 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAIMCHECK: How Grounded are LLM Critiques of Scientific Papers?
Mar 27, 2025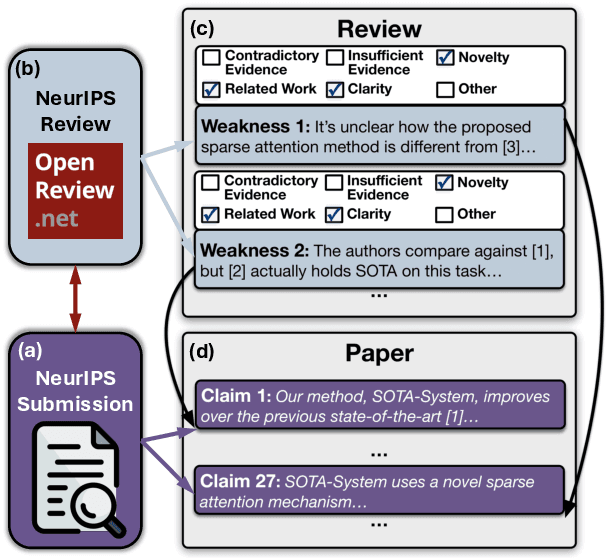
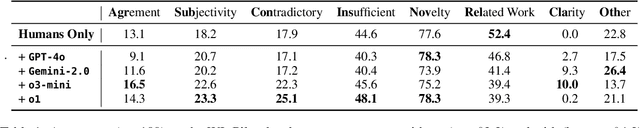
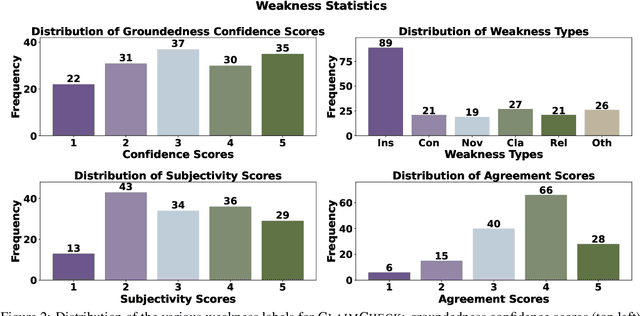
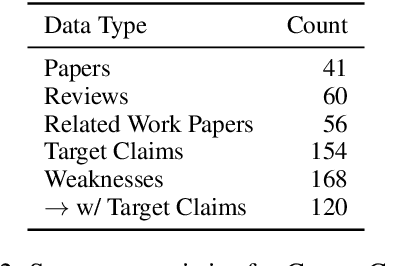
A core part of scientific peer review involves providing expert critiques that directly assess the scientific claims a paper makes. While it is now possible to automatically generate plausible (if generic) reviews, ensuring that these reviews are sound and grounded in the papers' claims remains challenging. To facilitate LLM benchmarking on these challenges, we introduce CLAIMCHECK, an annotated dataset of NeurIPS 2023 and 2024 submissions and reviews mined from OpenReview. CLAIMCHECK is richly annotated by ML experts for weakness statements in the reviews and the paper claims that they dispute, as well as fine-grained labels of the validity, objectivity, and type of the identified weaknesses. We benchmark several LLMs on three claim-centric tasks supported by CLAIMCHECK, requiring models to (1) associate weaknesses with the claims they dispute, (2) predict fine-grained labels for weaknesses and rewrite the weaknesses to enhance their specificity, and (3) verify a paper's claims with grounded reasoning. Our experiments reveal that cutting-edge LLMs, while capable of predicting weakness labels in (2), continue to underperform relative to human experts on all other tasks.
Is That Your Final Answer? Test-Time Scaling Improves Selective Question Answering
Feb 19, 2025Scaling the test-time compute of large language models has demonstrated impressive performance on reasoning benchmarks. However, existing evaluations of test-time scaling make the strong assumption that a reasoning system should always give an answer to any question provided. This overlooks concerns about whether a model is confident in its answer, and whether it is appropriate to always provide a response. To address these concerns, we extract confidence scores during reasoning for thresholding model responses. We find that increasing compute budget at inference time not only helps models answer more questions correctly, but also increases confidence in correct responses. We then extend the current paradigm of zero-risk responses during evaluation by considering settings with non-zero levels of response risk, and suggest a recipe for reporting evaluations under these settings.
Compressed Chain of Thought: Efficient Reasoning Through Dense Representations
Dec 17, 2024



Chain-of-thought (CoT) decoding enables language models to improve reasoning performance at the cost of high generation latency in decoding. Recent proposals have explored variants of contemplation tokens, a term we introduce that refers to special tokens used during inference to allow for extra computation. Prior work has considered fixed-length sequences drawn from a discrete set of embeddings as contemplation tokens. Here we propose Compressed Chain-of-Thought (CCoT), a framework to generate contentful and continuous contemplation tokens of variable sequence length. The generated contemplation tokens are compressed representations of explicit reasoning chains, and our method can be applied to off-the-shelf decoder language models. Through experiments, we illustrate how CCoT enables additional reasoning over dense contentful representations to achieve corresponding improvements in accuracy. Moreover, the reasoning improvements can be adaptively modified on demand by controlling the number of contemplation tokens generated.
