 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Encoder for Learning Nearest Neighbors
Jun 25, 2023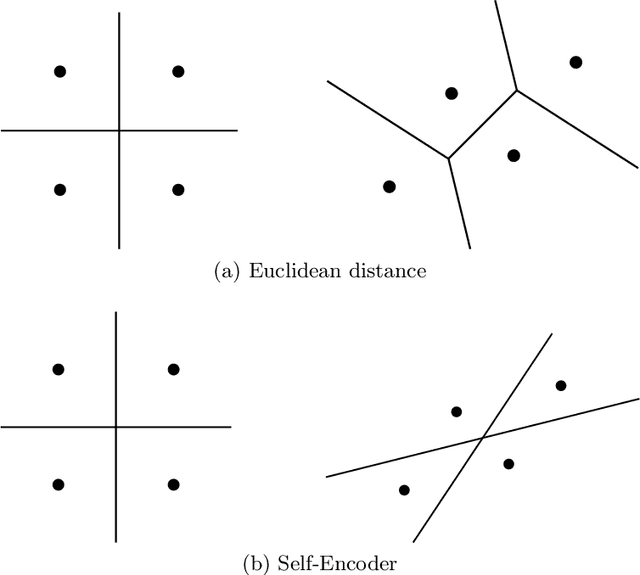
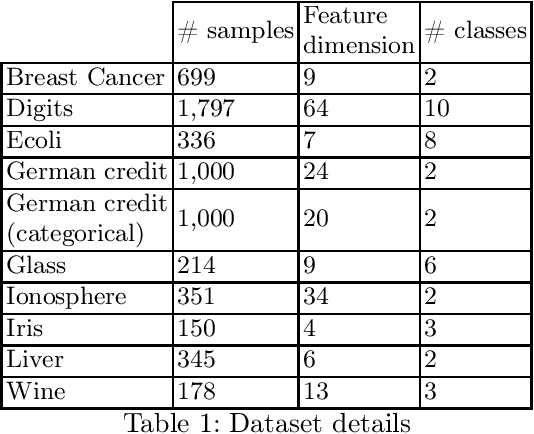
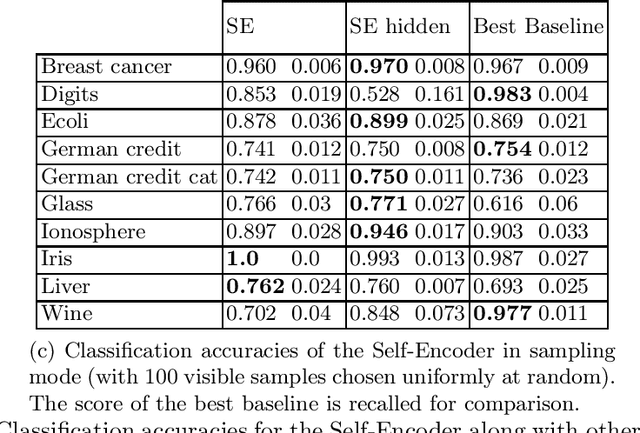
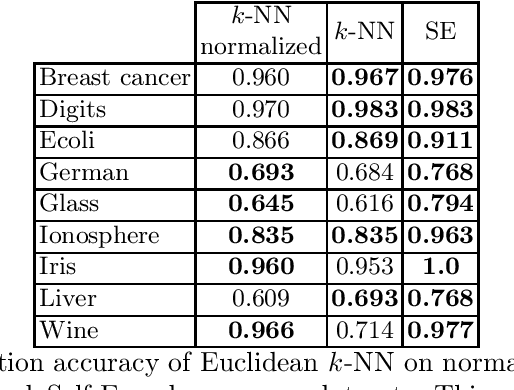
We present the self-encoder, a neural network trained to guess the identity of each data sample. Despite its simplicity, it learns a very useful representation of data, in a self-supervised way. Specifically, the self-encoder learns to distribute the data samples in the embedding space so that they are linearly separable from one another. This induces a geometry where two samples are close in the embedding space when they are not easy to differentiate. The self-encoder can then be combined with a nearest-neighbor classifier or regressor for any subsequent supervised task. Unlike regular nearest neighbors, the predictions resulting from this encoding of data are invariant to any scaling of features, making any preprocessing like min-max scaling not necessary. The experiments show the efficiency of the approach, especially on heterogeneous data mixing numerical features and categorical features.
