 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompiling to recurrent neurons
Nov 18, 2025Discrete structures are currently second-class in differentiable programming. Since functions over discrete structures lack overt derivatives, differentiable programs do not differentiate through them and limit where they can be used. For example, when programming a neural network, conditionals and iteration cannot be used everywhere; they can break the derivatives necessary for gradient-based learning to work. This limits the class of differentiable algorithms we can directly express, imposing restraints on how we build neural networks and differentiable programs more generally. However, these restraints are not fundamental. Recent work shows conditionals can be first-class, by compiling them into differentiable form as linear neurons. Similarly, this work shows iteration can be first-class -- by compiling to linear recurrent neurons. We present a minimal typed, higher-order and linear programming language with iteration called $\textsf{Cajal}\scriptstyle(\mathbb{\multimap}, \mathbb{2}, \mathbb{N})$. We prove its programs compile correctly to recurrent neurons, allowing discrete algorithms to be expressed in a differentiable form compatible with gradient-based learning. With our implementation, we conduct two experiments where we link these recurrent neurons against a neural network solving an iterative image transformation task. This determines part of its function prior to learning. As a result, the network learns faster and with greater data-efficiency relative to a neural network programmed without first-class iteration. A key lesson is that recurrent neurons enable a rich interplay between learning and the discrete structures of ordinary programming.
Compiling to linear neurons
Nov 14, 2025We don't program neural networks directly. Instead, we rely on an indirect style where learning algorithms, like gradient descent, determine a neural network's function by learning from data. This indirect style is often a virtue; it empowers us to solve problems that were previously impossible. But it lacks discrete structure. We can't compile most algorithms into a neural network -- even if these algorithms could help the network learn. This limitation occurs because discrete algorithms are not obviously differentiable, making them incompatible with the gradient-based learning algorithms that determine a neural network's function. To address this, we introduce $\textsf{Cajal}$: a typed, higher-order and linear programming language intended to be a minimal vehicle for exploring a direct style of programming neural networks. We prove $\textsf{Cajal}$ programs compile to linear neurons, allowing discrete algorithms to be expressed in a differentiable form compatible with gradient-based learning. With our implementation of $\textsf{Cajal}$, we conduct several experiments where we link these linear neurons against other neural networks to determine part of their function prior to learning. Linking with these neurons allows networks to learn faster, with greater data-efficiency, and in a way that's easier to debug. A key lesson is that linear programming languages provide a path towards directly programming neural networks, enabling a rich interplay between learning and the discrete structures of ordinary programming.
Falcon: Fractional Alternating Cut with Overcoming Minima in Unsupervised Segmentation
Apr 08, 2025Today's unsupervised image segmentation algorithms often segment suboptimally. Modern graph-cut based approaches rely on high-dimensional attention maps from Transformer-based foundation models, typically employing a relaxed Normalized Cut solved recursively via the Fiedler vector (the eigenvector of the second smallest eigenvalue). Consequently, they still lag behind supervised methods in both mask generation speed and segmentation accuracy. We present a regularized fractional alternating cut (Falcon), an optimization-based K-way Normalized Cut without relying on recursive eigenvector computations, achieving substantially improved speed and accuracy. Falcon operates in two stages: (1) a fast K-way Normalized Cut solved by extending into a fractional quadratic transformation, with an alternating iterative procedure and regularization to avoid local minima; and (2) refinement of the resulting masks using complementary low-level information, producing high-quality pixel-level segmentations. Experiments show that Falcon not only surpasses existing state-of-the-art methods by an average of 2.5% across six widely recognized benchmarks (reaching up to 4.3\% improvement on Cityscapes), but also reduces runtime by around 30% compared to prior graph-based approaches. These findings demonstrate that the semantic information within foundation-model attention can be effectively harnessed by a highly parallelizable graph cut framework. Consequently, Falcon can narrow the gap between unsupervised and supervised segmentation, enhancing scalability in real-world applications and paving the way for dense prediction-based vision pre-training in various downstream tasks. The code is released in https://github.com/KordingLab/Falcon.
