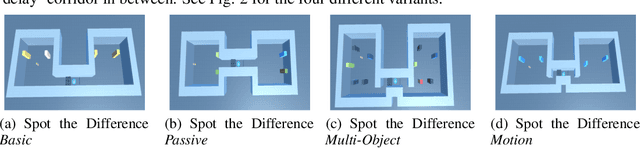
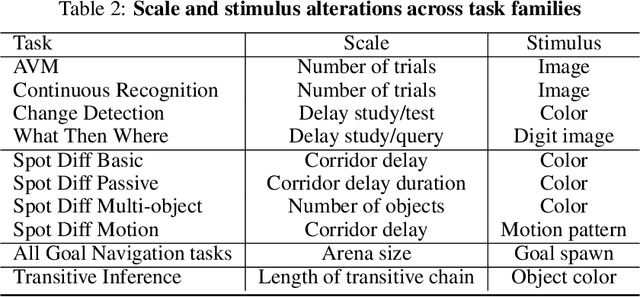
Memory is an important aspect of intelligence and plays a role in many deep reinforcement learning models. However, little progress has been made in understanding when specific memory systems help more than others and how well they generalize. The field also has yet to see a prevalent consistent and rigorous approach for evaluating agent performance on holdout data. In this paper, we aim to develop a comprehensive methodology to test different kinds of memory in an agent and assess how well the agent can apply what it learns in training to a holdout set that differs from the training set along dimensions that we suggest are relevant for evaluating memory-specific generalization. To that end, we first construct a diverse set of memory tasks that allow us to evaluate test-time generalization across multiple dimensions. Second, we develop and perform multiple ablations on an agent architecture that combines multiple memory systems, observe its baseline models, and investigate its performance against the task suite.
Emergent Communication through Negotiation
Apr 11, 2018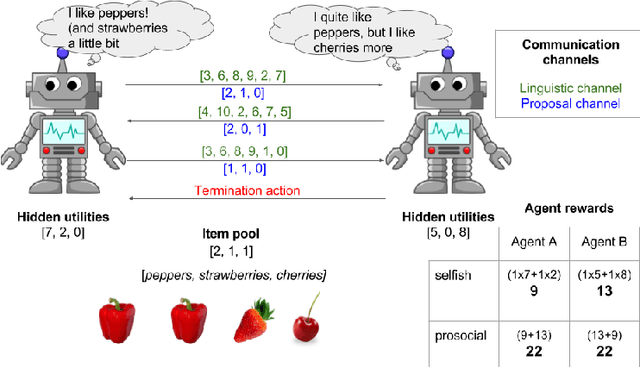
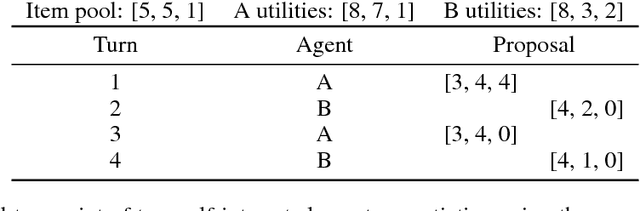
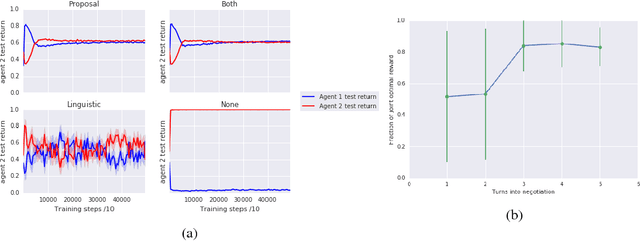
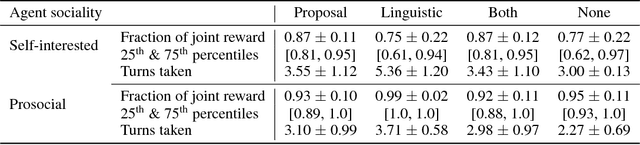
Multi-agent reinforcement learning offers a way to study how communication could emerge in communities of agents needing to solve specific problems. In this paper, we study the emergence of communication in the negotiation environment, a semi-cooperative model of agent interaction. We introduce two communication protocols -- one grounded in the semantics of the game, and one which is \textit{a priori} ungrounded and is a form of cheap talk. We show that self-interested agents can use the pre-grounded communication channel to negotiate fairly, but are unable to effectively use the ungrounded channel. However, prosocial agents do learn to use cheap talk to find an optimal negotiating strategy, suggesting that cooperation is necessary for language to emerge. We also study communication behaviour in a setting where one agent interacts with agents in a community with different levels of prosociality and show how agent identifiability can aid negotiation.
