 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan foundation models actively gather information in interactive environments to test hypotheses?
Dec 09, 2024



While problem solving is a standard evaluation task for foundation models, a crucial component of problem solving -- actively and strategically gathering information to test hypotheses -- has not been closely investigated. To assess the information gathering abilities of foundation models in interactive environments, we introduce a framework in which a model must determine the factors influencing a hidden reward function by iteratively reasoning about its previously gathered information and proposing its next exploratory action to maximize information gain at each step. We implement this framework in both a text-based environment, which offers a tightly controlled setting and enables high-throughput parameter sweeps, and in an embodied 3D environment, which requires addressing complexities of multi-modal interaction more relevant to real-world applications. We further investigate whether approaches such as self-correction and increased inference time improve information gathering efficiency. In a relatively simple task that requires identifying a single rewarding feature, we find that LLM's information gathering capability is close to optimal. However, when the model must identify a conjunction of rewarding features, performance is suboptimal. The hit in performance is due partly to the model translating task description to a policy and partly to the model's effectiveness in using its in-context memory. Performance is comparable in both text and 3D embodied environments, although imperfect visual object recognition reduces its accuracy in drawing conclusions from gathered information in the 3D embodied case. For single-feature-based rewards, we find that smaller models curiously perform better; for conjunction-based rewards, incorporating self correction into the model improves performance.
Passive learning of active causal strategies in agents and language models
May 25, 2023



What can be learned about causality and experimentation from passive data? This question is salient given recent successes of passively-trained language models in interactive domains such as tool use. Passive learning is inherently limited. However, we show that purely passive learning can in fact allow an agent to learn generalizable strategies for determining and using causal structures, as long as the agent can intervene at test time. We formally illustrate that learning a strategy of first experimenting, then seeking goals, can allow generalization from passive learning in principle. We then show empirically that agents trained via imitation on expert data can indeed generalize at test time to infer and use causal links which are never present in the training data; these agents can also generalize experimentation strategies to novel variable sets never observed in training. We then show that strategies for causal intervention and exploitation can be generalized from passive data even in a more complex environment with high-dimensional observations, with the support of natural language explanations. Explanations can even allow passive learners to generalize out-of-distribution from perfectly-confounded training data. Finally, we show that language models, trained only on passive next-word prediction, can generalize causal intervention strategies from a few-shot prompt containing examples of experimentation, together with explanations and reasoning. These results highlight the surprising power of passive learning of active causal strategies, and may help to understand the behaviors and capabilities of language models.
Learning to reinforcement learn
Jan 23, 2017
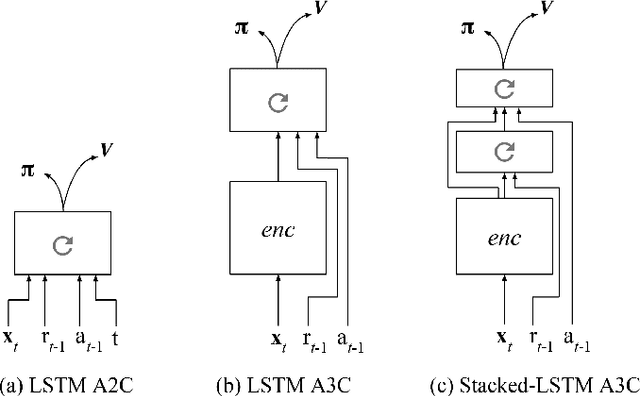
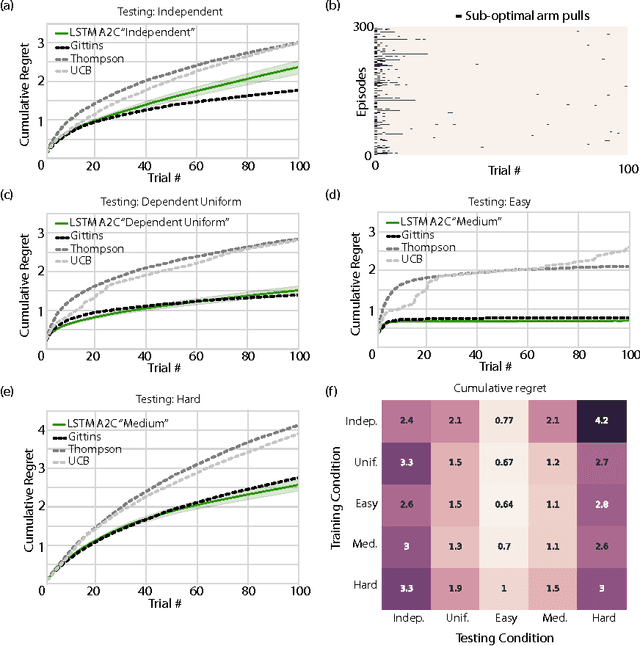
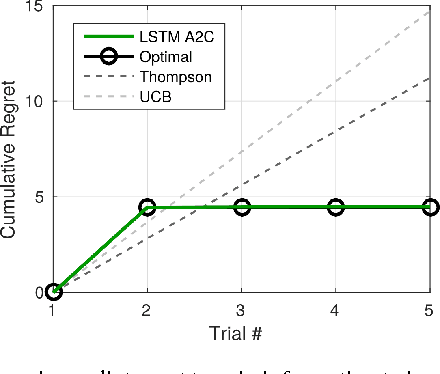
In recent years deep reinforcement learning (RL) systems have attained superhuman performance in a number of challenging task domains. However, a major limitation of such applications is their demand for massive amounts of training data. A critical present objective is thus to develop deep RL methods that can adapt rapidly to new tasks. In the present work we introduce a novel approach to this challenge, which we refer to as deep meta-reinforcement learning. Previous work has shown that recurrent networks can support meta-learning in a fully supervised context. We extend this approach to the RL setting. What emerges is a system that is trained using one RL algorithm, but whose recurrent dynamics implement a second, quite separate RL procedure. This second, learned RL algorithm can differ from the original one in arbitrary ways. Importantly, because it is learned, it is configured to exploit structure in the training domain. We unpack these points in a series of seven proof-of-concept experiments, each of which examines a key aspect of deep meta-RL. We consider prospects for extending and scaling up the approach, and also point out some potentially important implications for neuroscience.