 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking LoRA Memory Through the Lens of KV Cache Compression
Jun 04, 2026Parametric retrieval augmentation encodes document information into lightweight, document-specific modules such as LoRA adapters, reducing the need to include all evidence as input context. However, it remains unclear how this parameter-side memory interacts with context-side memory stored in the KV cache. We study this interaction in document-level question answering by progressively evicting document key-value states and measuring when a document LoRA contributes beyond the retained context. We find that document LoRA adds little when the KV cache is largely intact, but becomes increasingly useful under aggressive compression, recovering 13-21 ROUGE-L points when no document context remains. The gain is largest when the base model encodes the document, and the adapter is applied only during answer generation, suggesting that document LoRA is better understood as decoding-time parametric memory than as a document encoder. Finally, QA-style supervision produces substantially stronger adapters than raw-context next-token-prediction. These results position document LoRA as a complementary memory channel whose value emerges precisely when context-side evidence is scarce.
DAR: Deontic Reasoning with Agentic Harnesses
Jun 03, 2026Deontic reasoning is the task of answering questions by applying explicit rules and policies to case-specific facts, for example computing tax liability under a statute or determining the outcome of an immigration appeal. A key technical challenge for LLM-based deontic reasoning is that the relevant ruleset can be long and cross-referenced, so models may still fail to locate the rules needed for a particular reasoning step. We introduce Deontic Agentic Reasoning (DAR), an agentic reasoning setup in which the model interacts with the statutes on demand. We evaluate DAR under multiple harnesses on hard subsets of DeonticBench. Across these settings, we find that agentic harnesses can push the frontier on deontic reasoning tasks, but improvements are not uniform: weaker models often degrade on numerical tasks while consuming far more tokens.
Process Supervision of Confidence Margin for Calibrated LLM Reasoning
Apr 25, 2026Scaling test-time computation with reinforcement learning (RL) has emerged as a reliable path to improve large language models (LLM) reasoning ability. Yet, outcome-based reward often incentivizes models to be overconfident, leading to hallucinations, unreliable confidence-based control, and unnecessary compute allocation. We introduce Reinforcement Learning with Confidence Margin (\textbf{RLCM}), a calibration-aware RL framework that jointly optimizes correctness and confidence reliability via a margin-enhanced process reward over intermediate-budget completions. Rather than aligning confidence to correctness likelihoods, RLCM encourages to widen the confidence margin between correct and incorrect steps within a single reasoning trajectory. Across mathematical, code, logic and science benchmarks, our method substantially improves calibration while maintaining or improving accuracy. We further show that, with calibrated confidence signals, the resulting models enable more efficient conformal risk control and effective confidence-weighted aggregation.
Many-Tier Instruction Hierarchy in LLM Agents
Apr 14, 2026Large language model agents receive instructions from many sources-system messages, user prompts, tool outputs, other agents, and more-each carrying different levels of trust and authority. When these instructions conflict, agents must reliably follow the highest-privilege instruction to remain safe and effective. The dominant paradigm, instruction hierarchy (IH), assumes a fixed, small set of privilege levels (typically fewer than five) defined by rigid role labels (e.g., system > user). This is inadequate for real-world agentic settings, where conflicts can arise across far more sources and contexts. In this work, we propose Many-Tier Instruction Hierarchy (ManyIH), a paradigm for resolving instruction conflicts among instructions with arbitrarily many privilege levels. We introduce ManyIH-Bench, the first benchmark for ManyIH. ManyIH-Bench requires models to navigate up to 12 levels of conflicting instructions with varying privileges, comprising 853 agentic tasks (427 coding and 426 instruction-following). ManyIH-Bench composes constraints developed by LLMs and verified by humans to create realistic and difficult test cases spanning 46 real-world agents. Our experiments show that even the current frontier models perform poorly (~40% accuracy) when instruction conflict scales. This work underscores the urgent need for methods that explicitly target fine-grained, scalable instruction conflict resolution in agentic settings.