Learning to reinforcement learn
Jan 23, 2017
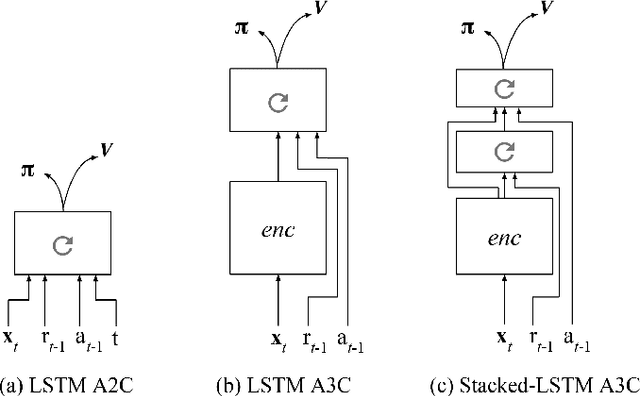
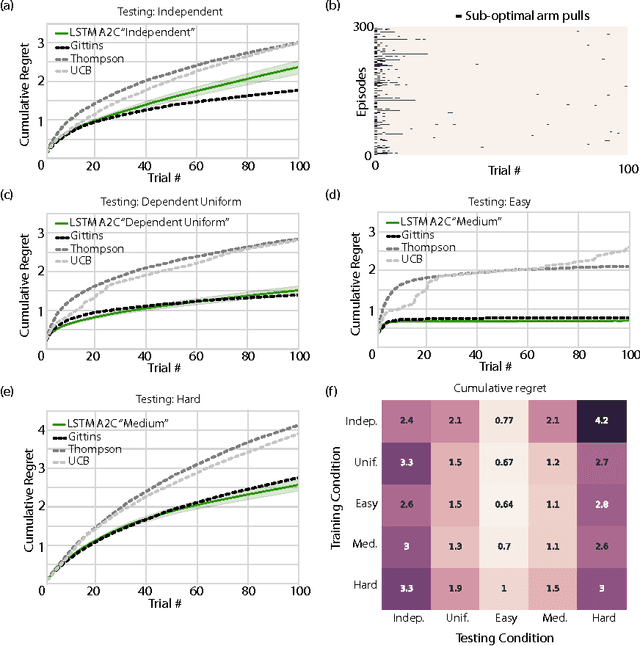
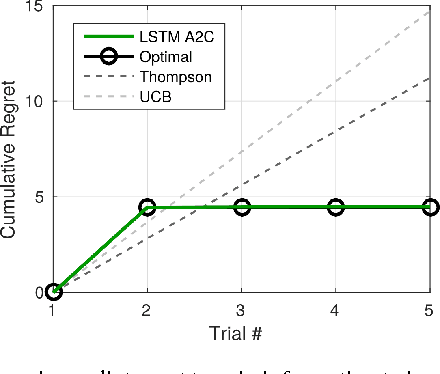
In recent years deep reinforcement learning (RL) systems have attained superhuman performance in a number of challenging task domains. However, a major limitation of such applications is their demand for massive amounts of training data. A critical present objective is thus to develop deep RL methods that can adapt rapidly to new tasks. In the present work we introduce a novel approach to this challenge, which we refer to as deep meta-reinforcement learning. Previous work has shown that recurrent networks can support meta-learning in a fully supervised context. We extend this approach to the RL setting. What emerges is a system that is trained using one RL algorithm, but whose recurrent dynamics implement a second, quite separate RL procedure. This second, learned RL algorithm can differ from the original one in arbitrary ways. Importantly, because it is learned, it is configured to exploit structure in the training domain. We unpack these points in a series of seven proof-of-concept experiments, each of which examines a key aspect of deep meta-RL. We consider prospects for extending and scaling up the approach, and also point out some potentially important implications for neuroscience.
