 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLORA: Unsupervised Knowledge Graph Alignment by Fuzzy Logic
Oct 23, 2025Knowledge graph alignment is the task of matching equivalent entities (that is, instances and classes) and relations across two knowledge graphs. Most existing methods focus on pure entity-level alignment, computing the similarity of entities in some embedding space. They lack interpretable reasoning and need training data to work. In this paper, we propose FLORA, a simple yet effective method that (1) is unsupervised, i.e., does not require training data, (2) provides a holistic alignment for entities and relations iteratively, (3) is based on fuzzy logic and thus delivers interpretable results, (4) provably converges, (5) allows dangling entities, i.e., entities without a counterpart in the other KG, and (6) achieves state-of-the-art results on major benchmarks.
Graph as a feature: improving node classification with non-neural graph-aware logistic regression
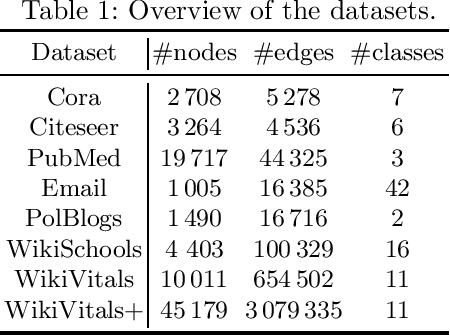
Nov 19, 2024Graph Neural Networks (GNNs) and their message passing framework that leverages both structural and feature information, have become a standard method for solving graph-based machine learning problems. However, these approaches still struggle to generalise well beyond datasets that exhibit strong homophily, where nodes of the same class tend to connect. This limitation has led to the development of complex neural architectures that pose challenges in terms of efficiency and scalability. In response to these limitations, we focus on simpler and more scalable approaches and introduce Graph-aware Logistic Regression (GLR), a non-neural model designed for node classification tasks. Unlike traditional graph algorithms that use only a fraction of the information accessible to GNNs, our proposed model simultaneously leverages both node