 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpolating between sampling and variational inference with infinite stochastic mixtures
Oct 18, 2021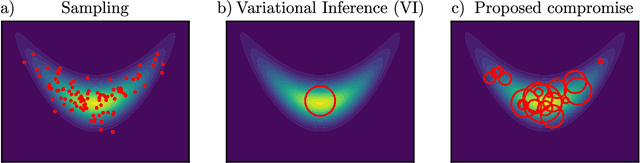
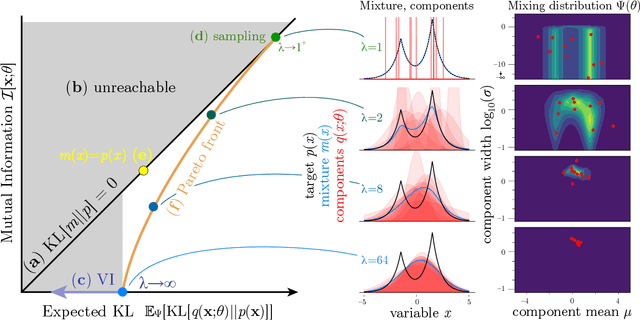
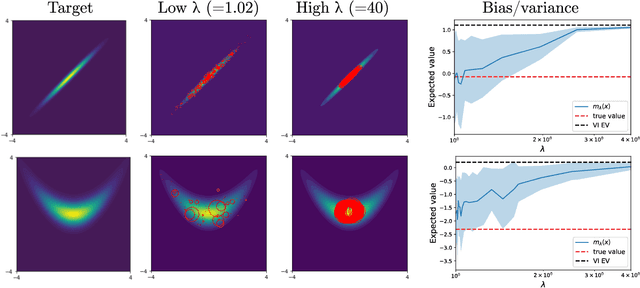
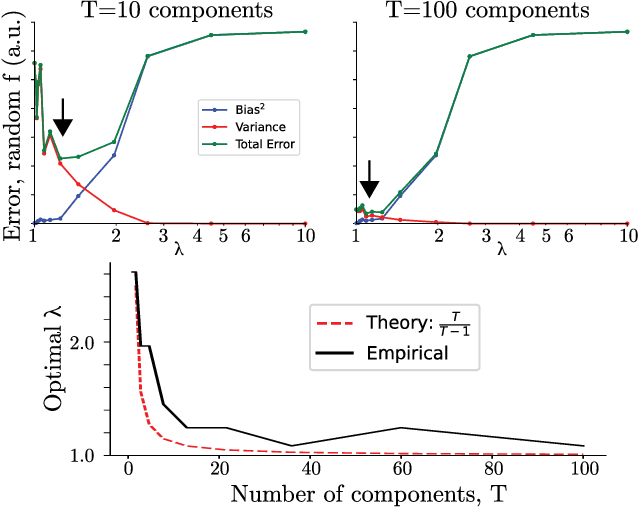
Sampling and Variational Inference (VI) are two large families of methods for approximate inference with complementary strengths. Sampling methods excel at approximating arbitrary probability distributions, but can be inefficient. VI methods are efficient, but can fail when probability distributions are complex. Here, we develop a framework for constructing intermediate algorithms that balance the strengths of both sampling and VI. Both approximate a probability distribution using a mixture of simple component distributions: in sampling, each component is a delta-function and is chosen stochastically, while in standard VI a single component is chosen to minimize divergence. We show that sampling and VI emerge as special cases of an optimization problem over a mixing distribution, and intermediate approximations arise by varying a single parameter. We then derive closed-form sampling dynamics over variational parameters that stochastically build a mixture. Finally, we discuss how to select the optimal compromise between sampling and VI given a computational budget. This work is a first step towards a highly flexible yet simple family of inference methods that combines the complementary strengths of sampling and VI.
Augmenting Supervised Learning by Meta-learning Unsupervised Local Rules
Mar 17, 2021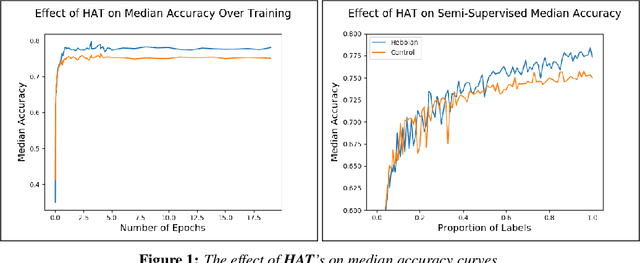
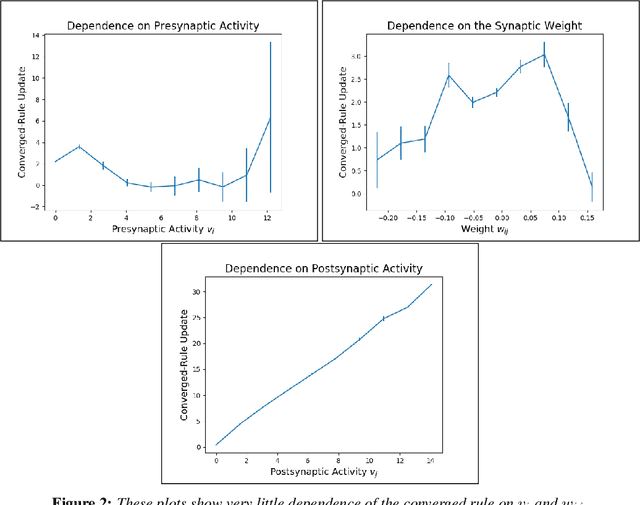
The brain performs unsupervised learning and (perhaps) simultaneous supervised learning. This raises the question as to whether a hybrid of supervised and unsupervised methods will produce better learning. Inspired by the rich space of Hebbian learning rules, we set out to directly learn the unsupervised learning rule on local information that best augments a supervised signal. We present the Hebbian-augmented training algorithm (HAT) for combining gradient-based learning with an unsupervised rule on pre-synpatic activity, post-synaptic activities, and current weights. We test HAT's effect on a simple problem (Fashion-MNIST) and find consistently higher performance than supervised learning alone. This finding provides empirical evidence that unsupervised learning on synaptic activities provides a strong signal that can be used to augment gradient-based methods. We further find that the meta-learned update rule is a time-varying function; thus, it is difficult to pinpoint an interpretable Hebbian update rule that aids in training. We do find that the meta-learner eventually degenerates into a non-Hebbian rule that preserves important weights so as not to disturb the learner's convergence.