Reinforcement Learning with Unsupervised Auxiliary Tasks
Nov 16, 2016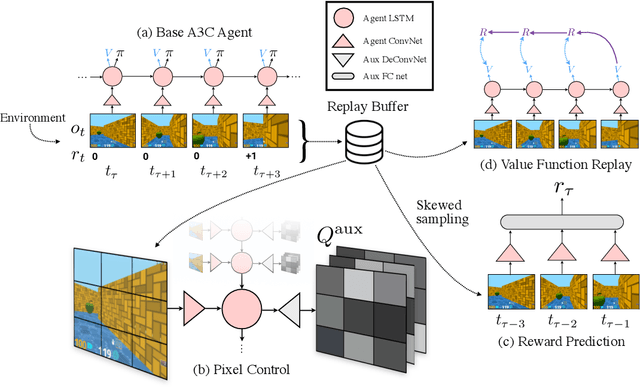
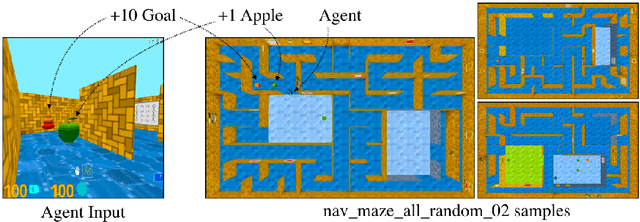
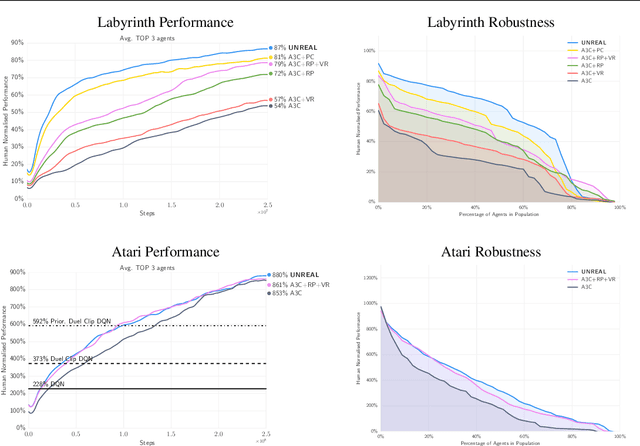
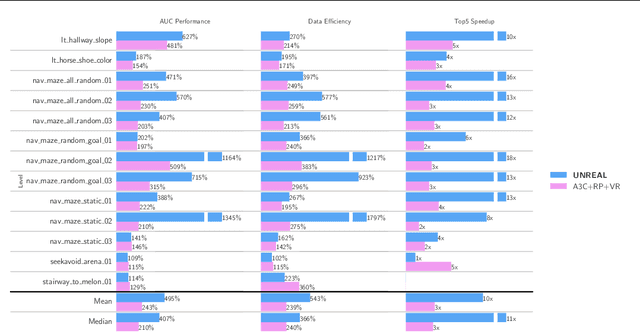
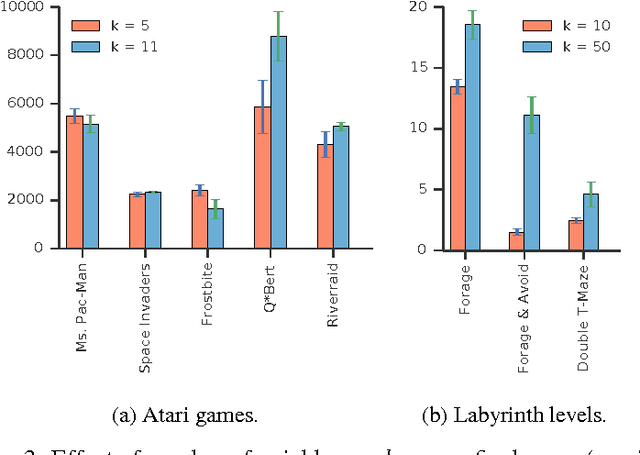
Deep reinforcement learning agents have achieved state-of-the-art results by directly maximising cumulative reward. However, environments contain a much wider variety of possible training signals. In this paper, we introduce an agent that also maximises many other pseudo-reward functions simultaneously by reinforcement learning. All of these tasks share a common representation that, like unsupervised learning, continues to develop in the absence of extrinsic rewards. We also introduce a novel mechanism for focusing this representation upon extrinsic rewards, so that learning can rapidly adapt to the most relevant aspects of the actual task. Our agent significantly outperforms the previous state-of-the-art on Atari, averaging 880\% expert human performance, and a challenging suite of first-person, three-dimensional \emph{Labyrinth} tasks leading to a mean speedup in learning of 10$\times$ and averaging 87\% expert human performance on Labyrinth.