features and the relationships between entities. However instead of relying on message passing, our approach encodes each node's relationships as an additional feature vector, which is then combined with the node's self attributes. Extensive experimental results, conducted within a rigorous evaluation framework, show that our proposed GLR approach outperforms both foundational and sophisticated state-of-the-art GNN models in node classification tasks. Going beyond the traditional limited benchmarks, our experiments indicate that GLR increases generalisation ability while reaching performance gains in computation time up to two orders of magnitude compared to it best neural competitor.
Revisiting Hierarchical Text Classification: Inference and Metrics
Oct 02, 2024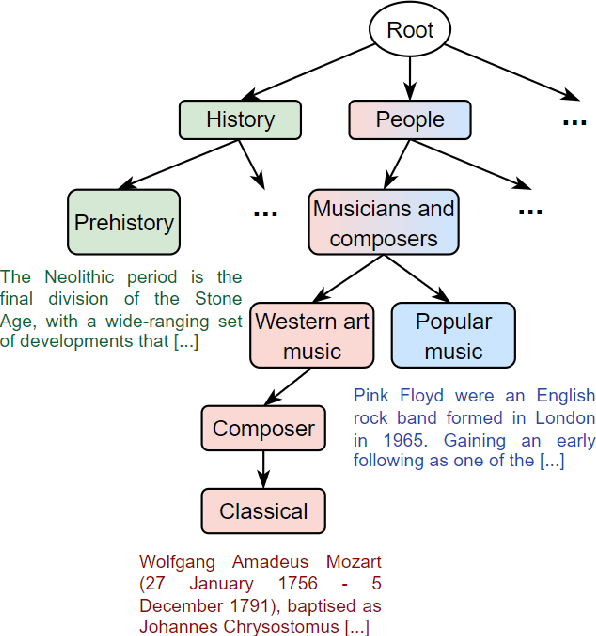
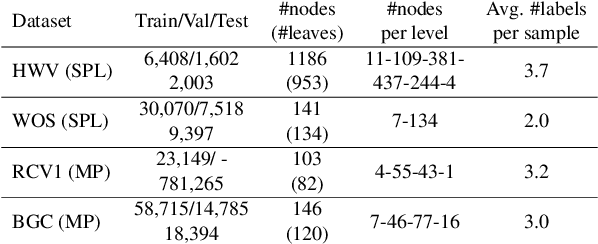
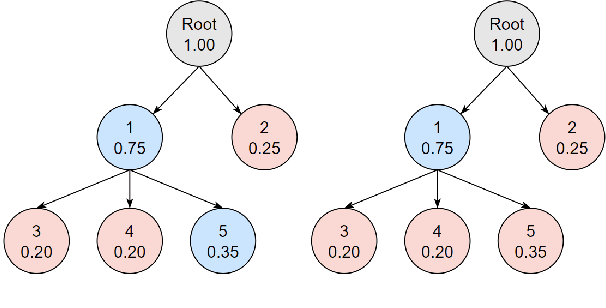
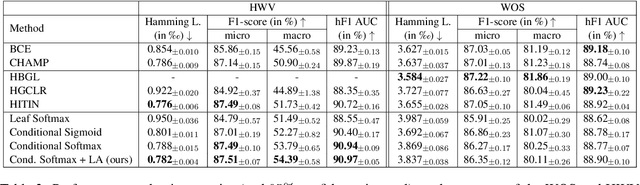
Hierarchical text classification (HTC) is the task of assigning labels to a text within a structured space organized as a hierarchy. Recent works treat HTC as a conventional multilabel classification problem, therefore evaluating it as such. We instead propose to evaluate models based on specifically designed hierarchical metrics and we demonstrate the intricacy of metric choice and prediction inference method. We introduce a new challenging dataset and we evaluate fairly, recent sophisticated models, comparing them with a range of simple but strong baselines, including a new theoretically motivated loss. Finally, we show that those baselines are very often competitive with the latest models. This highlights the importance of carefully considering the evaluation methodology when proposing new methods for HTC. Code implementation and dataset are available at \url{https://github.com/RomanPlaud/revisitingHTC}.
The Factuality of Large Language Models in the Legal Domain