Vision-language models for decoding provider attention during neonatal resuscitation
Apr 01, 2024Neonatal resuscitations demand an exceptional level of attentiveness from providers, who must process multiple streams of information simultaneously. Gaze strongly influences decision making; thus, understanding where a provider is looking during neonatal resuscitations could inform provider training, enhance real-time decision support, and improve the design of delivery rooms and neonatal intensive care units (NICUs). Current approaches to quantifying neonatal providers' gaze rely on manual coding or simulations, which limit scalability and utility. Here, we introduce an automated, real-time, deep learning approach capable of decoding provider gaze into semantic classes directly from first-person point-of-view videos recorded during live resuscitations. Combining state-of-the-art, real-time segmentation with vision-language models (CLIP), our low-shot pipeline attains 91\% classification accuracy in identifying gaze targets without training. Upon fine-tuning, the performance of our gaze-guided vision transformer exceeds 98\% accuracy in gaze classification, approaching human-level precision. This system, capable of real-time inference, enables objective quantification of provider attention dynamics during live neonatal resuscitation. Our approach offers a scalable solution that seamlessly integrates with existing infrastructure for data-scarce gaze analysis, thereby offering new opportunities for understanding and refining clinical decision making.
Meta-learning Causal Discovery
Sep 12, 2022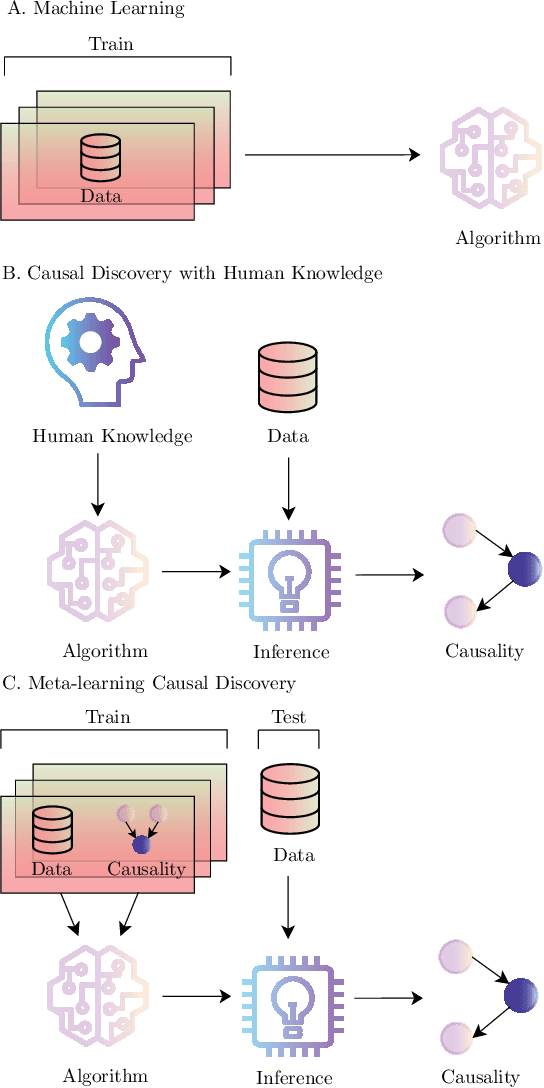
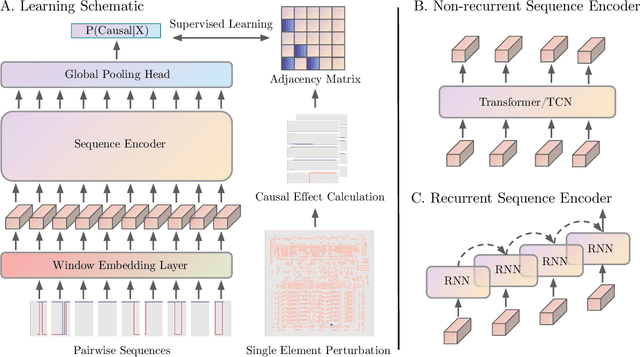
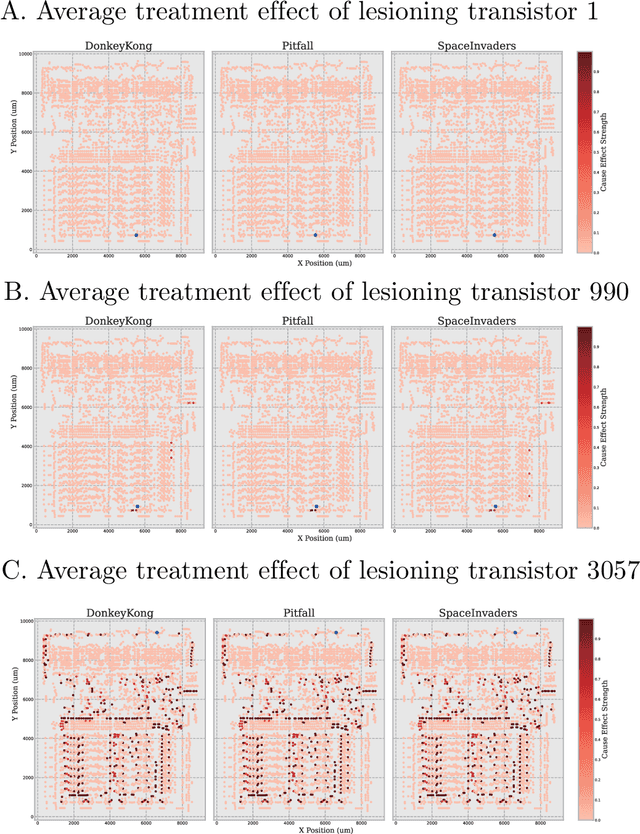
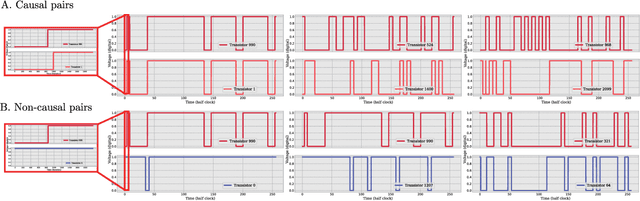
