 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKARLA: Knowledge-base Augmented Retrieval for Language Models
Jun 25, 2026We propose a new method that allows an LLM to automatically pull in factual knowledge from a knowledge base during token generation. This means that (1)~factual knowledge in the LLM output can be updated without retraining the LLM, (2)~facts in the LLM output can be traced to the knowledge base for transparency and explainability, and (3)~smaller models can achieve the same factual accuracy as larger models. Our core idea is to train the model to produce special tokens that trigger a query to the knowledge base. Our experiments show that our method improves factual grounding in both short and long-form generation, and allows factual revisions to take effect through KB edits rather than parameter updates.
DAR: Deontic Reasoning with Agentic Harnesses
Jun 03, 2026Deontic reasoning is the task of answering questions by applying explicit rules and policies to case-specific facts, for example computing tax liability under a statute or determining the outcome of an immigration appeal. A key technical challenge for LLM-based deontic reasoning is that the relevant ruleset can be long and cross-referenced, so models may still fail to locate the rules needed for a particular reasoning step. We introduce Deontic Agentic Reasoning (DAR), an agentic reasoning setup in which the model interacts with the statutes on demand. We evaluate DAR under multiple harnesses on hard subsets of DeonticBench. Across these settings, we find that agentic harnesses can push the frontier on deontic reasoning tasks, but improvements are not uniform: weaker models often degrade on numerical tasks while consuming far more tokens.
LELA: An End-to-end LLM-based Entity Linking Framework with Zero-shot Domain Adaptation
May 26, 2026Entity linking is a key component of many downstream NLP systems, yet existing approaches are often tied to the specific target knowledge bases and domains, limiting their real world application. In this paper, we extend LELA, a modular and domain-agnostic LLM-based entity disambiguation method, into a practical Python library that integrates zero-shot Named Entity Recognition (NER) -thereby providing a complete end-toend pipeline for entity-linking in real-world usage. We provide experimental results validating LELA's performance and robustness across diverse entity linking settings. In our demo, users can play with the system on their own input texts.
DeonticBench: A Benchmark for Reasoning over Rules
Apr 06, 2026Reasoning with complex, context-specific rules remains challenging for large language models (LLMs). In legal and policy settings, this manifests as deontic reasoning: reasoning about obligations, permissions, and prohibitions under explicit rules. While many recent benchmarks emphasize short-context mathematical reasoning, fewer focus on long-context, high-stakes deontic reasoning. To address this gap, we introduce DEONTICBENCH, a benchmark of 6,232 tasks across U.S. federal taxes, airline baggage policies, U.S. immigration administration, and U.S. state housing law. These tasks can be approached in multiple ways, including direct reasoning in language or with the aid of symbolic computation. Besides free-form chain-of-thought reasoning, DEONTICBENCH enables an optional solver-based workflow in which models translate statutes and case facts into executable Prolog, leading to formal problem interpretations and an explicit program trace. We release reference Prolog programs for all instances. Across frontier LLMs and coding models, best hard-subset performance reaches only 44.4% on SARA Numeric and 46.6 macro-F1 on Housing. We further study training with supervised fine-tuning and reinforcement learning for symbolic program generation. Although training improves Prolog generation quality, current RL methods still fail to solve these tasks reliably. Overall, DEONTICBENCH provides a benchmark for studying context-grounded rule reasoning in real-world domains under both symbolic and non-symbolic settings.
Where Experts Disagree, Models Fail: Detecting Implicit Legal Citations in French Court Decisions
Mar 24, 2026Computational methods applied to legal scholarship hold the promise of analyzing law at scale. We start from a simple question: how often do courts implicitly apply statutory rules? This requires distinguishing legal reasoning from semantic similarity. We focus on implicit citation of the French Civil Code in first-instance court decisions and introduce a benchmark of 1,015 passage-article pairs annotated by three legal experts. We show that expert disagreement predicts model failures. Inter-annotator agreement is moderate ($κ$ = 0.33) with 43% of disagreements involving the boundary between factual description and legal reasoning. Our supervised ensemble achieves F1 = 0.70 (77% accuracy), but this figure conceals an asymmetry: 68% of false positives fall on the 33% of cases where the annotators disagreed. Despite these limits, reframing the task as top-k ranking and leveraging multi-model consensus yields 76% precision at k = 200 in an unsupervised setting. Moreover, the remaining false positives tend to surface legally ambiguous applications rather than obvious errors.
LELA: an LLM-based Entity Linking Approach with Zero-Shot Domain Adaptation
Jan 08, 2026Entity linking (mapping ambiguous mentions in text to entities in a knowledge base) is a foundational step in tasks such as knowledge graph construction, question-answering, and information extraction. Our method, LELA, is a modular coarse-to-fine approach that leverages the capabilities of large language models (LLMs), and works with different target domains, knowledge bases and LLMs, without any fine-tuning phase. Our experiments across various entity linking settings show that LELA is highly competitive with fine-tuned approaches, and substantially outperforms the non-fine-tuned ones.
Enabling Equitable Access to Trustworthy Financial Reasoning
Aug 28, 2025According to the United States Internal Revenue Service, ''the average American spends $\$270$ and 13 hours filing their taxes''. Even beyond the U.S., tax filing requires complex reasoning, combining application of overlapping rules with numerical calculations. Because errors can incur costly penalties, any automated system must deliver high accuracy and auditability, making modern large language models (LLMs) poorly suited for this task. We propose an approach that integrates LLMs with a symbolic solver to calculate tax obligations. We evaluate variants of this system on the challenging StAtutory Reasoning Assessment (SARA) dataset, and include a novel method for estimating the cost of deploying such a system based on real-world penalties for tax errors. We further show how combining up-front translation of plain-text rules into formal logic programs, combined with intelligently retrieved exemplars for formal case representations, can dramatically improve performance on this task and reduce costs to well below real-world averages. Our results demonstrate the promise and economic feasibility of neuro-symbolic architectures for increasing equitable access to reliable tax assistance.
Can AI expose tax loopholes? Towards a new generation of legal policy assistants
Mar 21, 2025