Sep 18, 2024



This paper investigates the factuality of large language models (LLMs) as knowledge bases in the legal domain, in a realistic usage scenario: we allow for acceptable variations in the answer, and let the model abstain from answering when uncertain. First, we design a dataset of diverse factual questions about case law and legislation. We then use the dataset to evaluate several LLMs under different evaluation methods, including exact, alias, and fuzzy matching. Our results show that the performance improves significantly under the alias and fuzzy matching methods. Further, we explore the impact of abstaining and in-context examples, finding that both strategies enhance precision. Finally, we demonstrate that additional pre-training on legal documents, as seen with SaulLM, further improves factual precision from 63% to 81%.
Refining Wikidata Taxonomy using Large Language Models
Sep 06, 2024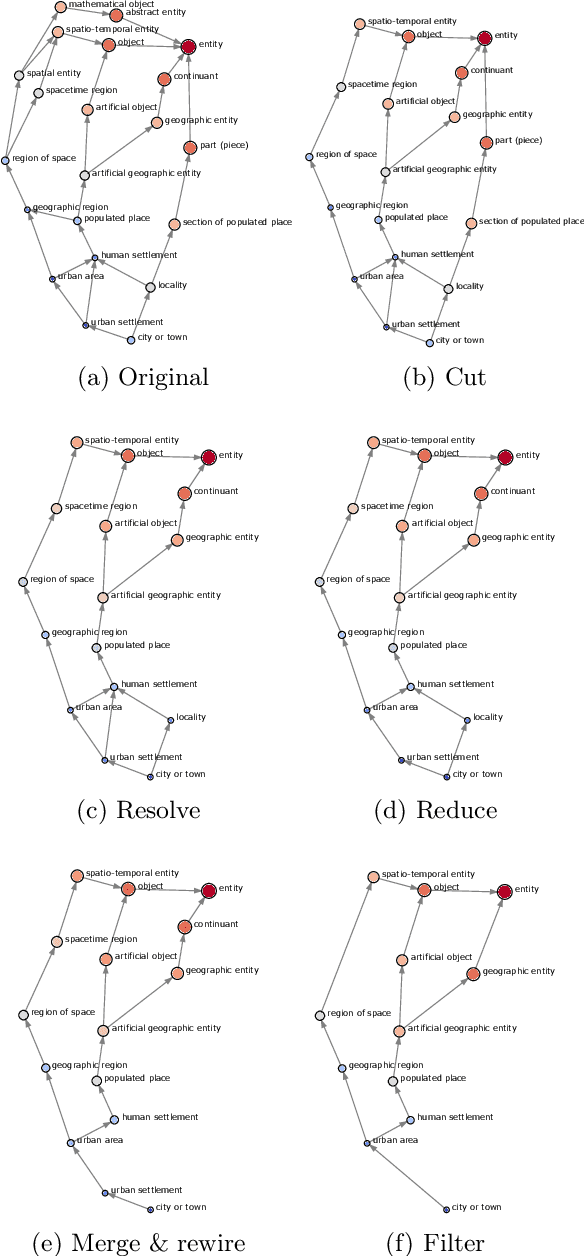
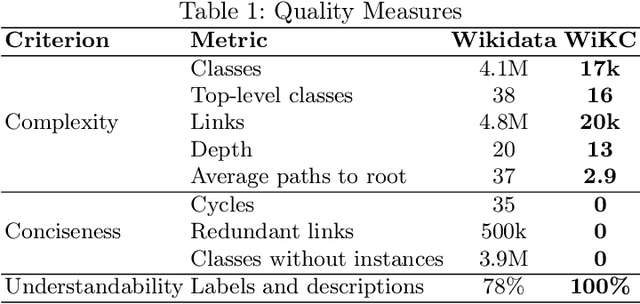

Due to its collaborative nature, Wikidata is known to have a complex taxonomy, with recurrent issues like the ambiguity between instances and classes, the inaccuracy of some taxonomic paths, the presence of cycles, and the high level of redundancy across classes. Manual efforts to clean up this taxonomy are time-consuming and prone to errors or subjective decisions. We present WiKC, a new version of Wikidata taxonomy cleaned automatically using a combination of Large Language Models (LLMs) and graph mining techniques. Operations on the taxonomy, such as cutting links or merging classes, are performed with the help of zero-shot prompting on an open-source LLM. The quality of the refined taxonomy is evaluated from both intrinsic and extrinsic perspectives, on a task of entity typing for the latter, showing the practical interest of WiKC.