Model-Free Episodic Control
Jun 14, 2016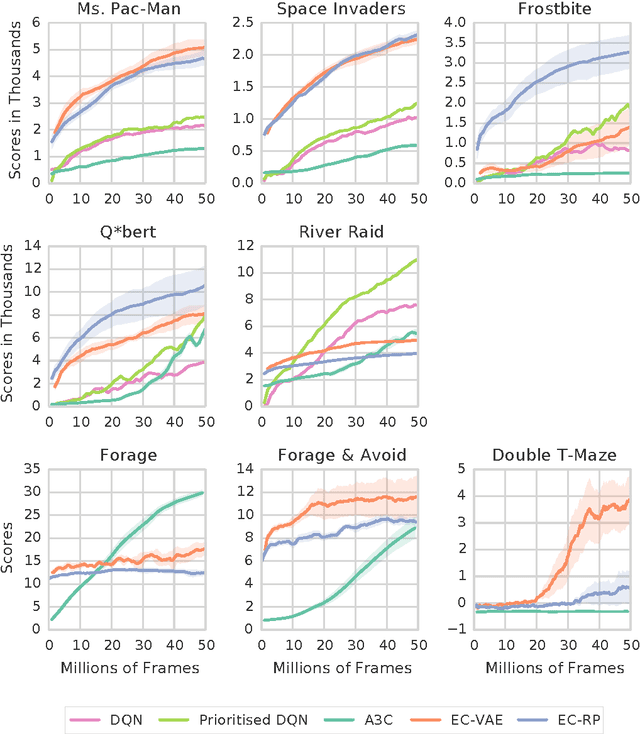

State of the art deep reinforcement learning algorithms take many millions of interactions to attain human-level performance. Humans, on the other hand, can very quickly exploit highly rewarding nuances of an environment upon first discovery. In the brain, such rapid learning is thought to depend on the hippocampus and its capacity for episodic memory. Here we investigate whether a simple model of hippocampal episodic control can learn to solve difficult sequential decision-making tasks. We demonstrate that it not only attains a highly rewarding strategy significantly faster than state-of-the-art deep reinforcement learning algorithms, but also achieves a higher overall reward on some of the more challenging domains.
Can a biologically-plausible hierarchy effectively replace face detection, alignment, and recognition pipelines?
