 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan A Society of Generative Agents Simulate Human Behavior and Inform Public Health Policy? A Case Study on Vaccine Hesitancy
Mar 12, 2025Can we simulate a sandbox society with generative agents to model human behavior, thereby reducing the over-reliance on real human trials for assessing public policies? In this work, we investigate the feasibility of simulating health-related decision-making, using vaccine hesitancy, defined as the delay in acceptance or refusal of vaccines despite the availability of vaccination services (MacDonald, 2015), as a case study. To this end, we introduce the VacSim framework with 100 generative agents powered by Large Language Models (LLMs). VacSim simulates vaccine policy outcomes with the following steps: 1) instantiate a population of agents with demographics based on census data; 2) connect the agents via a social network and model vaccine attitudes as a function of social dynamics and disease-related information; 3) design and evaluate various public health interventions aimed at mitigating vaccine hesitancy. To align with real-world results, we also introduce simulation warmup and attitude modulation to adjust agents' attitudes. We propose a series of evaluations to assess the reliability of various LLM simulations. Experiments indicate that models like Llama and Qwen can simulate aspects of human behavior but also highlight real-world alignment challenges, such as inconsistent responses with demographic profiles. This early exploration of LLM-driven simulations is not meant to serve as definitive policy guidance; instead, it serves as a call for action to examine social simulation for policy development.
Gaps or Hallucinations? Gazing into Machine-Generated Legal Analysis for Fine-grained Text Evaluations
Sep 16, 2024Large Language Models (LLMs) show promise as a writing aid for professionals performing legal analyses. However, LLMs can often hallucinate in this setting, in ways difficult to recognize by non-professionals and existing text evaluation metrics. In this work, we pose the question: when can machine-generated legal analysis be evaluated as acceptable? We introduce the neutral notion of gaps, as opposed to hallucinations in a strict erroneous sense, to refer to the difference between human-written and machine-generated legal analysis. Gaps do not always equate to invalid generation. Working with legal experts, we consider the CLERC generation task proposed in Hou et al. (2024b), leading to a taxonomy, a fine-grained detector for predicting gap categories, and an annotated dataset for automatic evaluation. Our best detector achieves 67% F1 score and 80% precision on the test set. Employing this detector as an automated metric on legal analysis generated by SOTA LLMs, we find around 80% contain hallucinations of different kinds.
CLERC: A Dataset for Legal Case Retrieval and Retrieval-Augmented Analysis Generation
Jun 24, 2024
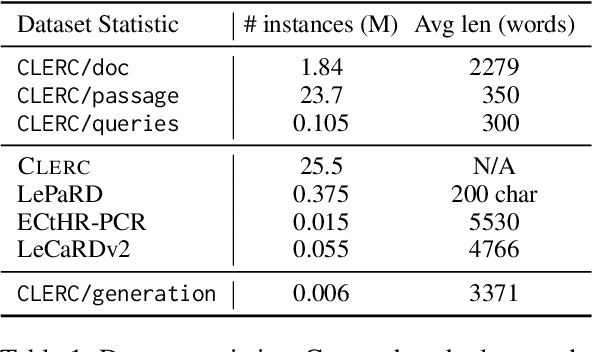


Legal professionals need to write analyses that rely on citations to relevant precedents, i.e., previous case decisions. Intelligent systems assisting legal professionals in writing such documents provide great benefits but are challenging to design. Such systems need to help locate, summarize, and reason over salient precedents in order to be useful. To enable systems for such tasks, we work with legal professionals to transform a large open-source legal corpus into a dataset supporting two important backbone tasks: information retrieval (IR) and retrieval-augmented generation (RAG). This dataset CLERC (Case Law Evaluation Retrieval Corpus), is constructed for training and evaluating models on their ability to (1) find corresponding citations for a given piece of legal analysis and to (2) compile the text of these citations (as well as previous context) into a cogent analysis that supports a reasoning goal. We benchmark state-of-the-art models on CLERC, showing that current approaches still struggle: GPT-4o generates analyses with the highest ROUGE F-scores but hallucinates the most, while zero-shot IR models only achieve 48.3% recall@1000.
Stumbling Blocks: Stress Testing the Robustness of Machine-Generated Text Detectors Under Attacks
Feb 18, 2024The widespread use of large language models (LLMs) is increasing the demand for methods that detect machine-generated text to prevent misuse. The goal of our study is to stress test the detectors' robustness to malicious attacks under realistic scenarios. We comprehensively study the robustness of popular machine-generated text detectors under attacks from diverse categories: editing, paraphrasing, prompting, and co-generating. Our attacks assume limited access to the generator LLMs, and we compare the performance of detectors on different attacks under different budget levels. Our experiments reveal that almost none of the existing detectors remain robust under all the attacks, and all detectors exhibit different loopholes. Averaging all detectors, the performance drops by 35% across all attacks. Further, we investigate the reasons behind these defects and propose initial out-of-the-box patches to improve robustness.
k-SemStamp: A Clustering-Based Semantic Watermark for Detection of Machine-Generated Text
Feb 17, 2024Recent watermarked generation algorithms inject detectable signatures during language generation to facilitate post-hoc detection. While token-level watermarks are vulnerable to paraphrase attacks, SemStamp (Hou et al., 2023) applies watermark on the semantic representation of sentences and demonstrates promising robustness. SemStamp employs locality-sensitive hashing (LSH) to partition the semantic space with arbitrary hyperplanes, which results in a suboptimal tradeoff between robustness and speed. We propose k-SemStamp, a simple yet effective enhancement of SemStamp, utilizing k-means clustering as an alternative of LSH to partition the embedding space with awareness of inherent semantic structure. Experimental results indicate that k-SemStamp saliently improves its robustness and sampling efficiency while preserving the generation quality, advancing a more effective tool for machine-generated text detection.
SemStamp: A Semantic Watermark with Paraphrastic Robustness for Text Generation
Oct 06, 2023Existing watermarking algorithms are vulnerable to paraphrase attacks because of their token-level design. To address this issue, we propose SemStamp, a robust sentence-level semantic watermarking algorithm based on locality-sensitive hashing (LSH), which partitions the semantic space of sentences. The algorithm encodes and LSH-hashes a candidate sentence generated by an LLM, and conducts sentence-level rejection sampling until the sampled sentence falls in watermarked partitions in the semantic embedding space. A margin-based constraint is used to enhance its robustness. To show the advantages of our algorithm, we propose a "bigram" paraphrase attack using the paraphrase that has the fewest bigram overlaps with the original sentence. This attack is shown to be effective against the existing token-level watermarking method. Experimental results show that our novel semantic watermark algorithm is not only more robust than the previous state-of-the-art method on both common and bigram paraphrase attacks, but also is better at preserving the quality of generation.