 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeep it stupid simple
Paper and Code
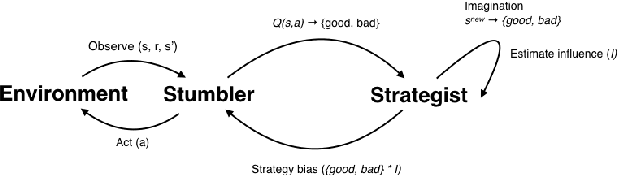

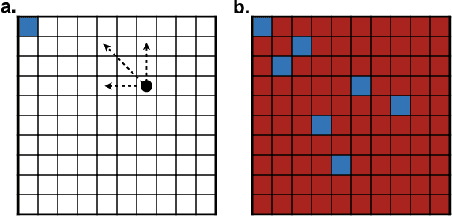
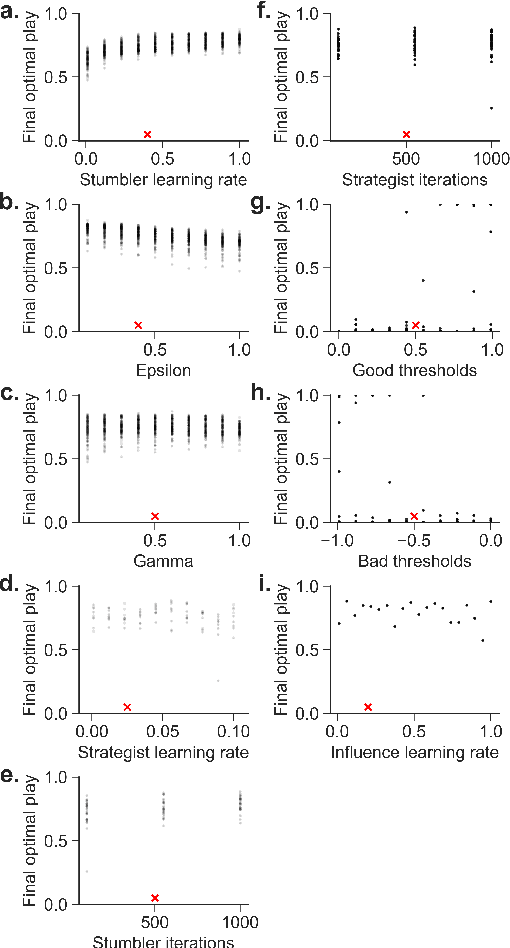
Deep reinforcement learning can match and exceed human performance, but if even minor changes are introduced to the environment artificial networks often can't adapt. Humans meanwhile are quite adaptable. We hypothesize that this is partly because of how humans use heuristics, and partly because humans can imagine new and more challenging environments to learn from. We've developed a model of hierarchical reinforcement learning that combines both these elements into a stumbler-strategist network. We test transfer performance of this network using Wythoff's game, a gridworld environment with a known optimal strategy. We show that combining imagined play with a heuristic--labeling each position as "good" or "bad"'--both accelerates learning and promotes transfer to novel games, while also improving model interpretability.