Causal discovery (CD) from time-varying data is important in neuroscience, medicine, and machine learning. Techniques for CD include randomized experiments which are generally unbiased but expensive. It also includes algorithms like regression, matching, and Granger causality, which are only correct under strong assumptions made by human designers. However, as we found in other areas of machine learning, humans are usually not quite right and are usually outperformed by data-driven approaches. Here we test if we can improve causal discovery in a data-driven way. We take a system with a large number of causal components (transistors), the MOS 6502 processor, and meta-learn the causal discovery procedure represented as a neural network. We find that this procedure far outperforms human-designed causal discovery procedures, such as Mutual Information and Granger Causality. We argue that the causality field should consider, where possible, a supervised approach, where CD procedures are learned from large datasets with known causal relations instead of being designed by a human specialist. Our findings promise a new approach toward CD in neural and medical data and for the broader machine learning community.
A critical reappraisal of predicting suicidal ideation using fMRI
Mar 10, 2021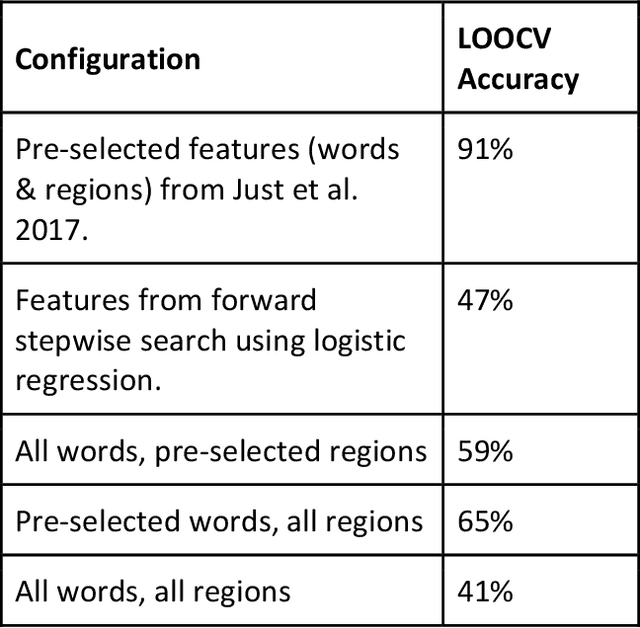
For many psychiatric disorders, neuroimaging offers a potential for revolutionizing diagnosis and treatment by providing access to preverbal mental processes. In their study "Machine learning of neural representations of suicide and emotion concepts identifies suicidal youth."1, Just and colleagues report that a Naive Bayes classifier, trained on voxelwise fMRI responses in human participants during the presentation of words and concepts related to mortality, can predict whether an individual had reported having suicidal ideations with a classification accuracy of 91%. Here we report a reappraisal of the methods employed by the authors, including re-analysis of the same data set, that calls into question the accuracy of the authors findings.