TorchKGE: Knowledge Graph Embedding in Python and PyTorch
Sep 07, 2020

TorchKGE is a Python module for knowledge graph (KG) embedding relying solely on PyTorch. This package provides researchers and engineers with a clean and efficient API to design and test new models. It features a KG data structure, simple model interfaces and modules for negative sampling and model evaluation. Its main strength is a very fast evaluation module for the link prediction task, a central application of KG embedding. Various KG embedding models are also already implemented. Special attention has been paid to code efficiency and simplicity, documentation and API consistency. It is distributed using PyPI under BSD license. Source code and pointers to documentation and deployment can be found at https://github.com/torchkge-team/torchkge.
WikiDataSets : Standardized sub-graphs from WikiData
Jul 02, 2019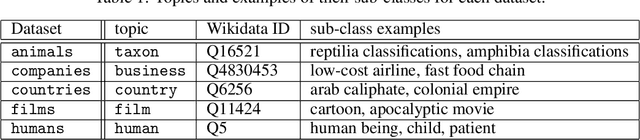
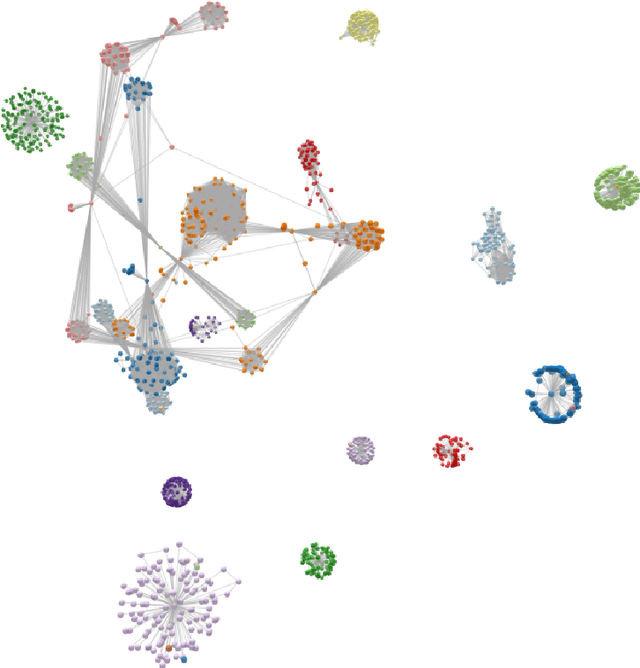
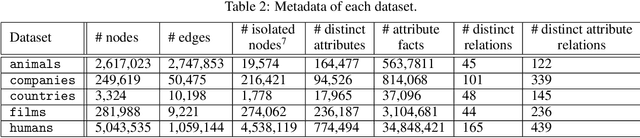
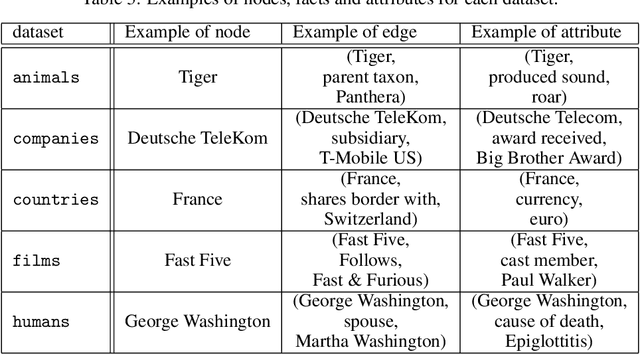
Developing new ideas and algorithms in the fields of graph processing and relational learning requires datasets to work with and WikiData is the largest open source knowledge graph involving more than fifty millions entities. It is larger than needed in many cases and even too large to be processed easily but it is still a goldmine of relevant facts and subgraphs. Using this graph is time consuming and prone to task specific tuning which can affect reproducibility of results. Providing a unified framework to extract topic-specific subgraphs solves this problem and allows researchers to evaluate algorithms on common datasets. This paper presents various topic-specific subgraphs of WikiData along with the generic Python code used to extract them. These datasets can help develop new methods of knowledge graph processing and relational learning.