A Consistent Diffusion-Based Algorithm for Semi-Supervised Graph Learning
Nov 13, 2023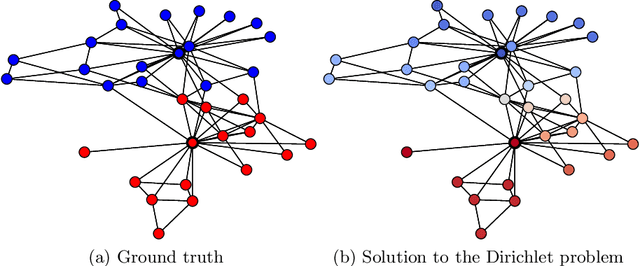
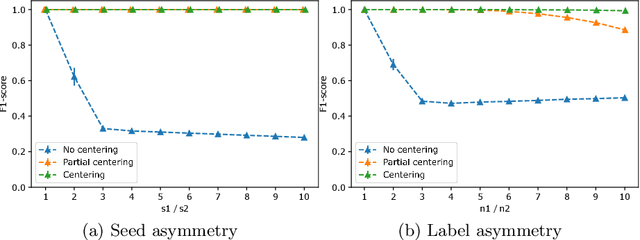
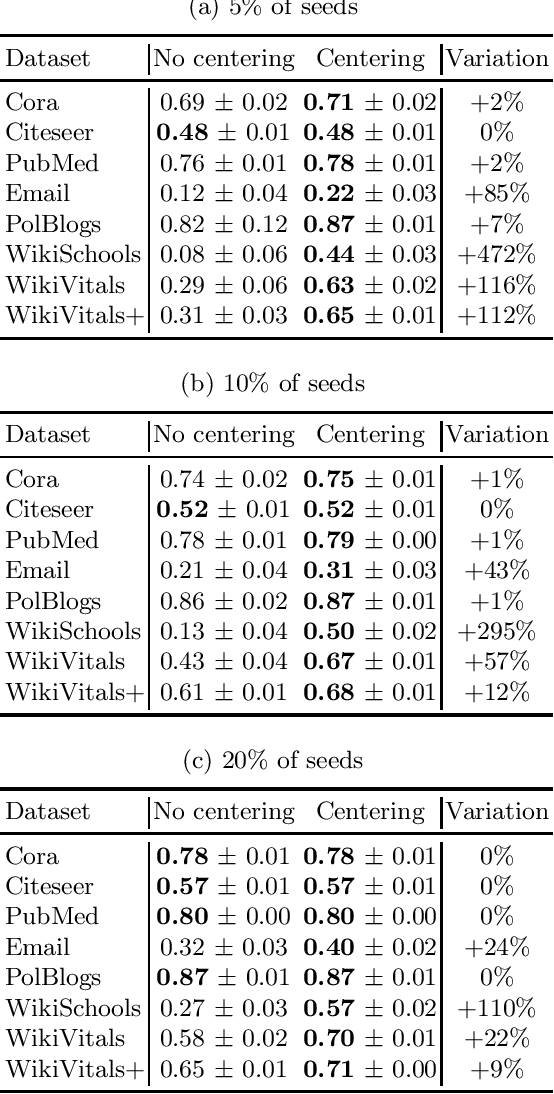
The task of semi-supervised classification aims at assigning labels to all nodes of a graph based on the labels known for a few nodes, called the seeds. One of the most popular algorithms relies on the principle of heat diffusion, where the labels of the seeds are spread by thermoconductance and the temperature of each node at equilibrium is used as a score function for each label. In this paper, we prove that this algorithm is not consistent unless the temperatures of the nodes at equilibrium are centered before scoring. This crucial step does not only make the algorithm provably consistent on a block model but brings significant performance gains on real graphs.
* arXiv admin note: substantial text overlap with arXiv:2008.11944
Integrating the Wikidata Taxonomy into YAGO
Aug 23, 2023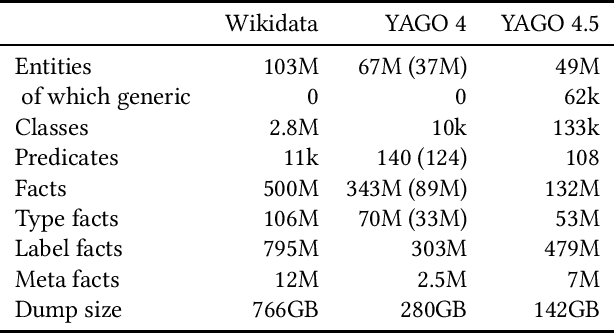
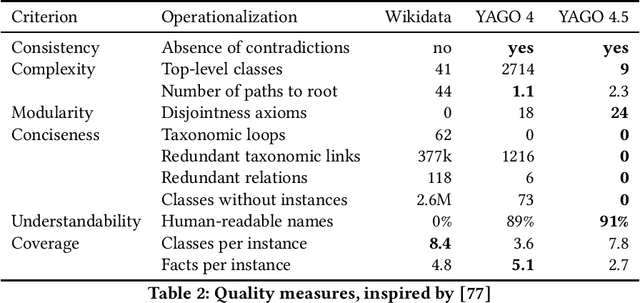
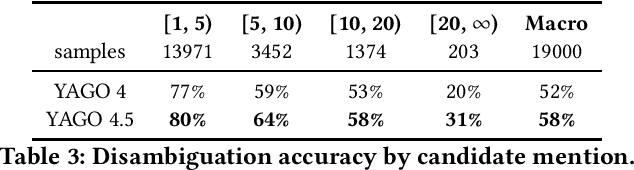
Wikidata is one of the largest public general-purpose Knowledge Bases (KBs). Yet, due to its collaborative nature, its schema and taxonomy have become convoluted. For the YAGO 4 KB, we combined Wikidata with the ontology from Schema.org, which reduced and cleaned up the taxonomy and constraints and made it possible to run automated reasoners on the data. However, it also cut away large parts of the Wikidata taxonomy. In this paper, we present our effort to merge the entire Wikidata taxonomy into the YAGO KB as much as possible. We pay particular attention to logical constraints and a careful distinction of classes and instances. Our work creates YAGO 4.5, which adds a rich layer of informative classes to YAGO, while at the same time keeping the KB logically consistent.