Dated Data: Tracing Knowledge Cutoffs in Large Language Models
Mar 19, 2024Released Large Language Models (LLMs) are often paired with a claimed knowledge cutoff date, or the dates at which training data was gathered. Such information is crucial for applications where the LLM must provide up to date information. However, this statement only scratches the surface: do all resources in the training data share the same knowledge cutoff date? Does the model's demonstrated knowledge for these subsets closely align to their cutoff dates? In this work, we define the notion of an effective cutoff. This is distinct from the LLM designer reported cutoff and applies separately to sub-resources and topics. We propose a simple approach to estimate effective cutoffs on the resource-level temporal alignment of an LLM by probing across versions of the data. Using this analysis, we find that effective cutoffs often differ from reported cutoffs. To understand the root cause of this observation, we conduct a direct large-scale analysis on open pre-training datasets. Our analysis reveals two reasons for these inconsistencies: (1) temporal biases of CommonCrawl data due to non-trivial amounts of old data in new dumps and (2) complications in LLM deduplication schemes involving semantic duplicates and lexical near-duplicates. Overall, our results show that knowledge cutoffs are not as simple as they have seemed and that care must be taken both by LLM dataset curators as well as practitioners who seek to use information from these models.
Augmenting Supervised Learning by Meta-learning Unsupervised Local Rules
Mar 17, 2021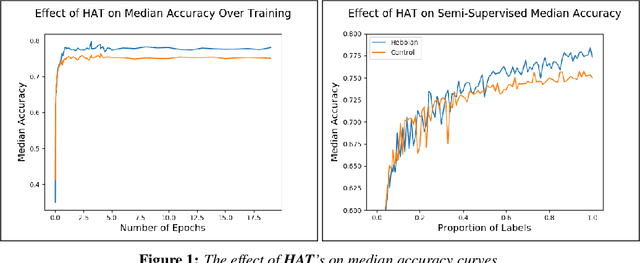
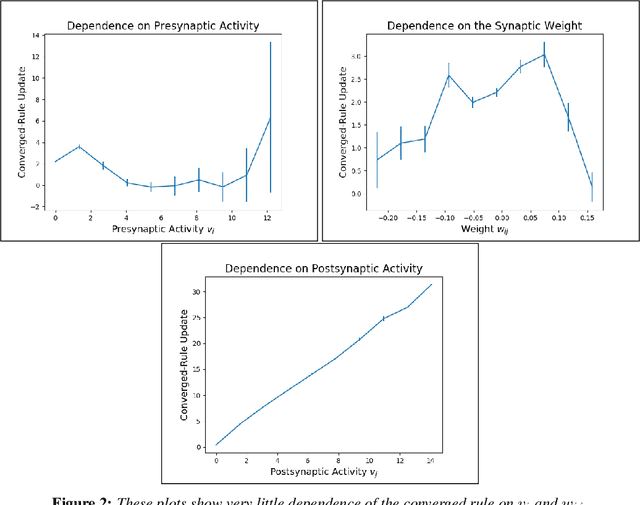
The brain performs unsupervised learning and (perhaps) simultaneous supervised learning. This raises the question as to whether a hybrid of supervised and unsupervised methods will produce better learning. Inspired by the rich space of Hebbian learning rules, we set out to directly learn the unsupervised learning rule on local information that best augments a supervised signal. We present the Hebbian-augmented training algorithm (HAT) for combining gradient-based learning with an unsupervised rule on pre-synpatic activity, post-synaptic activities, and current weights. We test HAT's effect on a simple problem (Fashion-MNIST) and find consistently higher performance than supervised learning alone. This finding provides empirical evidence that unsupervised learning on synaptic activities provides a strong signal that can be used to augment gradient-based methods. We further find that the meta-learned update rule is a time-varying function; thus, it is difficult to pinpoint an interpretable Hebbian update rule that aids in training. We do find that the meta-learner eventually degenerates into a non-Hebbian rule that preserves important weights so as not to disturb the learner's convergence.
