 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning model-based strategies in simple environments with hierarchical q-networks
Paper and Code
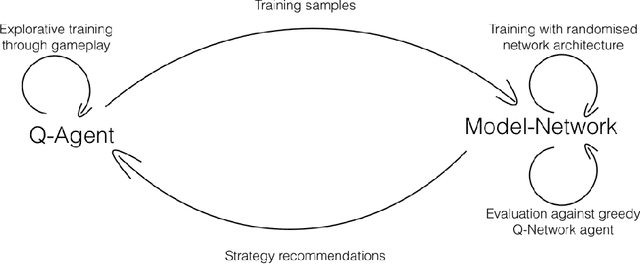
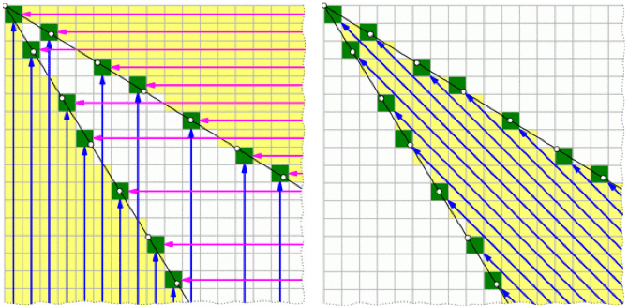


Recent advances in deep learning have allowed artificial agents to rival human-level performance on a wide range of complex tasks; however, the ability of these networks to learn generalizable strategies remains a pressing challenge. This critical limitation is due in part to two factors: the opaque information representation in deep neural networks and the complexity of the task environments in which they are typically deployed. Here we propose a novel Hierarchical Q-Network (HQN) motivated by theories of the hierarchical organization of the human prefrontal cortex, that attempts to identify lower dimensional patterns in the value landscape that can be exploited to construct an internal model of rules in simple environments. We draw on combinatorial games, where there exists a single optimal strategy for winning that generalizes across other features of the game, to probe the strategy generalization of the HQN and other reinforcement learning (RL) agents using variations of Wythoff's game. Traditional RL approaches failed to reach satisfactory performance on variants of Wythoff's Game; however, the HQN learned heuristic-like strategies that generalized across changes in board configuration. More importantly, the HQN allowed for transparent inspection of the agent's internal model of the game following training. Our results show how a biologically inspired hierarchical learner can facilitate learning abstract rules to promote robust and flexible action policies in simplified training environments with clearly delineated optimal strategies.