MoVi: A Large Multipurpose Motion and Video Dataset
Mar 04, 2020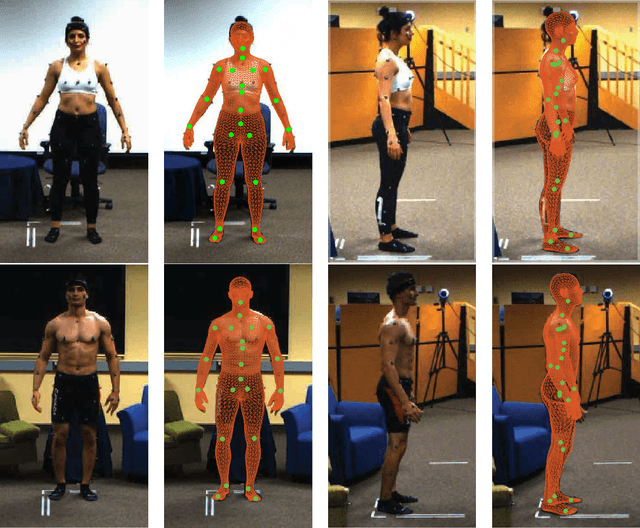
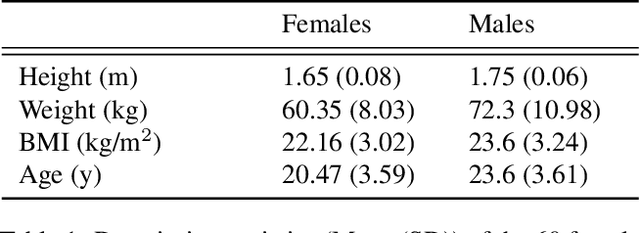
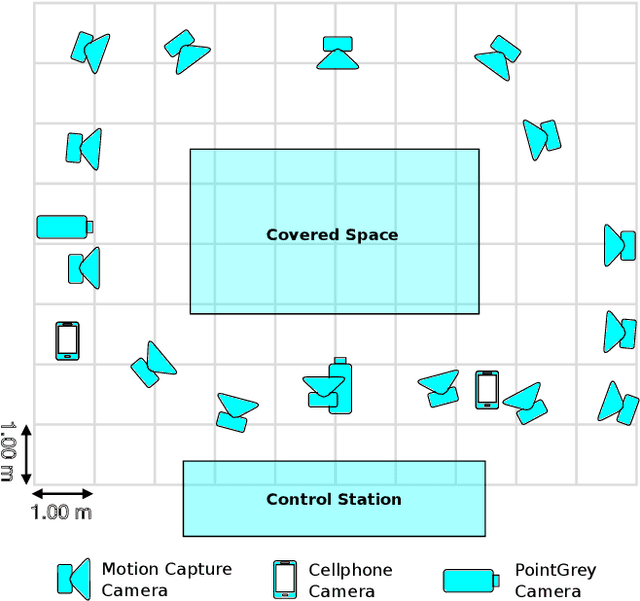
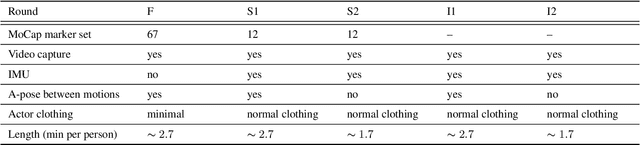
Human movements are both an area of intense study and the basis of many applications such as character animation. For many applications, it is crucial to identify movements from videos or analyze datasets of movements. Here we introduce a new human Motion and Video dataset MoVi, which we make available publicly. It contains 60 female and 30 male actors performing a collection of 20 predefined everyday actions and sports movements, and one self-chosen movement. In five capture rounds, the same actors and movements were recorded using different hardware systems, including an optical motion capture system, video cameras, and inertial measurement units (IMU). For some of the capture rounds, the actors were recorded when wearing natural clothing, for the other rounds they wore minimal clothing. In total, our dataset contains 9 hours of motion capture data, 17 hours of video data from 4 different points of view (including one hand-held camera), and 6.6 hours of IMU data. In this paper, we describe how the dataset was collected and post-processed; We present state-of-the-art estimates of skeletal motions and full-body shape deformations associated with skeletal motion. We discuss examples for potential studies this dataset could enable.