A Self-Encoder for Learning Nearest Neighbors
Jun 25, 2023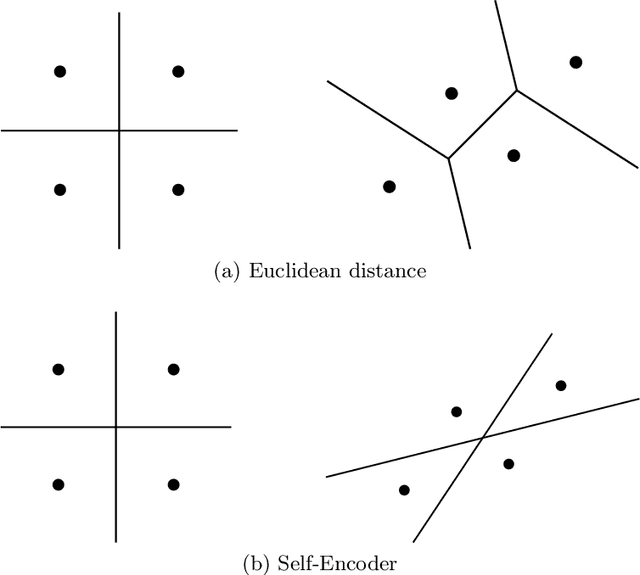
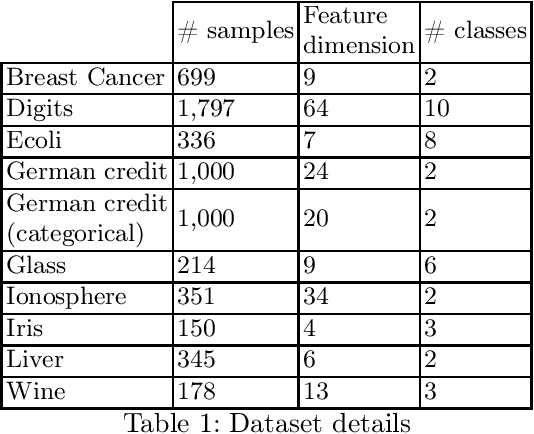
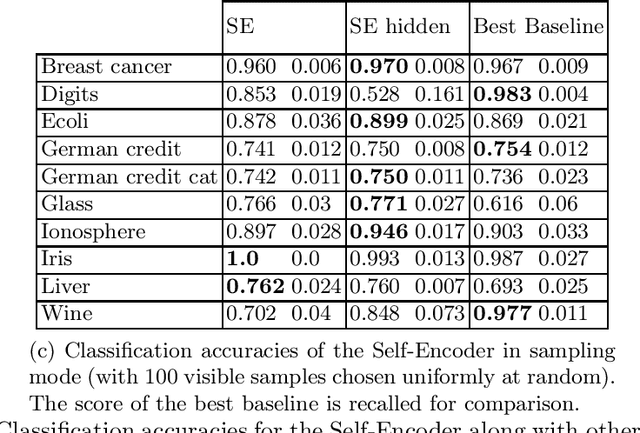
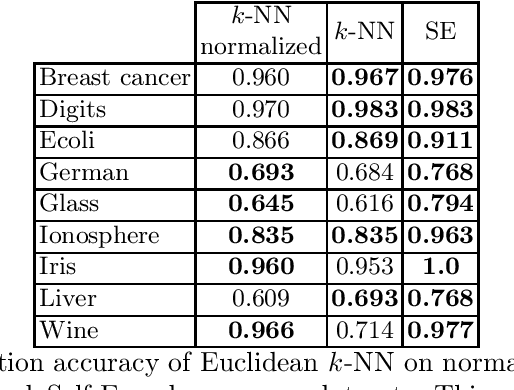
We present the self-encoder, a neural network trained to guess the identity of each data sample. Despite its simplicity, it learns a very useful representation of data, in a self-supervised way. Specifically, the self-encoder learns to distribute the data samples in the embedding space so that they are linearly separable from one another. This induces a geometry where two samples are close in the embedding space when they are not easy to differentiate. The self-encoder can then be combined with a nearest-neighbor classifier or regressor for any subsequent supervised task. Unlike regular nearest neighbors, the predictions resulting from this encoding of data are invariant to any scaling of features, making any preprocessing like min-max scaling not necessary. The experiments show the efficiency of the approach, especially on heterogeneous data mixing numerical features and categorical features.