Mar 26, 2014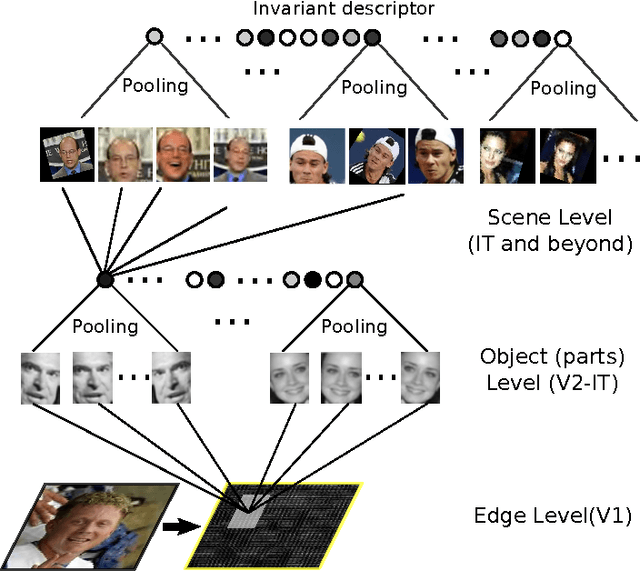
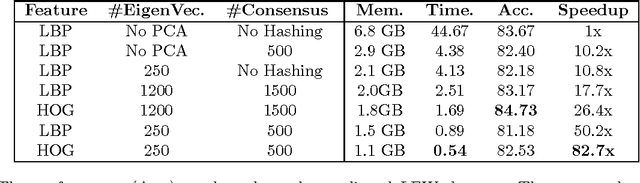
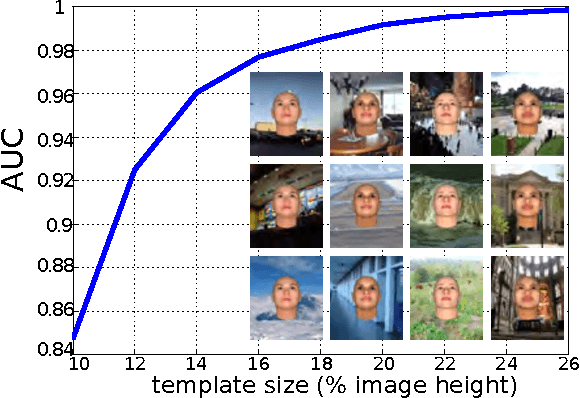
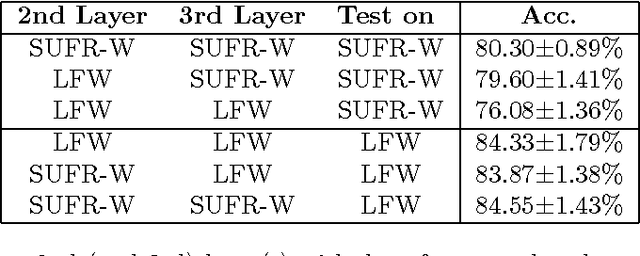
The standard approach to unconstrained face recognition in natural photographs is via a detection, alignment, recognition pipeline. While that approach has achieved impressive results, there are several reasons to be dissatisfied with it, among them is its lack of biological plausibility. A recent theory of invariant recognition by feedforward hierarchical networks, like HMAX, other convolutional networks, or possibly the ventral stream, implies an alternative approach to unconstrained face recognition. This approach accomplishes detection and alignment implicitly by storing transformations of training images (called templates) rather than explicitly detecting and aligning faces at test time. Here we propose a particular locality-sensitive hashing based voting scheme which we call "consensus of collisions" and show that it can be used to approximate the full 3-layer hierarchy implied by the theory. The resulting end-to-end system for unconstrained face recognition operates on photographs of faces taken under natural conditions, e.g., Labeled Faces in the Wild (LFW), without aligning or cropping them, as is normally done. It achieves a drastic improvement in the state of the art on this end-to-end task, reaching the same level of performance as the best systems operating on aligned, closely cropped images (no outside training data). It also performs well on two newer datasets, similar to LFW, but more difficult: LFW-jittered (new here) and SUFR-W.