 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Supervised Learning by Meta-learning Unsupervised Local Rules
Mar 17, 2021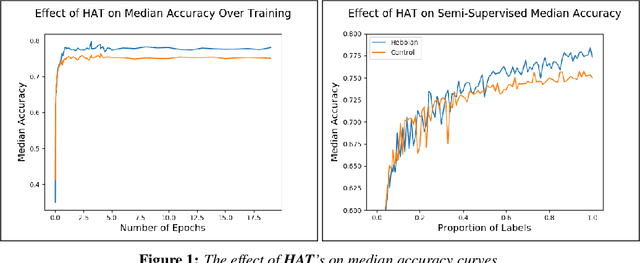
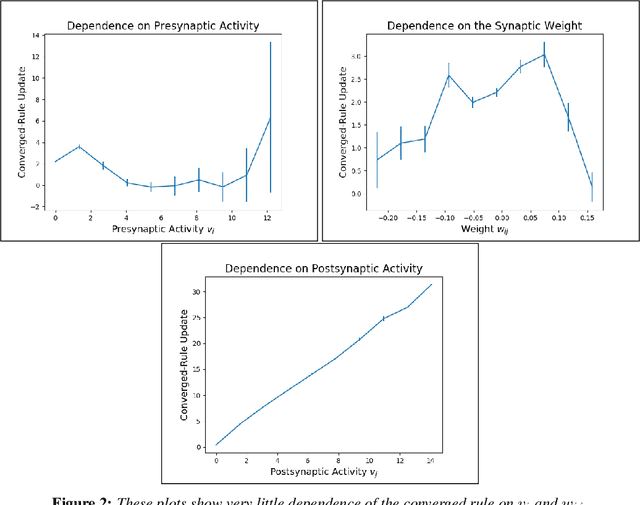
The brain performs unsupervised learning and (perhaps) simultaneous supervised learning. This raises the question as to whether a hybrid of supervised and unsupervised methods will produce better learning. Inspired by the rich space of Hebbian learning rules, we set out to directly learn the unsupervised learning rule on local information that best augments a supervised signal. We present the Hebbian-augmented training algorithm (HAT) for combining gradient-based learning with an unsupervised rule on pre-synpatic activity, post-synaptic activities, and current weights. We test HAT's effect on a simple problem (Fashion-MNIST) and find consistently higher performance than supervised learning alone. This finding provides empirical evidence that unsupervised learning on synaptic activities provides a strong signal that can be used to augment gradient-based methods. We further find that the meta-learned update rule is a time-varying function; thus, it is difficult to pinpoint an interpretable Hebbian update rule that aids in training. We do find that the meta-learner eventually degenerates into a non-Hebbian rule that preserves important weights so as not to disturb the learner's convergence.
Towards intervention-centric causal reasoning in learning agents
May 26, 2020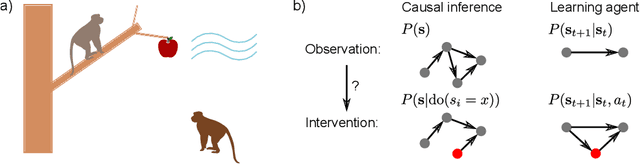

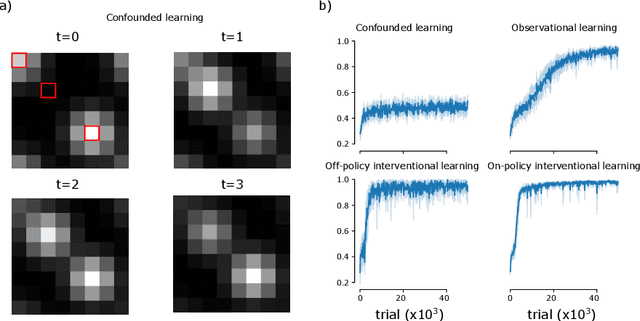

Interventions are central to causal learning and reasoning. Yet ultimately an intervention is an abstraction: an agent embedded in a physical environment (perhaps modeled as a Markov decision process) does not typically come equipped with the notion of an intervention -- its action space is typically ego-centric, without actions of the form `intervene on X'. Such a correspondence between ego-centric actions and interventions would be challenging to hard-code. It would instead be better if an agent learnt which sequence of actions allow it to make targeted manipulations of the environment, and learnt corresponding representations that permitted learning from observation. Here we show how a meta-learning approach can be used to perform causal learning in this challenging setting, where the action-space is not a set of interventions and the observation space is a high-dimensional space with a latent causal structure. A meta-reinforcement learning algorithm is used to learn relationships that transfer on observational causal learning tasks. This work shows how advances in deep reinforcement learning and meta-learning can provide intervention-centric causal learning in high-dimensional environments with a latent causal structure.