End-to-end Training of CNN-CRF via Differentiable Dual-Decomposition
Dec 06, 2019
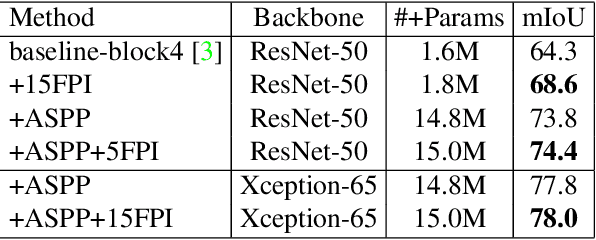

Modern computer vision (CV) is often based on convolutional neural networks (CNNs) that excel at hierarchical feature extraction. The previous generation of CV approaches was often based on conditional random fields (CRFs) that excel at modeling flexible higher order interactions. As their benefits are complementary they are often combined. However, these approaches generally use mean-field approximations and thus, arguably, did not directly optimize the real problem. Here we revisit dual-decomposition-based approaches to CRF optimization, an alternative to the mean-field approximation. These algorithms can efficiently and exactly solve sub-problems and directly optimize a convex upper bound of the real problem, providing optimality certificates on the way. Our approach uses a novel fixed-point iteration algorithm which enjoys dual-monotonicity, dual-differentiability and high parallelism. The whole system, CRF and CNN can thus be efficiently trained using back-propagation. We demonstrate the effectiveness of our system on semantic image segmentation, showing consistent improvement over baseline models.
Claim Extraction in Biomedical Publications using Deep Discourse Model and Transfer Learning
Jul 01, 2019
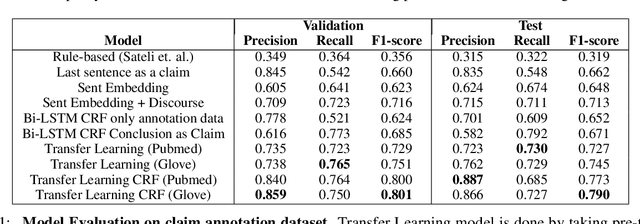
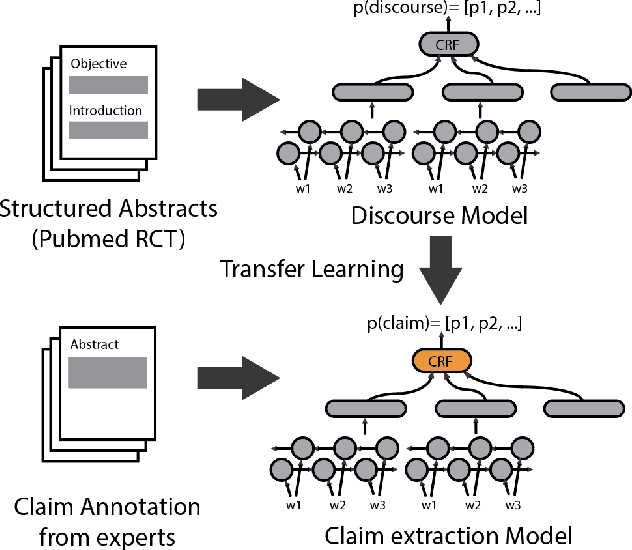
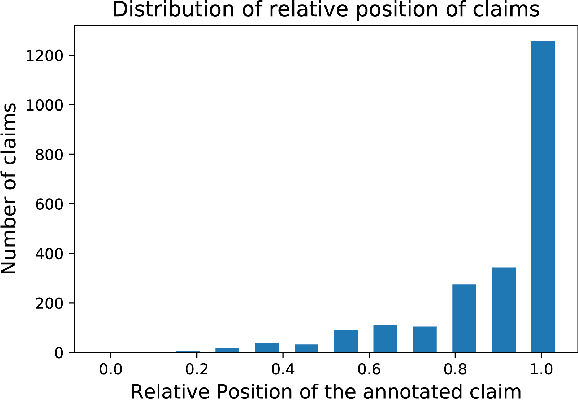
Claims are a fundamental unit of scientific discourse. The exponential growth in the number of scientific publications makes automatic claim extraction an important problem for researchers who are overwhelmed by this information overload. Such an automated claim extraction system is useful for both manual and programmatic exploration of scientific knowledge. In this paper, we introduce an online claim extraction system and a dataset of 1,500 scientific abstracts from the biomedical domain with expert annotations for each sentence indicating whether the sentence presents a scientific claim. We compare our proposed model with several baseline models including rule-based and deep learning techniques. Our transfer learning approach with a fine-tuning step allows us to bootstrap from a large discourse-annotated dataset (Pubmed-RCT) and obtains F1-score over 0.78 for claim detection while using a small annotated dataset of 750 papers. We show that using this pre-trained model based on the discourse prediction task improves F1-score by over 14 percent absolute points compared to a baseline model without discourse structure. We release a publicly accessible tool for discourse model, claim detection model, along with an annotation tool. We discuss further applications beyond Biomedical literature.