Unified Multimodal Uncertain Inference
Apr 13, 2026We introduce Unified Multimodal Uncertain Inference (UMUI), a multimodal inference task spanning text, audio, and video, where models must produce calibrated probability estimates of hypotheses conditioned on a premise in any modality or combination. While uncertain inference has been explored in text, extension to other modalities has been limited to single-modality binary entailment judgments, leaving no framework for fine-grained probabilistic reasoning in or across other modalities. To address this, we curate a human-annotated evaluation set with scalar probability judgments across audio, visual, and audiovisual settings, and additionally evaluate on existing text and audio benchmarks. We introduce CLUE (Calibrated Latent Uncertainty Estimation), which combines self-consistent teacher calibration and distribution-based confidence probing to produce calibrated predictions. We demonstrate that our 3B-parameter model achieves equivalent or stronger performance than baselines up to 32B parameters across all modalities.
Weird Generalization is Weirdly Brittle
Apr 11, 2026Weird generalization is a phenomenon in which models fine-tuned on data from a narrow domain (e.g. insecure code) develop surprising traits that manifest even outside that domain (e.g. broad misalignment)-a phenomenon that prior work has highlighted as a critical safety concern. Here, we present an extended replication study of key weird generalization results across an expanded suite of models and datasets. We confirm that surprising (and dangerous) traits can emerge under certain circumstances, but we find that weird generalization is exceptionally brittle: it emerges only for specific models on specific datasets, and it vanishes under simple training-time, prompt-based interventions. We find that the most effective interventions provide prompt context that makes the generalized behavior the expected behavior. However, we show that even very generic interventions that do not anticipate specific generalized traits can still be effective in mitigating weird generalization's effects. Our findings thus help clarify the nature of the safety threat that weird generalization poses and point toward an easily implemented set of solutions.
DeonticBench: A Benchmark for Reasoning over Rules
Apr 06, 2026Reasoning with complex, context-specific rules remains challenging for large language models (LLMs). In legal and policy settings, this manifests as deontic reasoning: reasoning about obligations, permissions, and prohibitions under explicit rules. While many recent benchmarks emphasize short-context mathematical reasoning, fewer focus on long-context, high-stakes deontic reasoning. To address this gap, we introduce DEONTICBENCH, a benchmark of 6,232 tasks across U.S. federal taxes, airline baggage policies, U.S. immigration administration, and U.S. state housing law. These tasks can be approached in multiple ways, including direct reasoning in language or with the aid of symbolic computation. Besides free-form chain-of-thought reasoning, DEONTICBENCH enables an optional solver-based workflow in which models translate statutes and case facts into executable Prolog, leading to formal problem interpretations and an explicit program trace. We release reference Prolog programs for all instances. Across frontier LLMs and coding models, best hard-subset performance reaches only 44.4% on SARA Numeric and 46.6 macro-F1 on Housing. We further study training with supervised fine-tuning and reinforcement learning for symbolic program generation. Although training improves Prolog generation quality, current RL methods still fail to solve these tasks reliably. Overall, DEONTICBENCH provides a benchmark for studying context-grounded rule reasoning in real-world domains under both symbolic and non-symbolic settings.
Conformal Thinking: Risk Control for Reasoning on a Compute Budget
Feb 03, 2026Reasoning Large Language Models (LLMs) enable test-time scaling, with dataset-level accuracy improving as the token budget increases, motivating adaptive reasoning -- spending tokens when they improve reliability and stopping early when additional computation is unlikely to help. However, setting the token budget, as well as the threshold for adaptive reasoning, is a practical challenge that entails a fundamental risk-accuracy trade-off. We re-frame the budget setting problem as risk control, limiting the error rate while minimizing compute. Our framework introduces an upper threshold that stops reasoning when the model is confident (risking incorrect output) and a novel parametric lower threshold that preemptively stops unsolvable instances (risking premature stoppage). Given a target risk and a validation set, we use distribution-free risk control to optimally specify these stopping mechanisms. For scenarios with multiple budget controlling criteria, we incorporate an efficiency loss to select the most computationally efficient exiting mechanism. Empirical results across diverse reasoning tasks and models demonstrate the effectiveness of our risk control approach, demonstrating computational efficiency gains from the lower threshold and ensemble stopping mechanisms while adhering to the user-specified risk target.