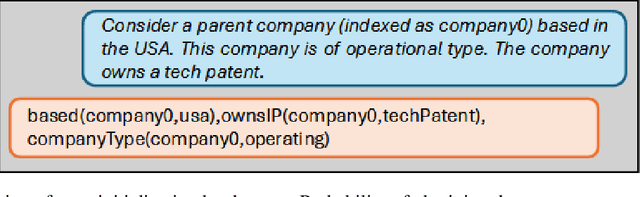

The legislative process is the backbone of a state built on solid institutions. Yet, due to the complexity of laws -- particularly tax law -- policies may lead to inequality and social tensions. In this study, we introduce a novel prototype system designed to address the issues of tax loopholes and tax avoidance. Our hybrid solution integrates a natural language interface with a domain-specific language tailored for planning. We demonstrate on a case study how tax loopholes and avoidance schemes can be exposed. We conclude that our prototype can help enhance social welfare by systematically identifying and addressing tax gaps stemming from loopholes.
The Factuality of Large Language Models in the Legal Domain
Sep 18, 2024



This paper investigates the factuality of large language models (LLMs) as knowledge bases in the legal domain, in a realistic usage scenario: we allow for acceptable variations in the answer, and let the model abstain from answering when uncertain. First, we design a dataset of diverse factual questions about case law and legislation. We then use the dataset to evaluate several LLMs under different evaluation methods, including exact, alias, and fuzzy matching. Our results show that the performance improves significantly under the alias and fuzzy matching methods. Further, we explore the impact of abstaining and in-context examples, finding that both strategies enhance precision. Finally, we demonstrate that additional pre-training on legal documents, as seen with SaulLM, further improves factual precision from 63% to 81%.
Gaps or Hallucinations? Gazing into Machine-Generated Legal Analysis for Fine-grained Text Evaluations
Sep 16, 2024Large Language Models (LLMs) show promise as a writing aid for professionals performing legal analyses. However, LLMs can often hallucinate in this setting, in ways difficult to recognize by non-professionals and existing text evaluation metrics. In this work, we pose the question: when can machine-generated legal analysis be evaluated as acceptable? We introduce the neutral notion of gaps, as opposed to hallucinations in a strict erroneous sense, to refer to the difference between human-written and machine-generated legal analysis. Gaps do not always equate to invalid generation. Working with legal experts, we consider the CLERC generation task proposed in Hou et al. (2024b), leading to a taxonomy, a fine-grained detector for predicting gap categories, and an annotated dataset for automatic evaluation. Our best detector achieves 67% F1 score and 80% precision on the test set. Employing this detector as an automated metric on legal analysis generated by SOTA LLMs, we find around 80% contain hallucinations of different kinds.