Bilingual is At Least Monolingual : A Novel Translation Algorithm that Encodes Monolingual Priors
Aug 30, 2019
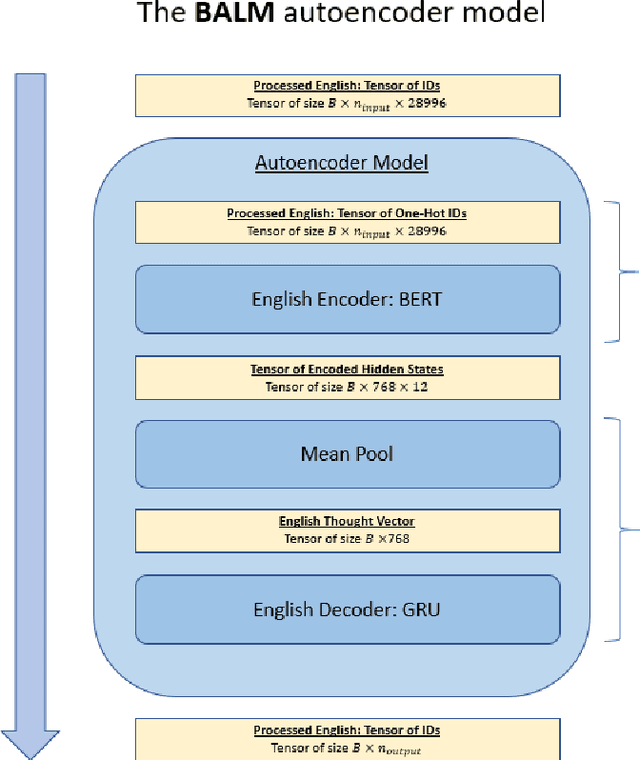
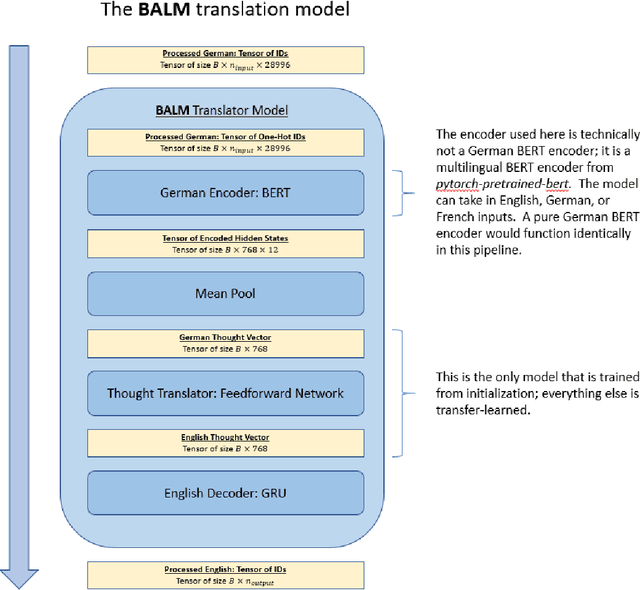
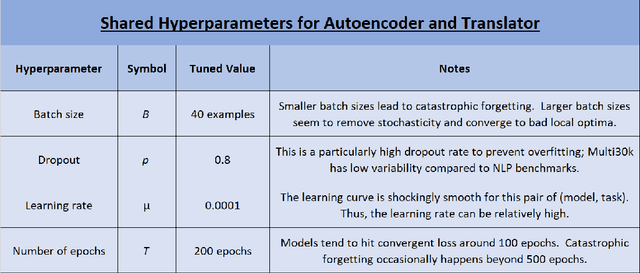
State-of-the-art machine translation (MT) models do not use knowledge of any single language's structure; this is the equivalent of asking someone to translate from English to German while knowing neither language. BALM is a framework incorporates monolingual priors into an MT pipeline; by casting input and output languages into embedded space using BERT, we can solve machine translation with much simpler models. We find that English-to-German translation on the Multi30k dataset can be solved with a simple feedforward network under the BALM framework with near-SOTA BLEU scores.
AI Reasoning Systems: PAC and Applied Methods
Jul 09, 2018
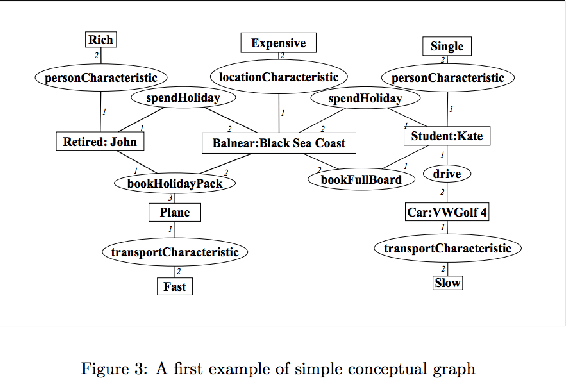

Learning and logic are distinct and remarkable approaches to prediction. Machine learning has experienced a surge in popularity because it is robust to noise and achieves high performance; however, ML experiences many issues with knowledge transfer and extrapolation. In contrast, logic is easily intepreted, and logical rules are easy to chain and transfer between systems; however, inductive logic is brittle to noise. We then explore the premise of combining learning with inductive logic into AI Reasoning Systems. Specifically, we summarize findings from PAC learning (conceptual graphs, robust logics, knowledge infusion) and deep learning (DSRL, $\partial$ILP, DeepLogic) by reproducing proofs of tractability, presenting algorithms in pseudocode, highlighting results, and synthesizing between fields. We conclude with suggestions for integrated models by combining the modules listed above and with a list of unsolved (likely intractable) problems.