Enabling Equitable Access to Trustworthy Financial Reasoning
Aug 28, 2025According to the United States Internal Revenue Service, ''the average American spends $\$270$ and 13 hours filing their taxes''. Even beyond the U.S., tax filing requires complex reasoning, combining application of overlapping rules with numerical calculations. Because errors can incur costly penalties, any automated system must deliver high accuracy and auditability, making modern large language models (LLMs) poorly suited for this task. We propose an approach that integrates LLMs with a symbolic solver to calculate tax obligations. We evaluate variants of this system on the challenging StAtutory Reasoning Assessment (SARA) dataset, and include a novel method for estimating the cost of deploying such a system based on real-world penalties for tax errors. We further show how combining up-front translation of plain-text rules into formal logic programs, combined with intelligently retrieved exemplars for formal case representations, can dramatically improve performance on this task and reduce costs to well below real-world averages. Our results demonstrate the promise and economic feasibility of neuro-symbolic architectures for increasing equitable access to reliable tax assistance.
CLAIMCHECK: How Grounded are LLM Critiques of Scientific Papers?
Mar 27, 2025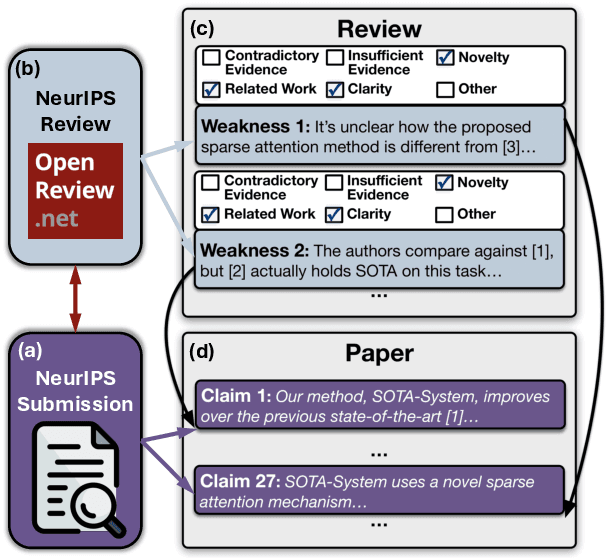
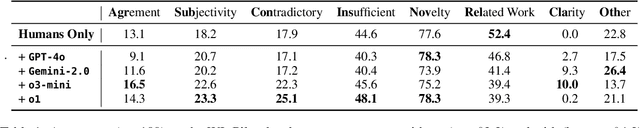
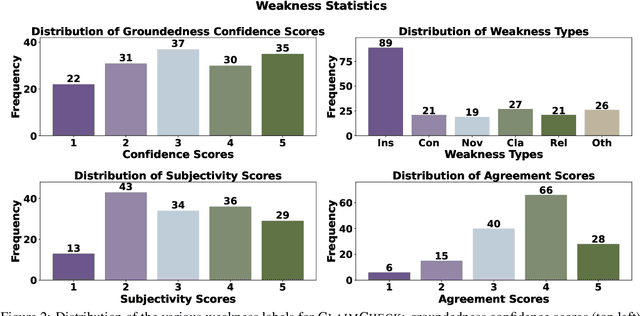
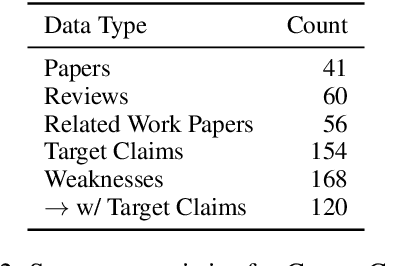
A core part of scientific peer review involves providing expert critiques that directly assess the scientific claims a paper makes. While it is now possible to automatically generate plausible (if generic) reviews, ensuring that these reviews are sound and grounded in the papers' claims remains challenging. To facilitate LLM benchmarking on these challenges, we introduce CLAIMCHECK, an annotated dataset of NeurIPS 2023 and 2024 submissions and reviews mined from OpenReview. CLAIMCHECK is richly annotated by ML experts for weakness statements in the reviews and the paper claims that they dispute, as well as fine-grained labels of the validity, objectivity, and type of the identified weaknesses. We benchmark several LLMs on three claim-centric tasks supported by CLAIMCHECK, requiring models to (1) associate weaknesses with the claims they dispute, (2) predict fine-grained labels for weaknesses and rewrite the weaknesses to enhance their specificity, and (3) verify a paper's claims with grounded reasoning. Our experiments reveal that cutting-edge LLMs, while capable of predicting weakness labels in (2), continue to underperform relative to human experts on all other tasks.