 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Consistent Diffusion-Based Algorithm for Semi-Supervised Graph Learning
Nov 13, 2023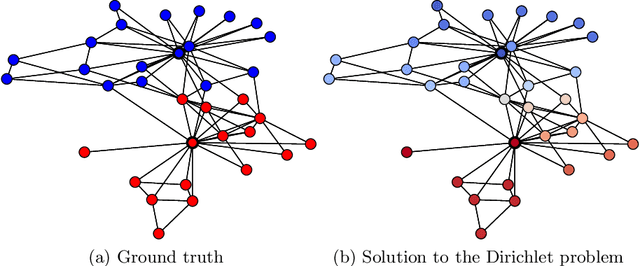
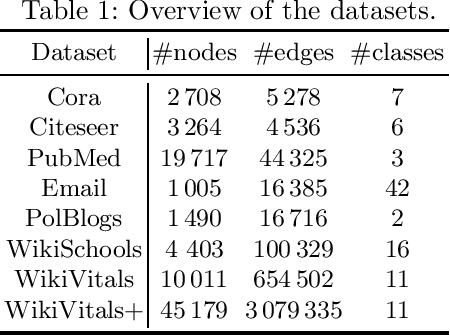
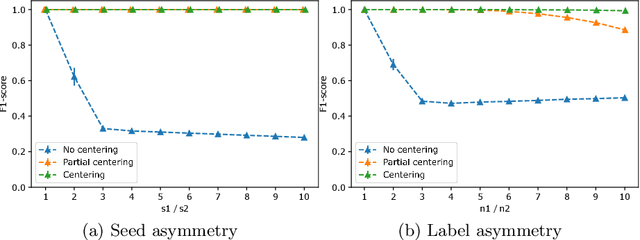
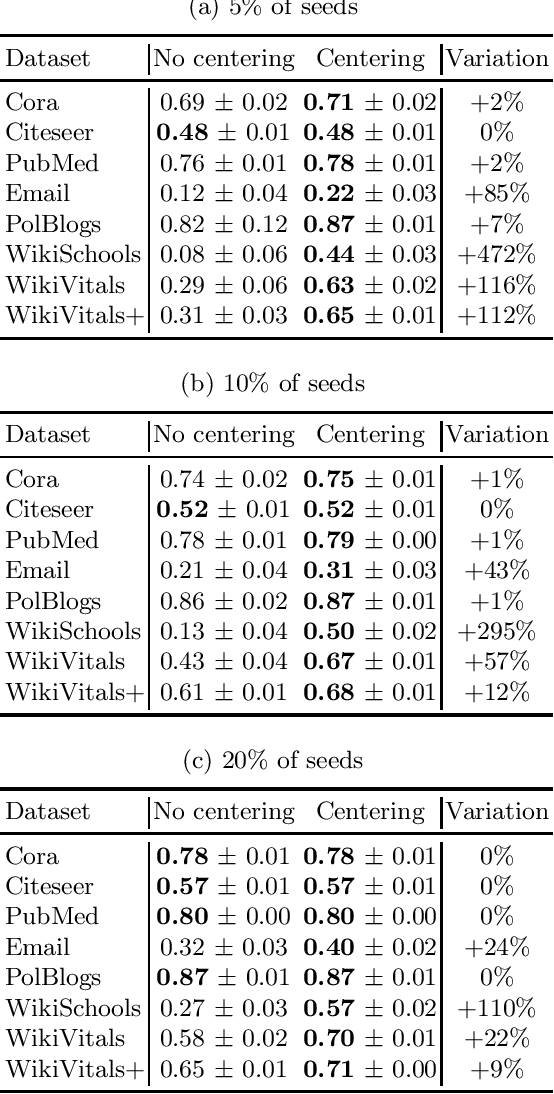
The task of semi-supervised classification aims at assigning labels to all nodes of a graph based on the labels known for a few nodes, called the seeds. One of the most popular algorithms relies on the principle of heat diffusion, where the labels of the seeds are spread by thermoconductance and the temperature of each node at equilibrium is used as a score function for each label. In this paper, we prove that this algorithm is not consistent unless the temperatures of the nodes at equilibrium are centered before scoring. This crucial step does not only make the algorithm provably consistent on a block model but brings significant performance gains on real graphs.