KNNs of Semantic Encodings for Rating Prediction
Feb 01, 2023



This paper explores a novel application of textual semantic similarity to user-preference representation for rating prediction. The approach represents a user's preferences as a graph of textual snippets from review text, where the edges are defined by semantic similarity. This textual, memory-based approach to rating prediction enables review-based explanations for recommendations. The method is evaluated quantitatively, highlighting that leveraging text in this way outperforms both strong memory-based and model-based collaborative filtering baselines.
Pairwise Adjusted Mutual Information
Mar 23, 2021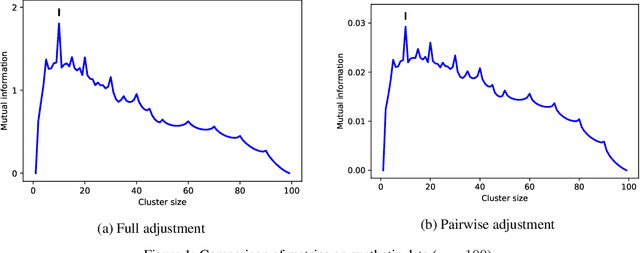
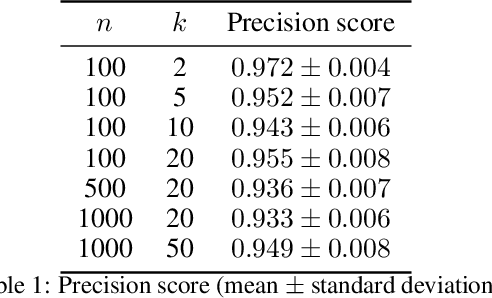
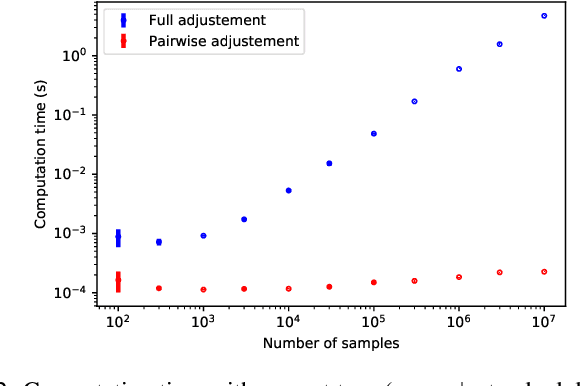
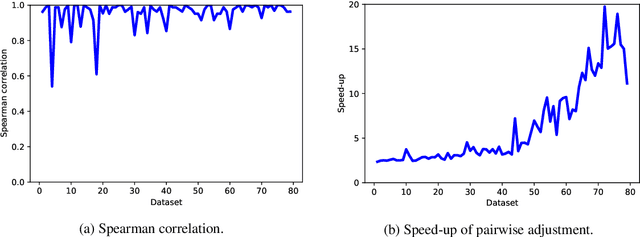
A well-known metric for quantifying the similarity between two clusterings is the adjusted mutual information. Compared to mutual information, a corrective term based on random permutations of the labels is introduced, preventing two clusterings being similar by chance. Unfortunately, this adjustment makes the metric computationally expensive. In this paper, we propose a novel adjustment based on {pairwise} label permutations instead of full label permutations. Specifically, we consider permutations where only two samples, selected uniformly at random, exchange their labels. We show that the corresponding adjusted metric, which can be expressed explicitly, behaves similarly to the standard adjusted mutual information for assessing the quality of a clustering, while having a much lower time complexity. Both metrics are compared in terms of quality and performance on experiments based on synthetic and real data.