Rarely-switching linear bandits: optimization of causal effects for the real world
May 30, 2019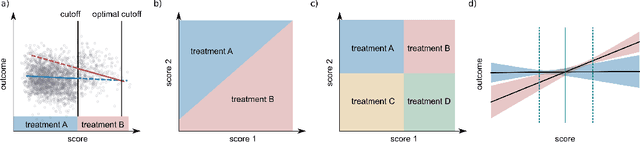
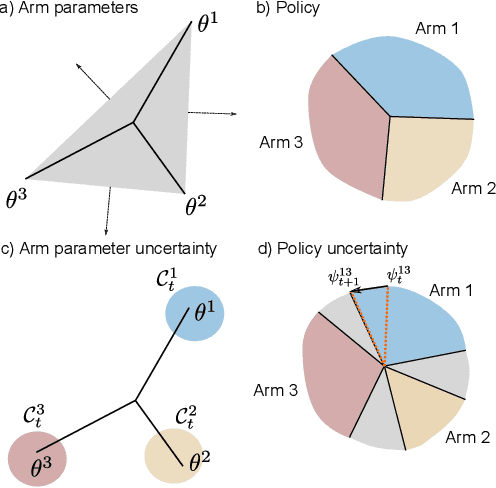
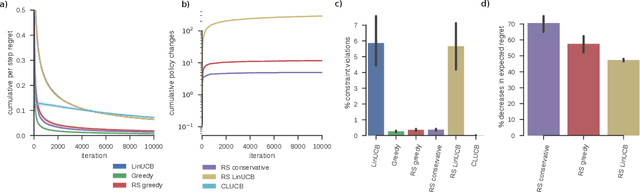
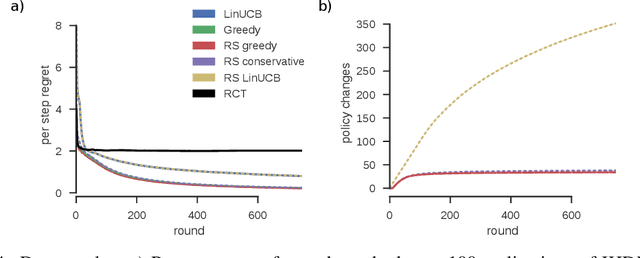
Exploring the effect of policies in many real world scenarios is difficult, unethical, or expensive. After all, doctor guidelines, tax codes, and price lists can only be reprinted so often. We may thus want to only change a policy when it is probable that the change is beneficial. Fortunately, thresholds allow us to estimate treatment effects. Such estimates allows us to optimize the threshold. Here, based on the theory of linear contextual bandits, we present a conservative policy updating procedure which updates a deterministic policy only when needed. We extend the theory of linear bandits to this rarely-switching case, proving such procedures share the same regret, up to constant scaling, as the common LinUCB algorithm. However the algorithm makes far fewer changes to its policy. We provide simulations and an analysis of an infant health well-being causal inference dataset, showing the algorithm efficiently learns a good policy with few changes. Our approach allows efficiently solving problems where changes are to be avoided, with potential applications in economics, medicine and beyond.