* arXiv admin note: substantial text overlap with arXiv:2008.11944
Towards Safe Mechanical Ventilation Treatment Using Deep Offline Reinforcement Learning
Oct 05, 2022Mechanical ventilation is a key form of life support for patients with pulmonary impairment. Healthcare workers are required to continuously adjust ventilator settings for each patient, a challenging and time consuming task. Hence, it would be beneficial to develop an automated decision support tool to optimize ventilation treatment. We present DeepVent, a Conservative Q-Learning (CQL) based offline Deep Reinforcement Learning (DRL) agent that learns to predict the optimal ventilator parameters for a patient to promote 90 day survival. We design a clinically relevant intermediate reward that encourages continuous improvement of the patient vitals as well as addresses the challenge of sparse reward in RL. We find that DeepVent recommends ventilation parameters within safe ranges, as outlined in recent clinical trials. The CQL algorithm offers additional safety by mitigating the overestimation of the value estimates of out-of-distribution states/actions. We evaluate our agent using Fitted Q Evaluation (FQE) and demonstrate that it outperforms physicians from the MIMIC-III dataset.
A Consistent Diffusion-Based Algorithm for Semi-Supervised Classification on Graphs
Aug 27, 2020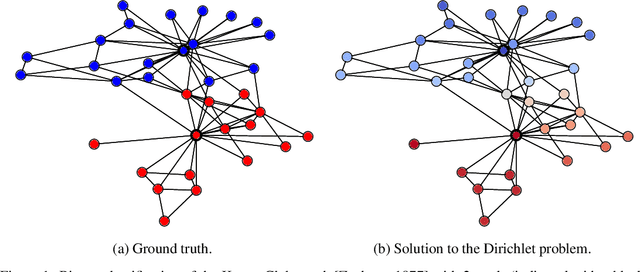
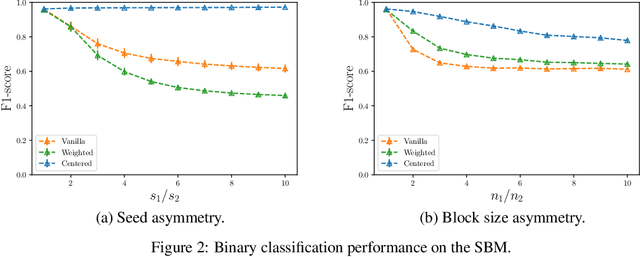

Semi-supervised classification on graphs aims at assigning labels to all nodes of a graph based on the labels known for a few nodes, called the seeds. The most popular algorithm relies on the principle of heat diffusion, where the labels of the seeds are spread by thermo-conductance and the temperature of