Rarely-switching linear bandits: optimization of causal effects for the real world
May 30, 2019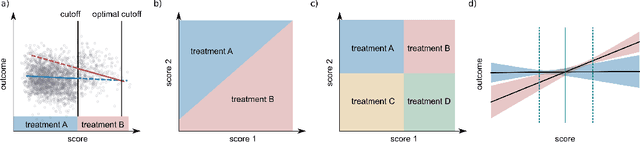
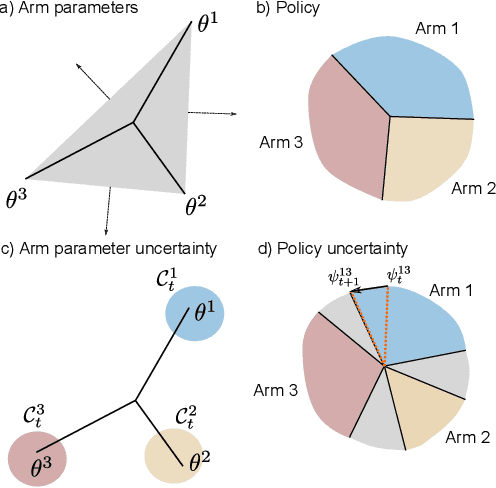
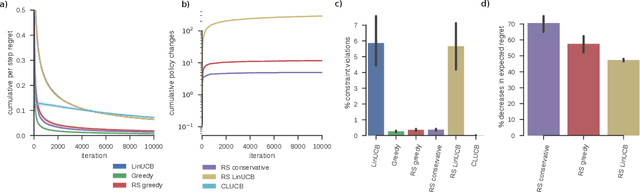
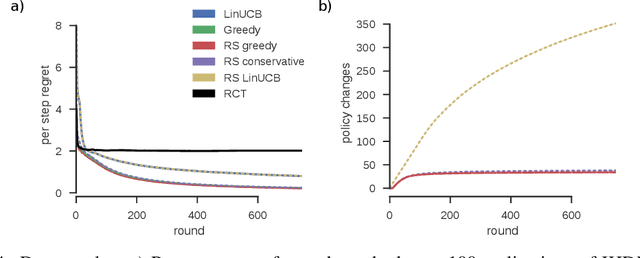
Exploring the effect of policies in many real world scenarios is difficult, unethical, or expensive. After all, doctor guidelines, tax codes, and price lists can only be reprinted so often. We may thus want to only change a policy when it is probable that the change is beneficial. Fortunately, thresholds allow us to estimate treatment effects. Such estimates allows us to optimize the threshold. Here, based on the theory of linear contextual bandits, we present a conservative policy updating procedure which updates a deterministic policy only when needed. We extend the theory of linear bandits to this rarely-switching case, proving such procedures share the same regret, up to constant scaling, as the common LinUCB algorithm. However the algorithm makes far fewer changes to its policy. We provide simulations and an analysis of an infant health well-being causal inference dataset, showing the algorithm efficiently learns a good policy with few changes. Our approach allows efficiently solving problems where changes are to be avoided, with potential applications in economics, medicine and beyond.