each node is used as a score function for each label. Using a simple block model, we prove that this algorithm is not consistent unless the temperatures of the nodes are centered before classification. We show that this simple modification of the algorithm is enough to get significant performance gains on real data.
Spectral embedding of regularized block models
Dec 23, 2019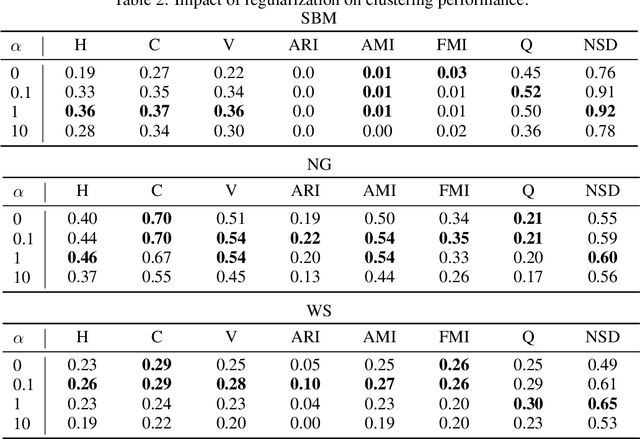
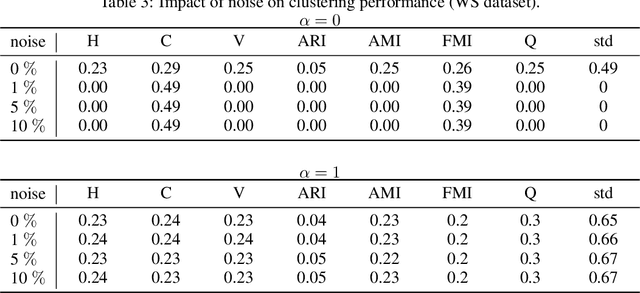
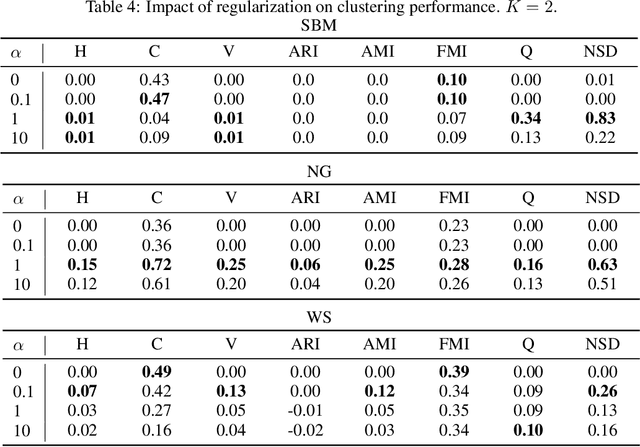
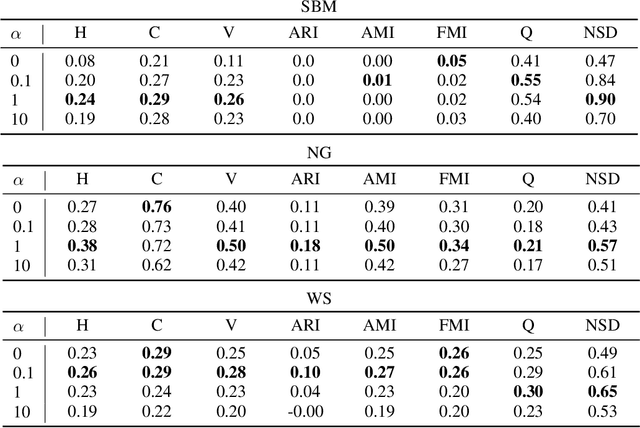
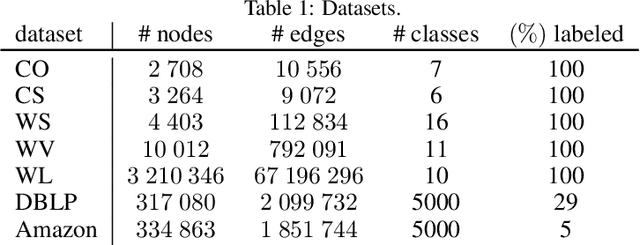
Spectral embedding is a popular technique for the representation of graph data. Several regularization techniques have been proposed to improve the quality of the embedding with respect to downstream tasks like clustering. In this paper, we explain on a simple block model the impact of the complete graph regularization, whereby a constant is added to all entries of the adjacency matrix. Specifically, we show that the regularization forces the spectral embedding to focus on the largest blocks, making the representation less sensitive to noise or outliers. We illustrate these results on both on both synthetic and real data, showing how regularization improves standard clustering scores.
Graph Classification with Recurrent Variational Neural Networks
Feb 14, 2019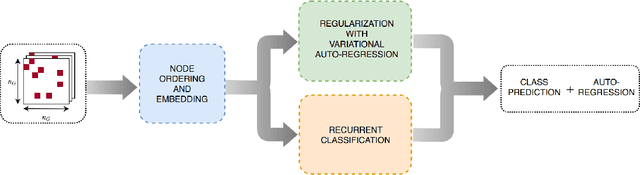
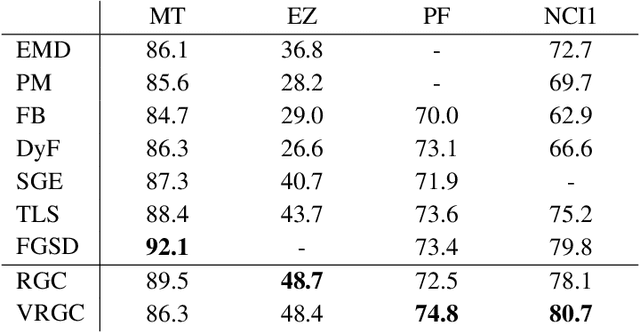
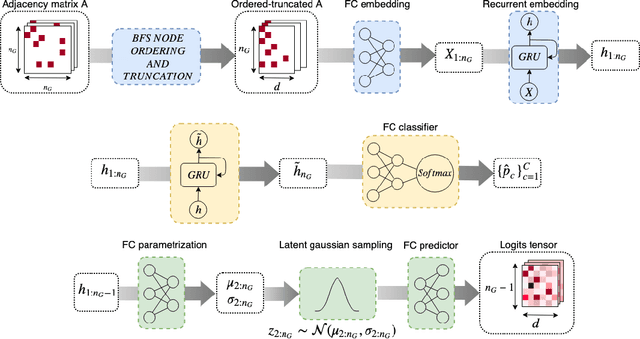
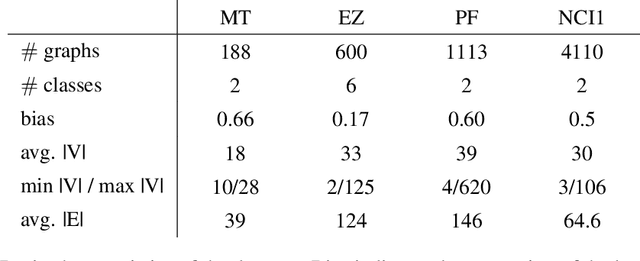
We address the problem of graph classification based only on structural information. Most standard methods require either the pairwise comparisons of all graphs in the dataset or the extraction of ad-hoc features to perform classification. Those methods respectively raise scalability issues when the number of samples in the dataset is large, and flexibility issues when discriminative information is characterized by exotic features. Recent advances in neural network architectures offer new possibilities for graph analysis in terms of scalability and feature learning. In this paper, we propose a new sequential approach using recurrent neural networks (RNN). Our model sequentially embeds information allowing to model final class membership probabilities. We also propose a regularization based on variational node prediction ending up with better learning and generalization. We experimentally show that our model reaches state-of-the-art classification results on several common molecular datasets. Finally, we perform a qualitative analysis and give some insights about how the joint node prediction helps the model to better classify graphs.
A Simple Baseline Algorithm for Graph Classification
Oct 22, 2018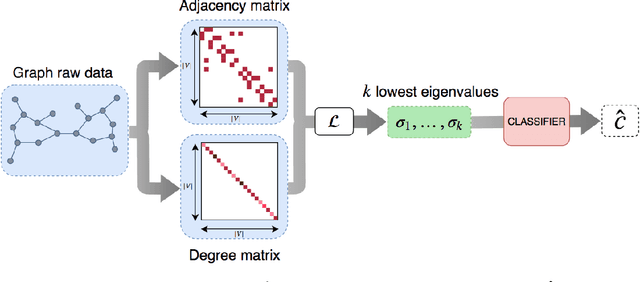
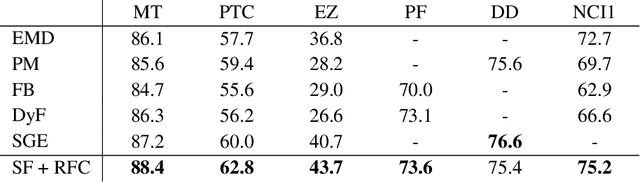
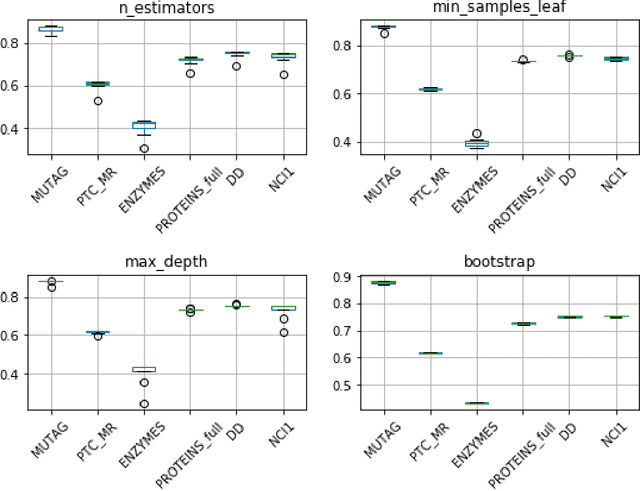
Graph classification has recently received a lot of attention from various fields of machine learning e.g. kernel methods, sequential modeling or graph embedding. All these approaches offer promising results with different respective strengths and weaknesses. However, most of them rely on complex mathematics and require heavy computational power to achieve their best performance. We propose a simple and fast algorithm based on the spectral decomposition of graph Laplacian to perform graph classification and get a first reference score for a dataset. We show that this method obtains competitive results compared to state-of-the-art algorithms.